First month for free!
Get started
Published 1/31/2026
The whole debate between batch and real-time processing really boils down to two things: timing and volume. Batch processing is all about handling massive amounts of data at specific, scheduled times to get the most bang for your buck. On the other hand, real-time processing is built for speed, dealing with a constant flow of data to give you immediate answers.
Deciding between them isn't a technicality—it’s a strategic choice that depends entirely on whether you need cost-effective throughput or instant insights.
At its heart, this is a "how and when" question. Do you wait, gather up a huge pile of data, and process it all in one go for maximum efficiency? That's batch. Or do you tackle each piece of data the second it shows up, prioritizing speed above all else? That's real-time.
A great way to think about it is grocery shopping. Batch processing is your big weekly trip to the store. You build a list all week (collecting data), then go get everything in one efficient, planned-out haul. Real-time processing is like ordering a pizza for delivery—the moment you hit "confirm," the kitchen starts working to get it to your door as fast as possible.

This distinction is absolutely critical for any data-heavy work, especially something like speech-to-text transcription. To make the right call, you have to weigh a few key trade-offs:
Getting clear on these priorities is the first step toward building a data architecture that actually works for you. A flexible tool like Lemonfox.ai is designed to handle both scenarios. You could use its batch processing to affordably transcribe an entire archive of old podcast episodes or tap into its real-time API to generate live captions for a conference call.
To quickly see how these two approaches stack up, this table breaks down their core characteristics.
| Attribute | Batch Processing | Real-Time Processing |
|---|---|---|
| Data Scope | Large, bounded datasets | Individual records or micro-batches |
| Latency | High (minutes, hours, or days) | Low (milliseconds or seconds) |
| Throughput | High (optimized for volume) | Lower (optimized for speed) |
| Resource Use | Intermittent, scheduled peaks | Continuous, always-on |
| Cost Model | Generally lower, pay-per-job | Generally higher, constant operational cost |
| Ideal Use Case | Payroll, billing, large-scale reports | Fraud detection, live monitoring, streaming analytics |
As you can see, there’s no universally "better" option. The ideal choice is always dictated by the specific demands of the job at hand.
Think of batch processing as the workhorse of the data world. Its core philosophy is simple but incredibly effective: collect your data first, and process it all together later. This means you gather large amounts of information over a specific period—maybe an hour, a day, or even a week—and then run a single, scheduled job to handle everything in one go. The entire architecture is built for maximum throughput and efficiency, not for speed.
By running these heavy computational jobs during off-peak hours, like overnight, companies can take advantage of idle resources when system demand is low. This approach drastically cuts down operational costs and ensures that critical systems don't get bogged down during peak business hours. It's a cornerstone strategy for any high-volume task where immediate results aren't necessary.
The real power of batch processing is its unparalleled ability to chew through enormous datasets without breaking the bank. When you need to process terabytes or even petabytes of data, running a single, highly optimized job is vastly more economical than keeping a complex, always-on system humming for continuous processing. This is exactly why it remains the default choice for so many core business functions.
You see this model in action everywhere. Just think of these classic examples:
In every one of these scenarios, the goal is to process a complete dataset with total accuracy and reliability. The business doesn't need instant results; it needs the right results.
Batch processing prioritizes cost-effectiveness and comprehensive throughput over low latency. It is the ideal solution when the completeness and accuracy of a large dataset are more important than the immediacy of the result.
The economic advantages are significant. A 2023 survey of Fortune 500 companies found that 68% still depend on batch jobs for end-of-day reporting and compliance audits, citing cost reductions of 40-60% compared to continuous streaming. This efficiency is on full display in global finance, where daily settlement processes handle over $2 quadrillion in transactions annually using batch systems. For more on these trends, you can dive into recent industry analysis of production data.
This same model is a perfect fit for high-volume audio and video transcription. For any organization sitting on a mountain of media archives, batch processing is easily the most logical and budget-friendly way to get it transcribed.
Picture having to transcribe a library with thousands of hours of recorded content. We're talking about use cases like:
For these kinds of jobs, a service like Lemonfox.ai is perfectly suited for batch mode. A developer can put together a simple script that points to an entire directory of audio files and submits them to the API. The system then works through that large queue efficiently, delivering highly accurate transcripts at an extremely low cost per hour. The whole point is to get the complete, transcribed archive—waiting a few hours for the results is an easy trade-off for the massive cost savings.
