First month for free!
Get started
Published 11/25/2025

Have you ever wondered how your phone’s voice assistant instantly gets what you're saying, or how live captions pop up on videos in real-time? That's AI audio-to-text technology at work, and it's quietly changing how we interact with the world around us. Simply put, it's the magic of using artificial intelligence to turn spoken words into written text.
This guide will break down how this tech went from a science-fiction concept to a practical tool that journalists, students, and businesses now rely on every single day. We'll get into everything from the nuts and bolts of how an AI "learns" to listen, all the way to the advanced features that make it so powerful. The goal is to show you how you can use it for your own projects and workflows.
This isn't just a niche trend; it's a massive shift, and the numbers back it up. The market for AI speech-to-text tools was valued at around $3.083 billion in 2024 and is expected to skyrocket to $36.91 billion by 2035. That's a compound annual growth rate of 25.32%, which points to just how quickly this technology is being adopted everywhere. You can discover more about these market trends and what they mean for the future of AI.
At its core, AI audio to text is all about unlocking the valuable information trapped inside our audio files. Think about it: every podcast, recorded meeting, or customer support call is like a locked treasure chest of data. Trying to transcribe that content by hand is painfully slow, costly, and often inaccurate.
AI is the key that unlocks that chest. It quickly and accurately turns all that spoken audio into text you can actually search, analyze, and use.
This single capability opens up a huge range of possibilities:
The real power of AI transcription isn't just turning sound into words. It's about making spoken information just as easy to search, use, and analyze as any written document.
This technology is weaving itself into the fabric of the tools we use daily, often so seamlessly we don't even realize it's there. It powers the voice-to-text feature on your smartphone, the live captions on your video calls, and the voice commands that control your smart home.
Now, dedicated platforms are making this powerful tech even easier for developers and companies to access. They can build their own voice-enabled apps and streamline workflows without needing a team of AI experts, bringing the power of voice to everyone.
So, how does an AI actually hear us and turn our words into text? It helps to think of it like teaching a child to understand and write down what they hear. It's not a single magic trick; it's a sophisticated process that takes raw soundwaves and methodically turns them into clean, structured sentences. The core technology driving all of this is called Automatic Speech Recognition (ASR).
The journey from a spoken word to a written transcript isn't instantaneous. It’s more like a finely tuned assembly line, with each station building on the work of the one before it to create the final product.
