First month for free!
Get started
Published 12/1/2025

Ever wonder how your phone understands you when you ask for the weather? It might feel like magic, but what's really at work is a technology called Automatic Speech Recognition (ASR).
This isn't some futuristic concept; it's already woven into the tools we use every day, from the smart speaker on your counter to the navigation system in your car. At its core, ASR tackles one fundamental challenge: turning the messy, complex, and nuanced waves of human speech into clean, structured text that a computer can actually work with.
The journey from a spoken command to words on a screen is a fascinating one, and it all begins with a simple sound wave.
When you speak, you create vibrations in the air. A microphone—whether in your phone, laptop, or headset—captures these vibrations and converts the analog sound waves into a digital signal. Think of it like a musician recording a guitar riff on a computer; your voice becomes a long stream of numbers that represents its unique frequencies and amplitudes.
This diagram gives a great high-level view of how an ASR system processes those sound waves.
As you can see, the raw audio is first turned into a spectrogram, which is just a visual map of the sound's frequencies over time. An acoustic model then chews on this visual data to pick out phonetic sounds, which a language model then assembles into words and sentences that make sense.
Once the audio is digitized, the real heavy lifting for the automatic speech recognition models begins. The system slices that digital signal into tiny, manageable chunks, usually just a few hundredths of a second long.
Each little piece is analyzed to identify its distinct phonetic properties—the basic building blocks of speech. From there, the model uses complex statistical algorithms to figure out the most probable sequence of words that these sounds represent. It's less about "hearing" and more about predicting.
At its heart, an ASR model is a probability engine. It’s constantly asking, "Given this specific sound, what's the most likely word or phrase the speaker just said?" That predictive power is what makes accurate transcription possible.
This technology has come a long way. The journey started back in 1952 when Bell Laboratories unveiled "AUDREY," a system that could recognize spoken digits with an impressive 90% accuracy. The catch? It only worked for the person who invented it, a classic example of early speaker-dependent systems. You can read more about the fascinating history of ASR on the US Legal Support blog.
To really get a handle on how good today's transcription is, it helps to look back at the journey of automatic speech recognition models. We didn't just jump from clunky, robotic systems to the seamless voice assistants we use today. It was a slow, steady evolution, with each new approach building on the lessons of the last.
This progression marks a fundamental shift in how we taught machines to understand us. We moved from rigid, rule-based systems to incredibly flexible ones that learn directly from data. Every generation of ASR models solved key problems and unlocked new possibilities.
At its core, ASR is all about turning a physical sound wave into digital text. It’s a pretty complex translation job.
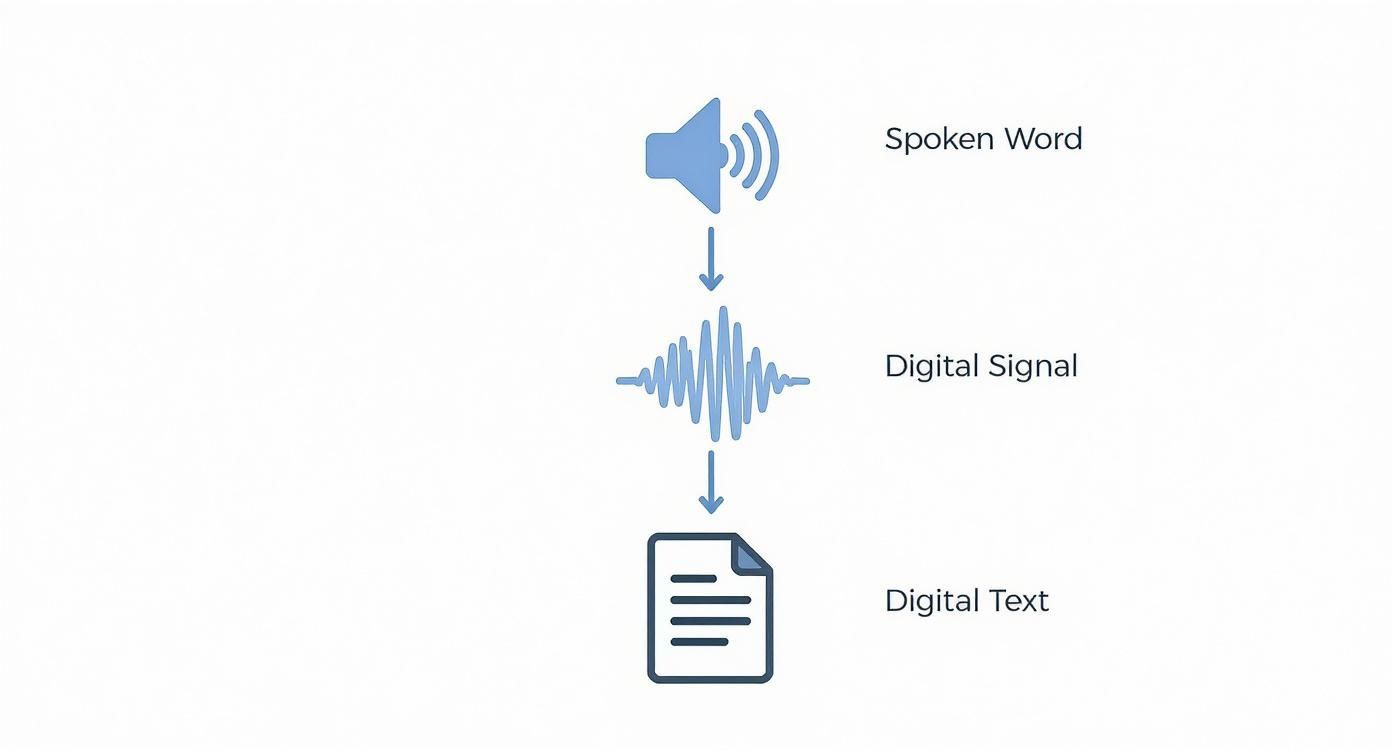