Where batch processing is about deliberate, scheduled work, real-time processing is all about immediacy. It’s a completely different mindset. Here, we're dealing with a constant flow of data, and the goal is to process each piece of information the second it arrives. We're not measuring latency in hours or minutes anymore—we're talking milliseconds.
This "always-on" approach to data has become accessible thanks to powerful platforms like Apache Kafka and a host of cloud-native services. Instead of letting data pile up, you process it in-flight, as it’s being created. This allows your systems to react to events as they unfold, which is a game-changer for any time-sensitive operation.
This kind of speed isn't just a neat technical trick; it's a fundamental business advantage. In a growing number of scenarios, data that’s even a few minutes old is practically worthless.
For many applications today, the value of data has a very short half-life. The power to act on information within seconds can mean the difference between a sale and a lost customer, or between a secure system and a catastrophic breach. This makes real-time processing the only viable option for systems like:
The global impact of this speed is huge. In cybersecurity, for example, real-time threat detection was credited with preventing an estimated $10.5 trillion in cybercrime damages in 2023 by generating alerts in seconds. That’s a stark contrast to batch reporting, which can miss up to 70% of active attacks. E-commerce giants like Amazon use real-time recommendations to drive conversion rates up by as much as 35%. You can dig deeper into these use cases on Streamkap's resource page.
Real-time processing turns data into immediate action. It enhances user experience, mitigates risk, and creates business agility by closing the gap between when an event occurs and when you can respond to it.
Of course, this power doesn't come for free. Building and maintaining a real-time architecture is almost always more complex and expensive than its batch counterpart. The infrastructure has to be "always-on," which means continuous resource allocation and sophisticated fault tolerance to handle unpredictable data streams without dropping the ball. Just keeping data consistent and in the right order in a distributed streaming environment is a significant engineering puzzle.
For anyone working with speech-to-text, this is the paradigm for interactive applications. If you're building live captions for a webinar, transcribing a customer support call as it’s happening, or developing voice command features, the feedback has to be instantaneous. The user speaks, and the words need to appear on the screen right away.
In these situations, a service like Lemonfox.ai is designed to be integrated via its streaming API. A developer can send small chunks of live audio to the API and get transcriptions back with incredibly low latency. It’s certainly a more involved implementation than a simple batch file upload, but it unlocks a level of interactivity and responsiveness that is completely out of reach for a batch system.
Choosing between batch and real-time processing means getting past the basic definitions and digging into the real-world trade-offs that impact your business and your bottom line. This isn't just a technical decision; it's about matching the processing model to the problem you're trying to solve. The debate over batch processing vs real time processing is really about picking the right tool for the job.
When you put them side-by-side, you don’t find a "better" or "worse" option. Instead, you see two specialized approaches, each designed for entirely different scenarios. Understanding where each one shines is the key to building an architecture that's both powerful and cost-effective.
The first and most important trade-off is between latency (how fast you get a single result) and throughput (how much data you can process over a period of time). These two goals are almost always at odds with each other.
Real-time processing is built from the ground up for one thing: minimizing latency. Its entire purpose is to act on data the moment it arrives. This makes it the only viable choice for applications where even a few seconds of delay is a deal-breaker. Think of live captioning for a broadcast event—the words have to appear on screen almost instantly.
Batch processing, on the other hand, is all about maximizing throughput. It deliberately delays processing to collect large volumes of data first. This allows it to chew through massive, finite datasets with incredible efficiency. Imagine you need to transcribe an entire archive of company meetings from the past year. A batch job can run overnight and process everything far more efficiently than any real-time system ever could.
A real-time system is a sprinter, optimized for a burst of speed over a short distance. A batch system is a marathon runner, built for endurance and covering a huge distance over time.
Your budget and infrastructure will heavily influence this decision. The way these two models use resources is completely different, which leads to dramatically different costs.
Real-time processing demands an "always-on" infrastructure. Because data can show up at any second, your system has to be provisioned, running, and ready to pounce. This constant state of readiness means you're paying for compute resources even when they're sitting idle, waiting for the next event to happen. Naturally, this leads to higher operational costs.