This diagram gives a great high-level view of the process: audio goes in, the AI brain does its work, and a text document comes out.
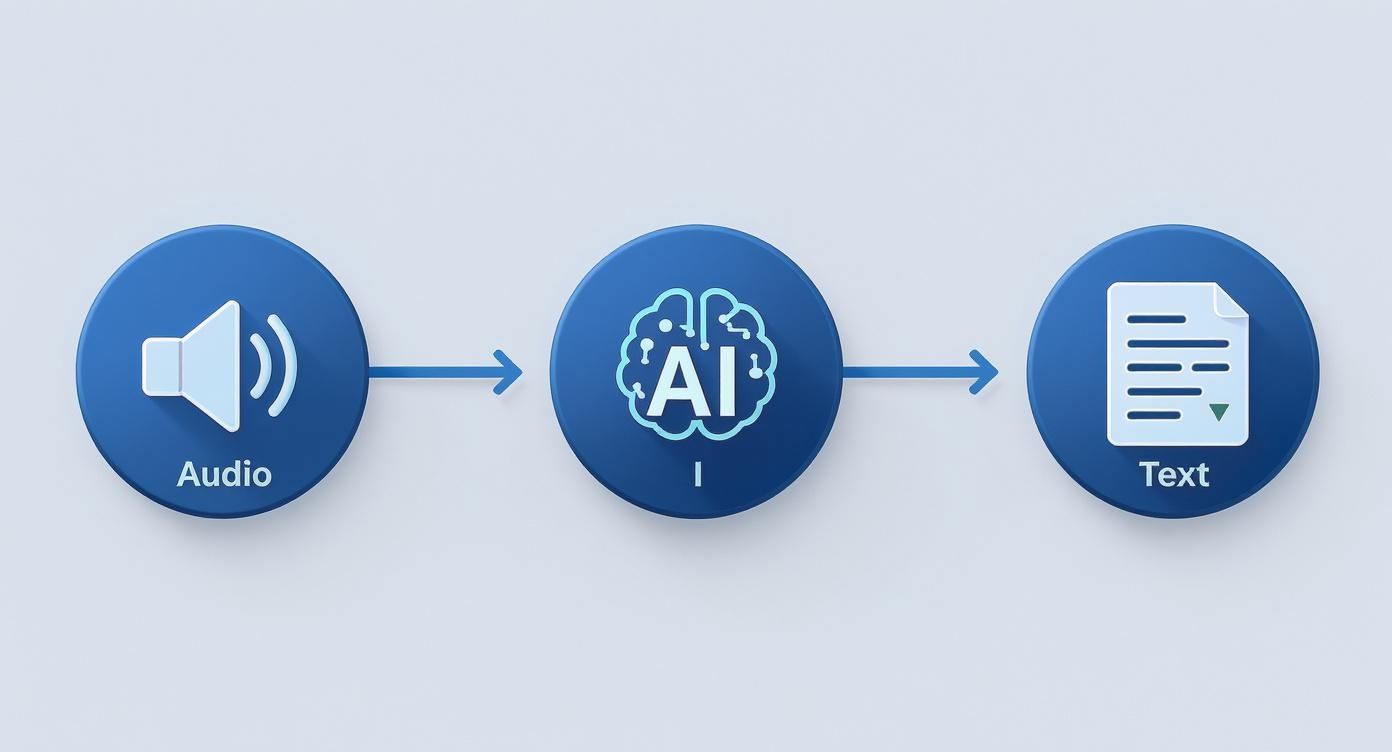
It’s a simple visual for a complex operation, but it perfectly shows how AI bridges the gap between unstructured sound and genuinely useful data. Let's pull back the curtain and look at the key components that make it all happen.
First up is the acoustic model. Think of it as a sound detective, whose only job is to analyze the incoming audio waveform. It meticulously breaks down that continuous stream of sound into its smallest building blocks: phonemes. For instance, it hears the word "cat" and immediately deconstructs it into three distinct phonemes: "k," "æ," and "t."
This model gets its skills from being trained on thousands upon thousands of hours of audio from countless speakers. This massive training data teaches it to map specific sound patterns to their corresponding phonemes. It's the essential first step that translates messy, real-world audio into a structured phonetic language the rest of the system can work with.
Once the acoustic model has done its job identifying the phonemes, the baton is passed to the language model. This is where the real "intelligence" kicks in. You can think of it as a predictive text engine, but on a whole other level. It analyzes sequences of phonemes and words to figure out what is most likely being said.
Here's a simple example. Let's say the acoustic model hears something that could be "ice cream" or "I scream." The language model uses context to make the right call.
This contextual awareness is what separates modern, high-quality transcription from the clunky, robotic systems of the past. Today's language models are often built using powerful deep learning architectures, like transformers, which gives them an incredible ability to grasp nuance, slang, and complicated sentence structures. They learn all this by digesting colossal datasets of text from books, articles, and the web.
An AI's ability to produce accurate text isn't just about hearing sounds correctly. It's about understanding the statistical probability of which words follow others, allowing it to solve ambiguities and reconstruct coherent sentences from a stream of sound.
The final piece of this puzzle is the decoder. It’s the ultimate decision-maker, bringing together the work of both the acoustic and language models. The acoustic model hands it a list of possible phoneme sequences based purely on sound, while the language model provides the statistical likelihood of different word combinations.
The decoder’s job is to sift through all these possibilities and find the single most likely path—the one that results in the most coherent and grammatically sound text. It uses complex search algorithms to navigate countless potential transcriptions and picks the one with the highest overall probability score. The result? The clean, accurate text you see on your screen.