This process—from sound to signal to text—is the puzzle that every ASR architecture, old and new, has tried to solve.
For a long time, the go-to method for ASR was a statistical approach called Hidden Markov Models (HMMs). Think of an HMM as a detective trying to figure out what someone said based only on the sound waves they left behind. It knows the likely sequences of words in a language, but it can only "hear" the phonetic clues.
An HMM-based system would slice up the audio into tiny, millisecond-long frames and make a statistical guess about the most likely sound (or phoneme) in each frame. Then, it would string these sounds together into the most probable words and sentences. This was a modular system with three key parts that had to work in perfect sync:
These HMM systems were the workhorses of ASR for decades. They were groundbreaking for their time, but they were also incredibly complex. You had to train each of these three components separately, and they eventually hit a performance wall because they just couldn't capture all the nuance and variability of human speech.
The next big breakthrough came when researchers started mixing Deep Neural Networks (DNNs) into the classic HMM setup. In this hybrid approach, a powerful DNN replaced the old statistical acoustic model. This was a game-changer for accurately identifying phonemes from messy, real-world audio.
The DNN could learn incredibly complex patterns from massive datasets, which made it far better at dealing with different accents, background noise, and fast talkers. Still, it wasn't a complete overhaul. The system still relied on the rigid HMM framework to assemble the final transcript. It was a better system, for sure, but it was a bit of a Frankenstein's monster—part new, part old.
The hybrid DNN-HMM model was the bridge between two eras. It successfully paired the powerful pattern-matching of deep learning with the proven statistical logic of HMMs, signaling that neural networks were the clear path forward for speech recognition.
The most recent and most powerful shift has been the move to end-to-end automatic speech recognition models. These modern architectures ditch the complicated, multi-part HMM system altogether. Instead, they use a single, massive neural network that learns to map raw audio directly to text. No separate pieces, no complicated pipeline.
It’s like teaching someone a language by having them listen to thousands of hours of conversations while reading along with the transcripts. They naturally pick up the sounds, the vocabulary, and the grammar all at once. End-to-end models do the same, making them simpler to train and way more accurate.
This modern era is defined by a few key architectures:
Connectionist Temporal Classification (CTC): CTC models are great when you don't have a perfect, time-stamped alignment between the audio and the text. The model spits out a character for each tiny audio frame and then intelligently collapses all the repeated letters and blanks to form the final words.
Sequence-to-Sequence (Seq2Seq): These models, often equipped with an "attention mechanism," effectively "listen" to the entire audio clip before they start generating the text. This allows them to grasp the full context of a sentence, leading to much more natural and grammatically sound transcripts.