Batch processing is much friendlier to your wallet. Resources are only spun up when a job is scheduled to run, which is often during off-peak hours when compute costs are at their lowest. This on-demand model completely avoids the cost of idle capacity, making it perfect for large but non-urgent tasks where the cost-per-gigabyte is your main concern. For instance, processing terabytes of call center recordings for sentiment analysis is vastly cheaper in batch mode.
Finally, you have to consider the shape and size of your data. The core difference here comes down to whether your data is bounded or unbounded.
Batch systems are the undisputed champions of bounded data—large, finite datasets with a clear start and end. This could be a month's worth of financial transactions, a full season of a TV show that needs subtitling, or an entire archive of research interviews. The system knows the full scope of the job before it even begins.
Real-time systems are built for unbounded data—a continuous, never-ending stream of information. This includes data from IoT sensors, website clickstreams, or a live audio feed from a conference. There is no "end" to the data, so the system has to process each piece individually as it arrives, without the luxury of knowing what’s coming next.
To make a clear decision, it helps to see these trade-offs laid out side-by-side. Each criterion highlights how one model's strength is often the other's weakness, reinforcing the need to align your choice with specific business needs.
| Criterion | Batch Processing | Real-Time Processing | Best For |
|---|---|---|---|
| Primary Goal | High throughput | Low latency | Depends on the business need for speed versus volume. |
| Data Type | Bounded, large volumes | Unbounded, continuous streams | Archival data analysis vs. live, in-the-moment interactions. |
| Resource Model | Intermittent, scheduled | Continuous, always-on | Cost-sensitive projects vs. time-sensitive applications. |
| Cost Efficiency | High. You only pay for active processing time. | Lower. You pay for constant readiness and idle capacity. | Projects with flexible deadlines and large data volumes. |
| Implementation Complexity | Lower. The logic for discrete jobs is simpler. | Higher. Requires managing state, order, and faults in a continuous stream. | Applications needing immediate user feedback and interaction. |
Ultimately, this comparison shows that batch and real-time processing are not competitors but specialists. The right choice depends entirely on your goals, whether that means prioritizing the cost-effective analysis of historical data or delivering the instantaneous experience that modern interactive applications require.
Let's move from the technical details to the practical realities. Choosing between batch and real-time processing isn't about picking a "winner"—it's about matching the right tool to your specific project needs. The whole debate of batch processing vs real time processing really comes down to what makes sense for your business goals, your budget, and what your users actually expect. Getting this right starts with asking a few basic questions.
