First month for free!
Get started
Published 1/16/2026
At its core, AI noise reduction is about teaching a machine to do what the human brain does almost instinctively: separate the important sounds (like speech) from the unimportant ones (like background noise). Using advanced algorithms, the technology analyzes sound waves in real time to isolate and filter out distractions, leaving you with crystal-clear audio.
This isn't just a niche feature anymore. It’s become a critical component for everything from remote work and content creation to making speech-to-text systems dramatically more accurate. Think of it as a digital scalpel, surgically removing unwanted noise from an audio signal.
We’ve all been there. You're trying to lead an important call, and suddenly a dog decides to join the conversation. Or you're tuning into a podcast, but a persistent hum in the background makes it impossible to focus. These audio hiccups are more than just a minor annoyance; they shatter concentration and can make vital information completely incomprehensible.
For developers building products that depend on audio, poor quality is a fast track to user frustration. In the past, cleaning up messy audio was a tedious, manual process requiring specialized software. Today, AI noise reduction acts like a seasoned audio engineer working at lightning speed, instantly untangling the human voice from the surrounding chaos.
This technology has moved from a "nice-to-have" to a foundational requirement for modern applications. The need for pristine audio is everywhere you look:
The demand is exploding. The global Background Noise Reduction Software Market is on track to grow from USD 3.21 billion in 2026 to an incredible USD 45.02 billion by 2034. You can explore more about this market's rapid growth.
This guide is your roadmap, taking you from the basic concepts right through to practical implementation. We’ll break down the core AI models that make this possible, walk through data preparation, and show you how to integrate these solutions to build better, clearer audio experiences. Consider this your developer-focused playbook for finally conquering the problem of background noise.
To really get a feel for how AI noise reduction works, you have to look under the hood. It’s not one single magic bullet; it’s more like a toolkit of specialized engines, each designed to tackle the problem of separating a clean voice from distracting background sounds in a slightly different way. The journey starts with some foundational techniques and ramps up to the sophisticated deep learning models we see today.
The progress here has been pretty staggering. Modern AI-driven audio noise reduction systems are hitting 92-97% accuracy in pulling speech out of a noisy environment. This isn't just a technical achievement—it's driving a market that was valued at USD 563 million in 2024 and is expected to climb to USD 961 million by 2032.
One of the oldest tricks in the book is Spectral Subtraction. Think about being in a room with a loud, humming air conditioner. After a minute, your brain just starts to tune it out so you can focus on the person you're talking to. Spectral Subtraction is the digital version of that.
It’s a pretty straightforward, two-step process:
This method works great for steady, consistent sounds—think fan hums, machine whirs, or static. But it falls apart when faced with sudden, unpredictable noises like a dog barking or a car horn, because those sounds don't have a stable fingerprint it can lock onto and remove.
This is where modern AI really starts to show its power. Instead of just subtracting a simple pattern, Deep Neural Networks (DNNs) learn to recognize the incredibly complex differences between human speech and everything else.
A DNN is like a seasoned audio engineer who has listened to thousands of hours of recordings. It intuitively knows the difference between the subtle frequencies of a human voice and the chaotic mess of a busy café, even if it's never heard that specific café before.
By training on massive datasets filled with both clean and noisy audio, a DNN builds an internal model of what "speech" sounds like versus what "noise" sounds like. When new audio comes in, it uses that learned knowledge to predict and isolate the speech signal while tossing the rest. This makes it incredibly effective at handling the tricky, non-stationary noises that older methods just couldn’t touch.
As powerful as they are, full-blown DNNs can be resource hogs. Running a big model for real-time noise reduction on a phone or laptop can kill the battery and create noticeable lag. That’s exactly the problem RNNoise was built to solve.
Developed by Mozilla, RNNoise is a specialized type of recurrent neural network (RNN) that cleverly blends classic signal processing with deep learning. It's heavily optimized for high performance on low-power devices, making it perfect for things like video calls and live transcription. Think of it as a lean, mean version of a DNN, specifically engineered for the demands of real-time audio without needing a beast of a server to run on.
Maybe the most elegant approach is the Denoising Autoencoder. This model acts less like a filter and more like a skilled artist restoring a damaged painting. It learns how to reconstruct pristine audio from a corrupted, noisy version.