Through this multi-stage process, an AI audio to text system does so much more than just recognize sounds. It uses a deep understanding of both phonetics and language to interpret what we say, turning spoken thoughts into incredibly useful written content.
Getting a raw block of text back from an audio file is one thing, but that’s just the starting point. The real magic of modern AI audio to text services lies in the features that add context, structure, and genuine usability to that text. These capabilities are what separate a basic tool from a professional-grade platform that delivers a polished, ready-to-use asset.
Without them, you’re stuck with a wall of words. Imagine sifting through a meeting recording without knowing who said what, or trying to find a specific quote without any time references. It’s a messy, manual process that the best services automate entirely.
One of the most powerful tools in the AI transcription toolbox is speaker diarization, sometimes called speaker recognition. It’s the technology that tackles the fundamental question: "Who is speaking, and when?"
Instead of spitting out one long monologue, the AI intelligently carves up the conversation. It assigns a unique label, like "Speaker 1" and "Speaker 2," to each person's dialogue. For a journalist transcribing an interview or a team reviewing a brainstorming session, this isn't just a nice-to-have; it's essential for making the transcript readable and easy to follow.
The system does this by creating a distinct "voiceprint" for each participant based on unique vocal characteristics like pitch, tone, and cadence. Once it knows who's who, it can accurately attribute every spoken word.
Another game-changer is precise timestamping. This feature tags every word—or at the very least, every paragraph—with its exact start and end time in the audio file. It might seem like a minor detail, but its impact on usability is enormous.
Timestamps effectively turn a static text document into an interactive, searchable resource. Need to double-check a specific quote or hear the original tone behind a comment? Just click the timestamp, and you're instantly synced to that exact moment in the audio.
This is indispensable for so many applications:
Accurate timestamping bridges the gap between the written text and its original audio source. It makes transcripts verifiable, interactive, and far more practical for detailed analysis or content editing.
But it doesn't stop there. Top-tier AI transcription services add layers of polish that make the text immediately usable. They automatically insert punctuation like commas and periods and apply proper capitalization, transforming a run-on stream of consciousness into clean, readable prose. Some of the more advanced systems can even detect and remove filler words—all the "ums" and "uhs"—for a tidier final transcript.
To help you decide which features are most important for your project, here’s a quick breakdown of the key advanced capabilities you'll find in modern transcription services.
| Feature | Description | Primary Use Case |
|---|---|---|
| Speaker Diarization | Identifies and labels different speakers in a multi-person conversation. | Meeting notes, interviews, panel discussions, and call center analytics. |
| Word-Level Timestamps | Assigns a start and end time to every single word in the transcript. | Subtitling, captioning, media editing, and detailed audio analysis. |
| Automatic Punctuation | Inserts commas, periods, and question marks to improve readability. | Generating ready-to-publish articles, meeting summaries, and reports. |
| Filler Word Removal | Automatically detects and omits filler words like "um," "uh," and "you know." | Creating clean, professional transcripts for podcasts, presentations, and public-facing content. |
| Real-Time Transcription | Transcribes audio into text live, with only a few seconds of delay. | Live captioning for webinars, accessibility tools for the hearing impaired, and real-time meeting notes. |
| Accent & Dialect Support | Accurately understands and transcribes speakers with diverse regional accents. | Global customer support, international market research, and multi-national team meetings. |
Understanding these features is key to picking the right tool. If you're just transcribing a solo podcast, filler word removal might be your top priority. But for a team meeting, speaker diarization is non-negotiable.
Finally, real-time transcription is a game-changer for live events and communication. It processes audio as it’s happening, generating a live text stream with minimal latency. This is the technology that powers live captions on a webinar, provides accessibility tools for virtual meetings, and enables instant note-taking during conference calls, making information accessible to everyone the moment it's spoken.
The real magic of AI audio to text isn't buried in complex code; it's in the everyday problems it solves. Across dozens of industries, people are using automated transcription to simplify their work, find hidden insights, and just make things better for their customers. This is where the theory hits the road, turning spoken words into a truly useful asset.