Transformers: Originally built for machine translation, the Transformer architecture is now king in the ASR world. Its self-attention mechanism is incredibly good at figuring out which parts of the audio are most important for understanding the overall meaning. This makes it the current state-of-the-art for both accuracy and contextual awareness.
These sophisticated end-to-end systems are what fuel the ASR tools we see today, giving developers and businesses the kind of speed and precision that was once just science fiction.
To make sense of this evolution, it helps to see the different approaches side-by-side. Each generation brought something new to the table while trying to overcome the limitations of what came before.
| Model Architecture | Core Principle | Primary Advantage | Common Limitation |
|---|---|---|---|
| HMM-GMM | Statistical modeling of phonemes and word sequences using separate components. | Statistically robust and interpretable. | Complex to train; struggles with speech variability. |
| Hybrid DNN-HMM | A DNN replaces the acoustic model, but HMMs still handle sequencing. | Significantly improved acoustic modeling accuracy. | Still requires a multi-stage pipeline and complex alignment. |
| End-to-End (CTC) | A single network maps audio frames to characters, then collapses the output. | Simplified training pipeline; no alignment needed. | Can produce grammatically awkward or nonsensical outputs. |
| End-to-End (Seq2Seq) | An encoder-decoder model "listens" to the full input before generating output. | Excellent at capturing long-range context. | Can be slow (not real-time); struggles with very long audio. |
| End-to-End (Transformer) | Uses self-attention to weigh the importance of different audio segments. | State-of-the-art accuracy and context awareness. | Computationally intensive and requires massive training data. |
This table highlights the clear trend: a move away from complex, multi-part systems toward unified, data-hungry neural networks that can learn the entire task of speech recognition on their own.
Even the most sophisticated automatic speech recognition models start as a blank slate. They’re useless until they go through a rigorous training process, which is where a model learns to map raw audio signals to actual text. It all begins with getting the audio into a state the machine can actually work with.
This initial stage, called audio preprocessing, is a lot like a chef prepping ingredients. You wouldn't just toss a whole, unwashed potato into a stew. Instead, you clean it, peel it, and chop it. In the same way, raw audio waveforms are messy and far too complex for a model to handle directly.
First, engineers will do some cleanup, like snipping out long silences and evening out the volume levels. The cleaned-up audio is then converted into a more structured format the model can analyze, like a spectrogram or, more commonly, a set of features known as Mel-Frequency Cepstral Coefficients (MFCCs). These features essentially distill the audio down to the most important characteristics of human speech, pushing irrelevant noise to the side.
With the audio prepped, we get to the most critical part of the entire operation: the training data. The quality of this data is, without a doubt, the single biggest factor that determines a model's final accuracy. The logic is simple—for a model to understand what people sound like, it has to listen to an incredible number of examples.
A typical training dataset is made up of millions of hours of audio, each snippet meticulously paired with a human-verified transcript. But it’s not just about sheer volume. Diversity is everything. A model trained exclusively on news anchors speaking flawless English will completely fall apart the second it hears a thick regional accent, some modern slang, or a conversation happening in a noisy café.
You can't overstate this: the quality and diversity of training data directly control how well an ASR model performs in the real world. A model is only as smart as the examples it learns from, which makes a rich, varied dataset the real secret to accuracy.
To build a truly effective model, the training data needs to cover a huge range of scenarios:
Of course, even the biggest dataset can’t possibly include every single audio situation a model might encounter out in the wild. That's where a clever technique called data augmentation comes into play. Think of it as a workout montage for the ASR model, where you intentionally throw difficult, messy audio at it to make it tougher.
Data augmentation involves taking your existing audio files and artificially creating new training examples from them. This helps the model generalize what it learns, so it doesn't get flustered by unexpected sounds or speaking patterns. It’s also a fantastic, cost-effective way to expand the training set and build a much more robust system.
Some common augmentation tricks include:
By running the model through these manufactured "hard mode" scenarios, data augmentation gets it ready for the unpredictable nature of human conversation. This is the kind of tough training that allows modern automatic speech recognition models to work so reliably in the real world.
Building a complex speech recognition model is one thing, but how do you actually measure its success? It's not enough for it to just work—we need a way to quantify how well it performs in the real world. Without clear, objective benchmarks, comparing different systems or even understanding a single model's limitations becomes a guessing game.