Here’s the basic idea:
This technique is fantastic for handling all sorts of noise and can even patch up small gaps where the original speech was completely drowned out. For a broader look at how artificial intelligence is changing the audio world, it's worth exploring other AI editing technologies.
To help you decide which approach might be right for your project, let’s break them down side-by-side.
Each of these models offers a unique tool for developers. This table gives you a quick rundown of their core principles, strengths, and weaknesses to help you choose the right one for the job.
| Technique | Core Principle | Best For | Key Limitation |
|---|---|---|---|
| Spectral Subtraction | Captures a "noise profile" from a quiet segment and subtracts it from the entire audio signal. | Stationary, consistent noise like fan hums, static, or machine whirs. | Poor performance with dynamic, unpredictable sounds (e.g., talking, sirens). |
| Deep Neural Networks (DNNs) | Learns the distinct patterns of speech vs. noise from vast datasets to predict and isolate the voice. | Complex, non-stationary noise found in real-world environments like cafes or traffic. | Can be computationally expensive, making real-time use on-device a challenge. |
| RNNoise | A hybrid recurrent neural network optimized for low computational overhead. | Real-time, on-device applications like VoIP, video conferencing, and live captioning. | Less powerful than larger DNNs for extremely noisy or unusual audio scenarios. |
| Denoising Autoencoders | Learns to reconstruct clean audio from a compressed, noisy version, effectively "redrawing" the signal. | General-purpose noise removal and restoring audio where speech is partially obscured. | Can sometimes introduce minor artifacts during the reconstruction process. |
Ultimately, the best technique depends entirely on your specific needs—whether you prioritize real-time performance, the ability to handle chaotic environments, or pure reconstruction quality.
Any AI model is only as good as the data it’s trained on. For AI noise reduction, this is the absolute truth. The success of your model rests almost entirely on the quality and sheer variety of the audio you feed it. Getting this foundational step right is what separates a model that works in the lab from one that can handle the messy, unpredictable audio of the real world.
Think of it like teaching a musician to pick out a melody in a symphony. If they only ever hear a solo violin, they’ll be completely lost when that same melody is played amidst a hundred other instruments. Your model is the same; it needs massive exposure to all kinds of sounds to learn what’s speech and what’s just noise.
The game here is to build a massive audio library. This isn't just about grabbing clean speech recordings. It's about finding that pristine audio and then pairing it with an equally diverse collection of background noise. The model has to learn from both sides of the coin—what to keep and what to throw away.
Essentially, your dataset will be a mix of two key ingredients:
Once you have these two piles of audio, the magic happens in the mixing. You'll take a clean speech sample and digitally overlay it with a random noise sample at different signal-to-noise ratios. This technique lets you artificially create thousands of unique training examples from a relatively small set of core recordings, teaching the model how to pull a voice out of countless different messy situations.
Data annotation for noise reduction is all about creating perfect pairs of files: a noisy version and its corresponding squeaky-clean "ground truth" version. The model learns by constantly comparing its own denoised output to that clean target. Over and over, it adjusts its parameters to close the gap between its attempt and the perfect version.
Meticulous annotation is completely non-negotiable. If the alignment between your noisy and clean audio pairs is off by even a few milliseconds, you're giving the model bad instructions. It’s like teaching someone to drive with a misaligned steering wheel—it just won't work and will seriously degrade performance.
This is where you see different approaches to solving the problem, from classic signal processing to more sophisticated deep learning architectures.