This simple decision tree gets right to the heart of the matter. Often, just thinking about how fresh your data needs to be can point you in the right direction immediately.
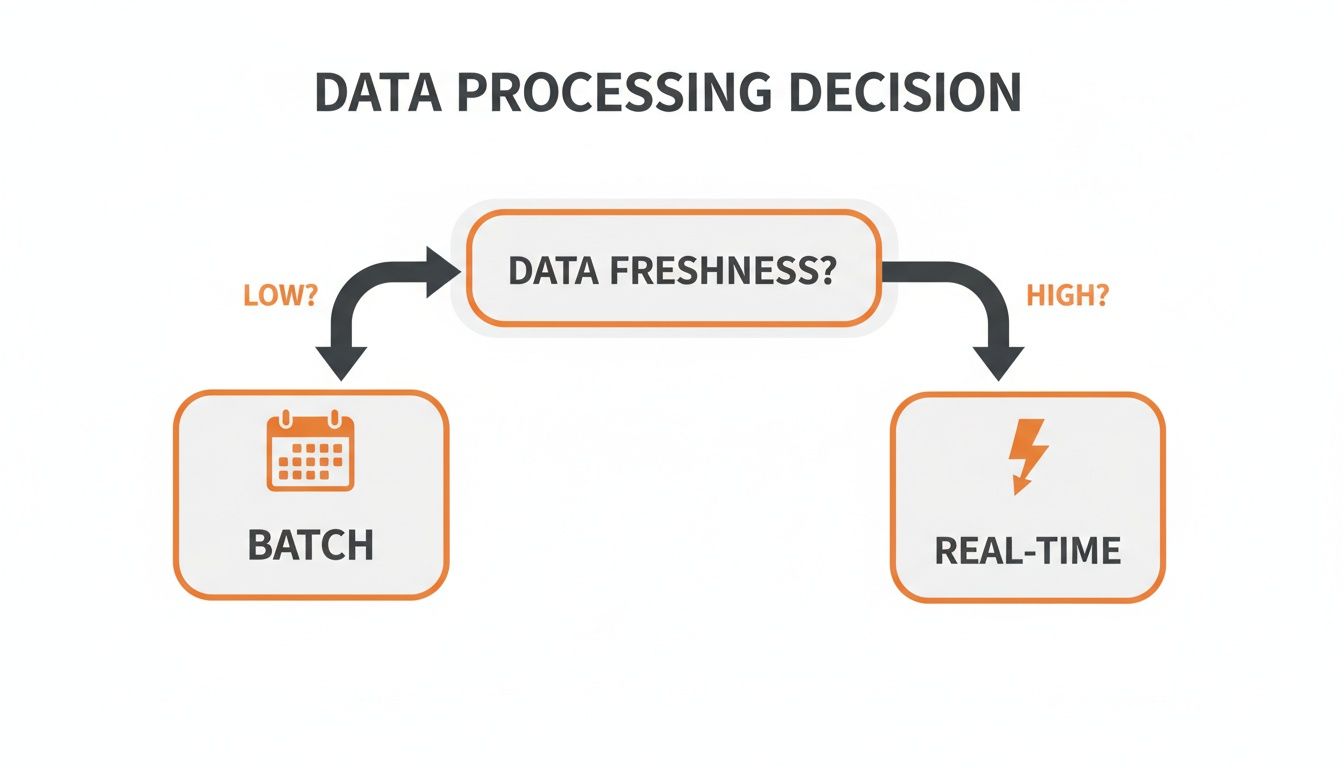
As the flowchart shows, the primary trade-off is clear. If your application can handle a bit of a delay, batch processing will save you a ton of money and effort. But if you need results right now, real-time is your only option.
Data freshness is a great starting point, but a solid architectural decision requires a bit more digging. This checklist will help you pin down the non-negotiables for your system and avoid painting yourself into a corner later on.
1. What is the business impact of data delay?
Think about it in real terms. If a delay of a few hours could mean a lost sale, a missed security threat, or a frustrated customer, you've got a strong business case for real-time processing. On the other hand, if the data is just for a monthly report, the delay is irrelevant, and batch is the obvious, smarter choice.
2. What is our budget for infrastructure and operations?
This is a big one. Real-time systems demand "always-on" infrastructure, and that comes with a higher, continuous price tag. Batch systems are much more frugal, spinning up resources only when needed. You have to be realistic about what you can afford not just to build, but to maintain month after month.
3. What does our data look like?
Is your data a massive, self-contained archive of files? That’s bounded data. Or is it a never-ending firehose of events? That’s unbounded data. The fundamental shape of your data naturally pushes you toward one model or the other.
4. How complex is the implementation?
Don't underestimate the engineering effort. Batch jobs are typically straightforward to develop, test, and troubleshoot. Real-time streaming architectures, however, introduce tricky challenges like state management, message ordering, and fault tolerance—all of which require more specialized skills from your team.
For many modern applications, the answer isn't "either/or." It's "both." A hybrid architecture is often the most elegant solution, letting you use the strengths of each model for different parts of your workflow. You don’t have to force one system to do everything.
By combining batch and real-time processing, you can handle high-volume, non-urgent tasks with maximum cost efficiency while delivering the low-latency experiences users expect for interactive features.
This best-of-both-worlds strategy is all about aligning your spending and complexity directly with business value. You save the expensive, complex real-time pipeline for the features that absolutely must have it and lean on the economical batch model for everything else.
Speech-to-text workflows are a perfect illustration of where a hybrid model truly excels. Imagine a company running a large, multi-day conference. They have two completely different transcription needs that map perfectly to this approach.