The undisputed champion for measuring ASR accuracy is Word Error Rate (WER). It's the industry-standard report card for any transcription model. Think of it as a simple but ruthless calculation that tallies up every mistake a model makes when compared to a flawless, human-verified transcript.
At its core, WER tells you the percentage of words the ASR system got wrong. But it's more nuanced than a simple pass/fail on each word. The formula specifically accounts for three distinct types of errors:
The calculation is straightforward: WER = (S + D + I) / N, where N is the total number of words in the correct transcript. The goal is always a lower WER. A model with a 5% WER is getting 95% of the words right.
A Quick WER Example
- Correct Sentence: "The quick brown fox jumps" (5 words)
- ASR Output: "The quick brown cat jumps" (5 words)
Here, the model made one mistake—it substituted "cat" for "fox." So, the WER is (1 Substitution + 0 Deletions + 0 Insertions) / 5 total words, which equals 20%.
WER was the benchmark that signaled a major shift in the industry. Around 2016, deep learning models finally achieved a word error rate of about 5.9% on the famous Switchboard dataset, effectively matching human performance for the first time. By 2017, some systems hit 95% word accuracy on English. You can check out more of these breakthroughs in the history of speech recognition.
While a low WER is fantastic, it doesn't tell the whole story. For a model to be genuinely useful, two other factors are just as critical: latency and computational cost.
Latency is the time it takes from the moment a word is spoken to when its transcription appears. For anything happening in real-time—like live captioning for a webinar or a voice assistant responding to a command—high latency is a deal-breaker. A 3-second delay in a transcribed phone call would make a conversation completely chaotic, no matter how accurate the text is.
Computational Cost is all about the horsepower needed to run the model. An enormous, highly-tuned model might produce near-perfect transcripts but be far too expensive or slow to run on a smartphone or a regular server. The best automatic speech recognition models find that sweet spot: they deliver great accuracy without frustrating delays or breaking the bank on processing power.
While today's automatic speech recognition models can hit near-human accuracy in a quiet lab, the real world is anything but quiet. Deploying these systems means throwing them into a messy, unpredictable audio environment. The jump from a controlled setting to a live application introduces a whole new set of problems that go way beyond simple transcription.
To be genuinely useful, ASR has to keep up with the fluid, dynamic nature of human conversation. This means navigating multiple languages, figuring out who is talking, and understanding specialized terminology—all while keeping user data private.
The world is a tapestry of languages, and our conversations reflect that. Many of us practice code-switching, where we effortlessly jump between two or more languages in a single conversation, sometimes even in the same sentence. Think of a developer who starts a sentence in English and drops in a term in Spanish.
This is a huge hurdle for ASR models trained only on a single language. The model has to do more than just recognize words from different vocabularies; it needs to grasp the grammatical context they appear in. To get around this, advanced systems are now trained on massive, multilingual datasets, which lets them transcribe these mixed-language conversations without getting tripped up.
Beyond just understanding the words, a key feature for tools like meeting transcription is speaker diarization. It’s the process of figuring out "who spoke when." A raw transcript is one thing, but a transcript that neatly labels each line with "Speaker A" or "Speaker B" is infinitely more valuable. Diarization algorithms do this by analyzing unique vocal patterns to chop up the audio and assign the right text to the right person.
Standard ASR models are great at understanding everyday chatter because that’s what they’re trained on. But throw them into a conversation filled with specialized jargon—like complex medical terms, financial acronyms, or legal phrases—and they start to struggle. An off-the-shelf model might hear "myocardial infarction" and spit out "my old cardio infraction."
The solution is to fine-tune the model on a specialized dataset. This involves taking a general-purpose model and training it further on a smaller, hand-picked set of audio and transcripts from a specific industry. This technique, called domain adaptation, can make a world of difference in accuracy for niche vocabularies.
Think of it like teaching a fluent English speaker the specific slang of air traffic control. They already know the language, but they need to learn the unique terms and phrases to be effective in that environment. Fine-tuning an ASR model works the same way.
Here are just a few of the common curveballs ASR models face in the wild:
As ASR technology weaves itself deeper into our daily lives, privacy and data security have become non-negotiable. Voice data is incredibly personal and can easily contain sensitive information. It's no surprise that a recent industry survey found that over 30% of professionals see data privacy as a major hang-up when using third-party APIs.