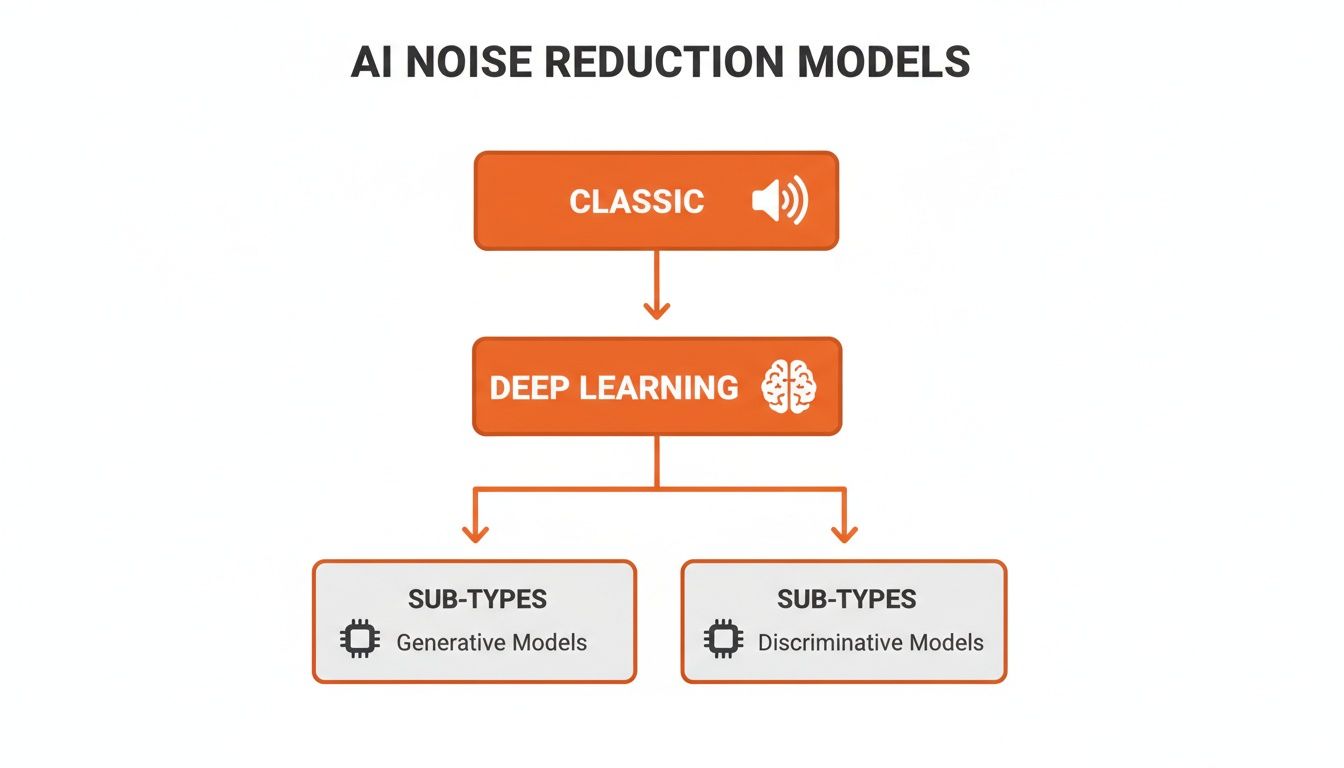
As this diagram shows, there’s been a clear evolution. Modern deep learning methods have branched out into highly specialized models built for specific jobs, like real-time cancellation or high-fidelity audio restoration.
Before any of your data gets near the model, it needs to be prepped. This preprocessing pipeline is all about cleaning, standardizing, and transforming raw audio into a format the model can actually work with. It ensures consistency and helps extract the most important information.
A typical pipeline involves a few critical stages:
This careful, step-by-step preparation is what turns a messy pile of audio files into a high-octane learning resource for an effective AI noise reduction model.
So, you’ve built and trained an AI noise reduction model. How do you actually prove it's working? You could just listen to it, and while there's a place for that, relying on "it sounds better" isn't a scalable or objective way to judge performance. As developers and engineers, we need hard numbers to quantify improvements, steer development, and avoid a classic mistake—over-processing the audio.
This is where objective evaluation metrics are absolutely essential. Think of them as the unit tests for your audio quality. These are standardized algorithms that analyze an audio file and spit out a score for its quality, clarity, and intelligibility. They give you the concrete data you need to compare different models, tweak your parameters, and make sure your noise reduction is truly helping, not accidentally making things worse.
Without these metrics, it's easy to fall into the trap of aggressive noise removal that creates weird, unnatural artifacts or muffles the very speech you’re trying to save. Metrics keep you honest and on the right track.
There are a few industry-standard metrics that everyone in speech enhancement uses. Each one looks at a slightly different piece of the puzzle, and together, they give you a complete picture of how your model is performing.
Signal-to-Noise Ratio (SNR): This is the old standby. It’s a straightforward measurement of the power ratio between the speech you want and the background noise you don’t. A higher SNR means a cleaner signal. It’s a great starting point, but it doesn't always line up with what a human listener would consider "good quality."