Post-Event Archiving (Batch Processing): The conference is over, and now they have hundreds of hours of recorded sessions. The goal is simple: create a complete, searchable archive. Using the Lemonfox.ai batch API, they can upload all the audio files in a single, cost-effective job. The processing can run overnight, and by morning, they'll have highly accurate transcripts for the entire event at the lowest possible cost.
Live Event Captioning (Real-Time Processing): While the conference is happening, they need live captions for attendees. This is a real-time problem. Using the Lemonfox.ai streaming API, they can send audio from the live feed in small chunks and get transcriptions back almost instantly, displaying them on-screen with minimal delay.
This hybrid setup is both practical and powerful. It delivers a critical real-time feature to improve the live experience while using the most economical method for the massive archival task. It’s a great reminder that the best architecture often comes from knowing when to use each tool, not from being loyal to just one.
Theory is great, but turning the concepts of batch and real-time processing into working code is where the value is. Whether you're archiving old audio files or captioning a live event, the practical steps you take will be completely different. Let's look at how you'd build both using the Lemonfox.ai Speech-to-Text API to tackle these distinct transcription challenges.
It's a perfect example of how the batch processing vs real-time processing debate isn't about finding a single winner. It’s about picking the right tool for the job.
When you have a massive archive of audio to get through, a batch process is your best friend. It’s cost-effective, straightforward, and built for high throughput. The whole idea is to process a known, finite set of audio files without any rush.
Let's say you have a folder with hundreds of recorded interviews. A developer could whip up a simple script to:
.mp3 or .wav).This is a classic "set it and forget it" approach. It runs in the background, making it perfect for non-urgent tasks like converting a podcast backlog or analyzing a month's worth of customer support calls. The cost savings really add up when you're processing at scale.
Real-time transcription is a different beast entirely. It demands a dynamic architecture built for speed and low-latency streaming. This is non-negotiable for interactive applications like live meeting captions or voice-activated assistants, where any delay breaks the user experience.
An effective real-time system is all about continuous data flow. It processes audio in small, sequential chunks to keep the perceived delay so low that the user experience feels instantaneous.
To build this with Lemonfox.ai, you'd use a persistent streaming connection, like WebSockets. The architecture would generally follow these steps:
This method delivers that snappy, responsive feel users expect. The good news is that both batch and real-time models get to use Lemonfox.ai's powerful features, like precise speaker recognition and support for over 100 languages. And because it’s an EU-based API, you get an essential layer of data privacy, ensuring compliance while still getting top-tier performance for whatever you’re building.
When you’re deep in the weeds of system design, it's the practical questions that often pop up. Let’s tackle a few of the most common ones that developers and product leaders ask when weighing batch against real-time processing.
The short answer is yes, but it’s rarely a simple flip of a switch. Moving from batch to real-time usually means a fundamental architectural overhaul. You're essentially swapping out scheduled, chunky jobs for a continuous, flowing data pipeline. This touches everything—from data ingestion and storage to the processing logic itself.
It's a complex and often expensive undertaking. That's why it’s so important to think about your future needs right from the start. A common middle ground is to adopt a hybrid model: keep your existing batch system for large-scale, non-urgent tasks and build a separate real-time layer on top for features that demand immediacy.
They’re close, but not quite the same. The difference really comes down to latency tolerance.
This is often accomplished with a technique called micro-batching, where the system processes data in very small, frequent chunks. It’s perfect for use cases like updating a sales dashboard every 30 seconds—fast, but not instantaneous.
The core distinction between "real-time" and "near real-time" is the tolerance for delay. While both are fast, true real-time aims for an immediate response, whereas near real-time accepts a small, predictable latency for improved efficiency.
Consistency is a huge factor. Batch processing systems are champions of strong consistency. Because data is handled in discrete, self-contained jobs, it’s much easier to guarantee that every piece of data is processed fully and correctly before the final output is released.
Real-time systems often have to make a tough choice between latency and consistency. While you can architect a streaming system for strong consistency, many prioritize speed and availability. This often leads to an eventual consistency model, where the system might be momentarily out of sync before all nodes catch up. It's a critical trade-off to consider in the batch processing vs real time processing debate.
Ready to implement a powerful and affordable transcription solution? With Lemonfox.ai, you can build both batch and real-time workflows with a single, easy-to-use API. Start your free trial today and get 30 hours of transcription.