People need to know their conversations aren't being stored forever or used without their permission. Top-tier ASR providers tackle this with strict privacy policies, like deleting all user data right after it's processed. For any business operating under rules like GDPR, using an API with EU-based servers can also be a make-or-break requirement for staying compliant.
When all is said and done, a successful ASR deployment is built on trust. The technical magic of turning speech into text has to be backed by a rock-solid commitment to protecting the privacy of the people speaking. For developers and businesses building with ASR today, that ethical foundation is just as critical as any performance metric.
So, you've decided to add voice capabilities to your application. Now you're at a crossroads: do you build your own automatic speech recognition models from the ground up, or do you plug into a ready-made solution from a third-party provider? This decision is a big one, affecting everything from your budget and timeline to how well your final product actually works.
Each route has its own set of trade-offs. Building or fine-tuning a custom ASR model gives you complete control. You can tailor its performance and train it on very specific, proprietary data that no one else has. The catch? This path requires serious machine learning expertise, a ton of computing power, and a long, expensive development cycle.
On the other hand, using a third-party Speech-to-Text API is all about speed and simplicity. It lets you tap into powerful, pre-trained models with just a few lines of code, slashing your implementation time and upfront investment.
For most teams, going with a third-party API is the most practical and efficient way forward. Companies like Lemonfox.ai give you access to incredible transcription technology without the massive headache of building and maintaining it yourself. The benefits are hard to ignore.
It really boils down to this: is your core business building ASR models, or is it building a product that uses ASR? For 99% of teams, the answer is the latter, which makes a reliable API the clear strategic winner.
Getting an ASR API to work well involves more than just blindly sending it an audio file. To build something truly robust, you need to think about security and choose the right integration method for your specific use case.
First things first, protect your API key. Treat it like a password. Store it securely in an environment variable or a secrets manager—never, ever hardcode it into your frontend code where it could be exposed. This simple step prevents unauthorized use and keeps your account safe.
Next, you need to match the integration method to the job. If you need real-time transcription for something like live captioning, you'll want to stream audio data over a WebSocket connection. But for processing large, pre-recorded files—think podcast episodes or lengthy meeting recordings—an asynchronous approach is your best bet. You just upload the file and get a notification when the transcript is done, which keeps your application from locking up while it waits for the result.
Even after diving deep into the tech, a few questions usually pop up. Let's tackle some of the most common ones to round out your understanding.
Think of a speaker-dependent model as a system tailored to one person. It's trained exclusively on a single voice and gets really, really good at understanding just that individual. Early voice command systems often worked this way.
A speaker-independent model, on the other hand, is what we expect from modern tech like Alexa or Google Assistant. It’s trained on a massive, diverse library of voices—thousands of them, with all sorts of accents and dialects. This broad training allows it to understand just about anyone who speaks to it, right out of the box.
This really boils down to what you're trying to accomplish.
If you just need to fine-tune a powerful, pre-trained model to understand your industry's jargon (like medical terms or legal phrases), a few hundred hours of labeled audio can get you there. It's a very targeted adjustment.
But if you're aiming to build a brand new, high-performance model from the ground up? That’s a whole different ball game. You’re looking at a huge investment, typically requiring tens of thousands of hours of accurately transcribed audio to get the kind of reliability needed for real-world use.
For almost everyone, fine-tuning an existing foundation model is the smarter path. It gives you the best bang for your buck in terms of performance versus resources. Building from scratch is usually left to big research labs and tech giants.
Not really, at least not on their own. A standard ASR model has one job: turn spoken words into written text. It’s focused entirely on what was said, not how it was said. Sarcasm, joy, or frustration are lost in translation.
This is a hot area of research, though. Some sophisticated systems are starting to layer a separate emotion detection model on top of the ASR. This secondary model analyzes acoustic cues—pitch, volume, the speed of speech—to make an educated guess about the emotional state of the speaker.
Ready to put all this knowledge into practice? Lemonfox.ai offers a developer-first Speech-to-Text API that makes integration a breeze. You get support for over 100 languages, built-in speaker recognition, and a firm commitment to data privacy. Kick things off with a free trial and get 30 hours of transcription to see how it works for you at https://www.lemonfox.ai.