Perceptual Evaluation of Speech Quality (PESQ): This one gets a bit more sophisticated. It tries to predict how a human would actually rate the audio. It compares your processed audio to the original clean version and gives you a score from -0.5 to 4.5. The higher the PESQ score, the more natural and pleasant the audio is likely to sound to a real person.
Short-Time Objective Intelligibility (STOI): While PESQ is about overall quality, STOI is all about one thing: can you understand the words? It scores your audio between 0 and 1, where a higher value means the speech is clearer and easier to follow. For anything related to transcription, this metric is your best friend.
By looking at all three metrics together, you get a much more balanced view. You can see if you're actually reducing noise (SNR), if the result still sounds human (PESQ), and if the words are still easy to understand (STOI).
One of the biggest dangers in this field is getting too aggressive with noise reduction. It’s easy to build a model that wipes out nearly all background sound and gets a fantastic SNR score. The problem is, that same model might make the speaker's voice sound robotic or introduce strange digital artifacts.
This is where having multiple metrics saves you.
You might see a model’s SNR score jump up, but at the same time, its PESQ score might take a nosedive. That’s a huge red flag. It’s telling you that, yes, the noise is gone, but you've damaged the actual speech in the process. The real goal is to find that sweet spot where noise is cut way down, but your PESQ and STOI scores stay as high as possible. This balanced approach ensures you're delivering audio that's not just cleaner, but also clearer and genuinely better to listen to.
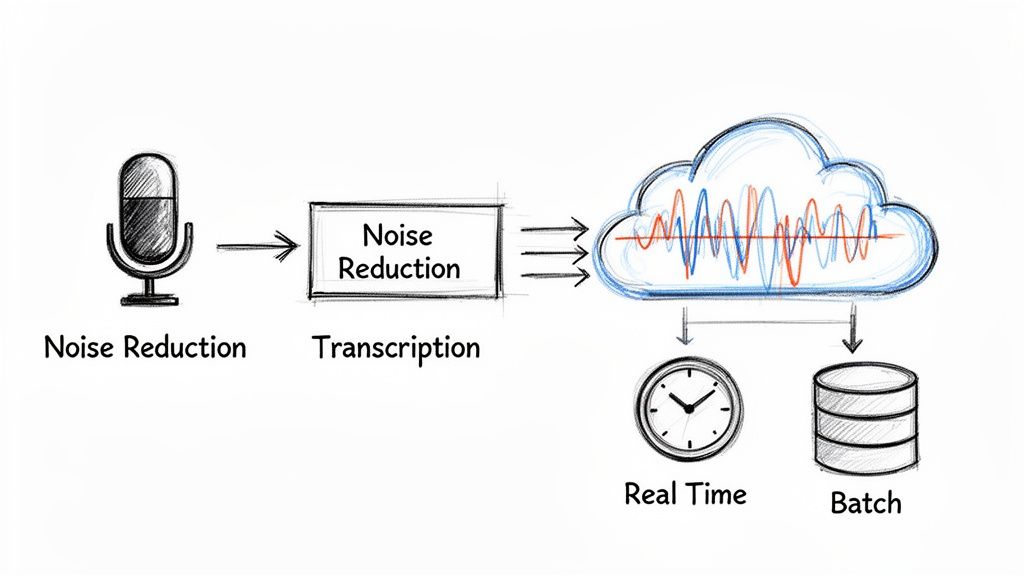
This is where all the theory pays off. Integrating AI noise reduction isn't just a matter of plugging in a model; it's about designing a smarter audio pipeline to get the best possible transcription accuracy. The most important rule? The noise reduction step always comes before the transcription engine.
Think about it this way: feeding a speech-to-text (STT) model raw, noisy audio is like asking someone to transcribe a conversation happening next to a running blender. Even the most advanced transcription models will stumble, leading to mistakes, missed words, and low confidence scores.
By cleaning the audio first, you're handing the STT engine a crystal-clear signal. This simple pre-processing step is the single most effective thing you can do to make your entire transcription workflow more reliable, turning garbled recordings into accurate text.
How you build your system really boils down to what your application needs to do. The architecture for live captioning, for instance, looks completely different from one built to process a library of old podcast episodes. It’s all about the trade-off between latency and throughput.