From media production houses to medical clinics, the applications are as varied as they are powerful. Each sector is discovering its own ways to transform audio into actionable information, and it's changing how they get things done.

If you're a journalist, podcaster, or video producer, you know that time is your most precious resource. Slogging through a manual transcription of a one-hour interview can easily eat up four or five hours. That's a huge bottleneck. AI transcription shrinks that down to just a few minutes.
This incredible speed lets creators:
In the world of customer service, understanding what your customers are saying is everything. This is where AI transcription, often integrated with call center call monitoring software, really shines. By turning thousands of support calls into text, companies can finally analyze conversations at scale.
This data helps them pinpoint common customer frustrations, check in on agent performance, and spot trends in customer sentiment. It's like unlocking a treasure chest of feedback that was previously too time-consuming and expensive to get to.
By analyzing transcribed conversations, a business can move from reactive problem-solving to proactive strategy, understanding what customers need before they even have to ask.
AI audio to text is also making a huge difference in education. It gives students accurate, searchable notes from lectures and seminars, which is a game-changer for anyone with a learning disability or for those learning in a second language.
This technology ensures that no one misses out on crucial information and gives everyone the chance to review complex ideas at their own pace. The transcript essentially becomes a personalized study guide, making exam prep much more effective.
One of the most significant impacts of AI transcription is happening in healthcare. Doctors and nurses spend an enormous amount of time on administrative work, especially updating clinical notes. AI is a huge help here.
Now, a physician can simply dictate their patient notes, and the AI will convert their speech into neatly formatted text ready for the electronic health record (EHR). This not only frees up a doctor's time and reduces burnout but, most importantly, allows them to focus more on caring for their patients. The growth in this space is massive—the global AI transcription market is projected to hit $19.2 billion by 2034, and the healthcare sector is a huge part of that story.
Picking the right AI audio to text service can feel overwhelming. With so many companies all promising the best results, it's tough to know who to trust. The secret is to look past the marketing hype and focus on what really matters for your specific project.
A cheap service that gets everything wrong is just a waste of money, but an expensive one might be loaded with features you'll never touch. This guide will help you cut through the noise and zero in on a partner that genuinely fits your goals.
Before you even glance at a pricing page, the first step is to figure out what you actually need. What are your absolute must-haves? Knowing your primary use case will instantly help you filter out the options that won’t work.
Start by asking yourself a few simple questions:
Your answers become your personal checklist. This makes sure you’re choosing the right service for your workflow, not just the most popular one.
Once you have your checklist, you can start comparing providers. When looking at transcription partners and what they offer, you might want to check out services like Parakeet AI to see how they stack up.
Here are the critical factors to dig into.
1. Accuracy and Word Error Rate (WER)
This is, without a doubt, the most important metric. Accuracy is usually measured by Word Error Rate (WER), which is just the percentage of words the AI messes up. A lower WER is always better. The best services can get this number below 5% under good audio conditions.
2. Speed and Latency
How fast do you need the text? If you’re just transcribing a recording, waiting a few minutes for the file to process is perfectly fine. But if you're doing live captioning for a webinar, low latency—the tiny delay between when someone speaks and when the text appears—is everything.
3. Pricing Models
You’ll find a few different ways to pay. Some services charge by the minute or hour of audio, which is perfect if you only need transcriptions now and then. Others use monthly subscriptions with a fixed number of hours, which often provides much better value if you're a heavy user.
4. Language and Dialect Support
This is a make-or-break factor if your audio isn't in standard English. Make sure any provider you consider not only supports the languages you need but can also handle the nuances of different regional accents and dialects without stumbling.
Data privacy isn't just a feature; it's a foundation of trust. For any business handling sensitive information, understanding how a provider manages, secures, and deletes your data is non-negotiable.
In a world full of data breaches, security can't be an afterthought. When you upload an audio file, you're handing over your information. That’s a big deal, especially if that audio contains private customer details, confidential business plans, or any other sensitive material.