This architecture is all about speed. It’s a must-have for any application where people need to see the text almost instantly, like live meeting captions, voice commands, or subtitles for a live stream.
Here, the focus shifts from speed to efficiency at scale. This approach is perfect for jobs like transcribing recorded interviews, university lectures, or a backlog of call center recordings where you don't need the results this very second.
By picking the right architecture, you're making sure your tech aligns with what your users actually expect. This choice shapes everything that follows, from the models you select to your infrastructure costs and how you plan for growth.
Let’s be honest: building, training, and maintaining both a state-of-the-art noise reduction model and a world-class transcription engine is a massive undertaking. This is where leaning on a dedicated, high-performance STT API like Lemonfox.ai becomes a smart, strategic move.
When you integrate with a specialized API, you get to offload all the heavy lifting of transcription. Your team can focus its energy on what it does best: building a great user-facing application and perfecting that crucial noise-reduction pre-processing step.
This modular approach makes your architecture so much simpler. Your system has one job: deliver the cleanest audio possible to an API that is expertly tuned for one thing—turning speech into text. This separation of duties results in a product that's more robust, easier to scale, and simpler to maintain.
The market for these audio tools is booming. Since its early days, AI Noise Suppression has evolved to target and eliminate specific sounds like keyboard clicks and room echo from calls. It’s no surprise that the noise suppression components market is projected to jump from USD 28.33 billion in 2025 to a staggering USD 86.33 billion by 2034.
Of course, it’s not always straightforward. You have to be aware of potential pitfalls, like the noise reduction paradox, where filtering too aggressively can actually muddle the speech. This is precisely why the winning combination is a well-balanced noise reduction model followed by a top-tier STT engine.
Ultimately, putting AI noise reduction before transcription acts as a force multiplier for accuracy. You’re building your entire application on a foundation of clean audio, giving you the best possible shot at getting flawless results, every single time.
When you start digging into audio enhancement, a few questions always seem to pop up. It's totally normal. Getting a handle on how these technologies differ and what you can realistically expect is the first step to a successful project. Let's clear up some of the most common sticking points around AI noise reduction.
So, what’s the real difference between noise reduction and noise cancellation? They sound almost interchangeable, but under the hood, they’re two completely different beasts.
Active Noise Cancellation (ANC) is all about hardware. Think of your favorite noise-canceling headphones. They have tiny microphones that listen to the world around you and instantly create an "anti-noise" sound wave. This new wave physically cancels out the incoming ambient sound before it ever hits your eardrum. It's a clever bit of physics in action.
AI noise reduction, on the other hand, is pure software. It takes the digital audio signal, runs it through a smart algorithm, and surgically separates the human voice from everything else. It doesn't block the noise; it digitally identifies and removes it from the recording. It's less like building a soundproof wall and more like having a brilliant audio editor clean up the track in real-time.
This is the big one: can an AI really scrub out any background noise? Well, while today's models are incredibly powerful, they aren't magic. A model is only as good as the data it was trained on.
The real goal of AI noise reduction isn't to create a vacuum of perfect silence. It's to achieve maximum clarity. If you get too aggressive with the filtering, you can start to warp the voice itself, leaving it sounding thin, robotic, or full of weird artifacts. The best systems find that sweet spot: removing as much distracting noise as possible without damaging the original speech.
Okay, so how much computing muscle does real-time noise reduction actually need? This really depends on the complexity of the model you're using.
Simpler, more traditional algorithms are pretty lightweight and can run on just about any device without breaking a sweat. But the deep learning models that produce truly top-tier results? Those can be hungry for processing power, especially when you need them to work instantly in a live application.
This exact problem is why specialized models like RNNoise were developed—they're engineered to be incredibly efficient for on-device processing without killing the battery. For the most powerful and accurate models, though, the heavy lifting is often best offloaded to a server. This is precisely why a cloud-based API is often the smartest move for developers. You get access to state-of-the-art performance without having to manage the complex and costly infrastructure yourself.
Ready to integrate flawless audio processing into your application? With Lemonfox.ai, you can tap into a powerful, affordable, and developer-friendly Speech-to-Text API that thrives on clean audio. Start building with our free trial and see the difference pristine audio makes. Explore the Lemonfox.ai API to get started.