Always gravitate towards services that are upfront and transparent about how they handle your data. For example, Lemonfox.ai makes this a priority by offering an EU-based API to meet strict GDPR rules and guaranteeing that user data is deleted right after it’s processed. That level of commitment shows you’re working with a partner you can trust.
This screenshot from the Lemonfox.ai homepage puts key information like pricing and features front and center. By being so clear about cost-effectiveness and capabilities, they help potential users quickly see if the service is a good fit, which simplifies the whole decision-making process.
Diving into AI audio to text for the first time usually brings up a few key questions. It's a powerful and fast-moving field, so it’s only natural to wonder about how well it works, how safe your data is, and what it can realistically do for you.
Think of this section as a straightforward conversation where we tackle the most common things people ask. We'll clear up any confusion around accuracy, security, languages, and developer integration, so you can feel confident choosing a service or building out your next big idea.
This is almost always the first question, and for good reason. If the transcription is full of errors, it's not very useful. The great news is that today's top-tier AI models have become incredibly good at this.
Under ideal conditions—think of a clean audio recording with one person speaking and no background noise—the best systems can hit accuracy rates well over 95%. This works out to a Word Error Rate (WER) of less than 5%, meaning fewer than five mistakes for every 100 words spoken. That's more than accurate enough for most professional needs, from captioning videos to documenting important meetings.
Of course, the real world is rarely perfect. A few things can throw a wrench in the works:
The leading services get around these problems by training their models on huge, diverse audio libraries. This exposure helps the AI learn to navigate different speakers, noisy environments, and complex topics, keeping accuracy high even when the audio isn't studio-quality.
Data security is a huge deal, especially when you're working with sensitive audio from business meetings, medical consultations, or private interviews. Handing over a file to a third-party service means trusting them with your data, so you absolutely have to know how they’re protecting it.
Any reputable provider will put data privacy front and center. They use strong security measures to protect your information from the moment you upload it. This almost always includes end-to-end encryption, which scrambles your data while it's in transit to their servers and keeps it encrypted while it's stored.
When you're picking an AI audio partner, their data privacy policy is just as important as their accuracy rate. Always double-check that a service meets your security standards before you upload anything sensitive.
For anyone doing business in Europe, GDPR compliance is a must. A provider with a dedicated EU API is a game-changer, as it guarantees your data is processed and stored within the EU, under its strict privacy laws. Also, look for a clear data deletion policy. The best platforms, like Lemonfox.ai, automatically and permanently delete your data right after processing. Your information never sits around on their servers.
Absolutely. This is where modern AI audio to text technology has made some of its biggest leaps. The old, clunky, English-only systems are a thing of the past. Today's models are truly global.
The best platforms can often handle over 100 different languages, from global ones like Spanish and Mandarin to many others. They achieve this by training the AI on massive datasets filled with audio from native speakers all over the world.
This training goes beyond just vocabulary and grammar; it teaches the AI to understand the nuances of how people actually speak. It learns to recognize and accurately transcribe countless regional accents and dialects. For instance, a good model can easily tell the difference between American, British, and Australian English, or between the Spanish spoken in Spain and in Latin America. This is a critical feature for any company with an international footprint.
The good news is you don't need a PhD in machine learning to add transcription to your software. Most services are built for developers and offer a simple integration path through an Application Programming Interface (API).
An API is basically a bridge that lets your app talk to the transcription service. It’s a clean and simple way to send audio and get text back. Here’s a quick rundown of how it usually works:
Providers usually give you everything you need to get started, including detailed documentation, code snippets in popular languages like Python or JavaScript, and developer support. This makes it possible for businesses of any size to build custom tools, from an internal app that summarizes Zoom calls to a public-facing product with voice commands.
Ready to see what a fast, accurate, and secure AI audio to text API can do for your projects? With Lemonfox.ai, you can transcribe audio for less than $0.17 per hour in over 100 languages. Start your free trial today and get 30 hours of transcription to test our powerful features. Get started with Lemonfox.ai.