First month for free!
Get started
Published 10/11/2025

In a world driven by efficiency, converting spoken words into text automatically is no longer a luxury, it's a necessity. From developers building innovative applications to professionals streamlining their workflow, the demand for accurate, accessible, and affordable speech recognition is soaring. But navigating the landscape of available tools can be daunting. Many solutions are either prohibitively expensive or too complex for everyday use. That's why we've dived deep into the market to identify the truly standout options that cost you nothing to get started.
This guide cuts through the noise, offering a detailed breakdown of the 12 best free speech recognition software platforms available today. We move beyond simple feature lists to provide a comprehensive analysis of each tool's real-world performance. This includes everything from powerful, open-source models ideal for developers to user-friendly apps perfect for daily dictation. The applications are incredibly diverse, from automating meeting notes to powering voice-controlled interfaces. Beyond general transcription, specialized AI solutions like AI medical scribe platforms demonstrate the growing sophistication and specific applications of this technology.
Our goal is to help you find the perfect fit for your specific needs. Each entry includes an in-depth look at its features, pros, cons, supported languages, ideal use cases, screenshots, and direct links to get you started immediately. We focus on practical considerations and honest limitations, ensuring you can make an informed decision without wading through marketing jargon.
OpenAI's Whisper is an open-source automatic speech recognition (ASR) system that has set a new standard for transcription accuracy. Unlike cloud-based APIs that charge per minute, Whisper is a collection of models you can download and run on your own hardware, making it a truly free speech recognition software for those with the technical capacity. This local-first approach provides complete data privacy and eliminates ongoing operational costs.
Whisper’s key strength lies in its robustness. Trained on a massive and diverse dataset of 680,000 hours of multilingual audio from the web, it excels at handling background noise, various accents, and technical jargon with remarkable precision. This makes it an exceptional tool for transcribing interviews, podcasts, and meetings where audio quality may not be pristine.
tiny (fast but less accurate) to large (incredibly accurate but resource-intensive). This allows developers and researchers to balance performance needs with available hardware.However, implementation requires technical expertise. Users need to be comfortable with Python and command-line interfaces to install and run the models. The larger, more accurate models also demand a powerful GPU for reasonable processing speeds, creating a hardware barrier for some users.
Best for: Developers, researchers, and privacy-conscious users who need highly accurate, offline transcription and have access to capable hardware. It’s a top choice for academic research, internal business meeting transcription, and building custom applications.
Learn More: OpenAI Whisper on GitHub
Vosk is an open-source, offline speech recognition toolkit designed for developers who need reliable performance on a wide range of hardware, from powerful servers to low-resource devices like a Raspberry Pi. Unlike cloud-based services, Vosk runs entirely on-premise, making it a fantastic free speech recognition software for applications where data privacy, low latency, and internet independence are critical. Its architecture is optimized for continuous, real-time transcription in embedded systems.
The core strength of Vosk lies in its portability and ease of integration. It provides simple bindings for numerous popular programming languages, including Python, Java, C#, and Node.js, significantly lowering the barrier to entry for developers. This flexibility makes it a go-to choice for building voice-controlled interfaces, in-car assistants, and smart home applications without relying on an external API or incurring usage costs.
While Vosk is incredibly versatile, its accuracy can vary depending on the language and the chosen model size. The setup is more hands-on compared to a simple API call, requiring developers to manage the models and integration themselves. The larger, more accurate models also demand more system memory.
Best for: Developers building offline or edge-computing applications, privacy-focused projects, and voice-enabled smart devices. It is an excellent choice for creating voice assistants, interactive kiosks, or transcription tools that must function without an internet connection.
Learn More: Vosk by AlphaCephei
CMU Sphinx is a venerable open-source speech recognition toolkit hailing from Carnegie Mellon University. As one of the original players in the field, its primary advantage today lies in its lightweight and efficient design, particularly with PocketSphinx, its specialized version for mobile and embedded devices. This makes it an excellent choice for offline, real-time applications on resource-constrained hardware where modern, GPU-heavy models are impractical.
Unlike cloud-based services, CMU Sphinx runs entirely locally, ensuring complete data privacy and zero operational costs. Its permissive BSD-style license allows for broad use in both academic and commercial projects without restrictive terms. The toolkit is designed for developers who need granular control over the recognition process, from acoustic model training to custom language model creation for specific domains, such as voice-controlled robotics or specialized kiosk commands.
However, its age is a factor. The out-of-the-box accuracy of CMU Sphinx is significantly lower than modern neural network-based systems like Whisper, especially for general-purpose transcription with diverse accents and background noise. Achieving high accuracy requires substantial effort in data collection and model training for your specific use case.
Best for: Developers, hobbyists, and academics building offline voice control applications for embedded systems or specialized desktop tools. It excels in environments where resources are minimal and the vocabulary is limited and well-defined.
Learn More: CMU Sphinx on GitHub
For academic and commercial R&D teams, Kaldi is less of a product and more of a foundational open-source toolkit for building bespoke speech recognition systems. Written in C++ and licensed under Apache 2.0, it provides a comprehensive set of modules for everything from feature extraction and acoustic modeling to complex decoding graphs. It is the engine behind countless research papers and production-grade ASR systems.
Unlike plug-and-play models, Kaldi’s power lies in its extreme flexibility. It allows developers to train models on custom datasets, fine-tune acoustic and language models for specific domains (like medical or legal terminology), and experiment with cutting-edge deep neural network architectures. This makes it an invaluable piece of free speech recognition software for organizations that need complete control over their ASR pipeline.
The trade-off for this power is a very steep learning curve. Kaldi is not for beginners; it requires significant expertise in speech recognition, signal processing, and shell scripting. Deployment demands careful configuration and access to powerful GPU resources for efficient training.
Best for: ASR researchers, academic institutions, and large enterprises with dedicated machine learning teams that need to build highly customized, domain-specific speech recognition models from the ground up.
Learn More: Kaldi ASR Toolkit
Microsoft's Azure AI Speech to Text offers an enterprise-grade, cloud-based automatic speech recognition (ASR) service that stands out for its reliability and scalability. While primarily a paid platform, its generous free tier makes it one of the best free speech recognition software options for developers and small businesses looking to integrate powerful transcription capabilities without an initial investment. This managed service handles the infrastructure, allowing users to focus on building applications.
Unlike self-hosted models, Azure provides a robust, globally available API backed by Microsoft's extensive infrastructure. It excels in both real-time streaming transcription for applications like live captioning and batch processing for large audio files. The platform is designed for professional use, offering extensive documentation and SDKs that simplify integration into various programming languages and environments.
The main consideration is that it operates within a cloud ecosystem. Users must create an Azure account and set up billing information, even for the free tier. Once the free monthly limit is exceeded, usage is charged on a pay-as-you-go basis. This model requires careful monitoring to avoid unexpected costs but provides a clear path to scale from a free project to a production-level service.
Best for: Developers and businesses needing a reliable, managed ASR solution with a clear upgrade path. It's ideal for integrating real-time transcription into applications, call center analytics, and projects requiring high availability and support.
Learn More: Microsoft Azure AI Speech to Text
Google Cloud Speech-to-Text is a mature, highly scalable Automatic Speech Recognition (ASR) service that powers products like Google Assistant. While a premium enterprise tool, its generous free tier makes it one of the best free speech recognition software options for developers and small-scale projects. It provides a powerful entry point into enterprise-grade transcription without an initial financial commitment.
This platform excels by offering specialized recognition models tailored for different audio types, such as phone calls, video, or short commands, leading to superior accuracy in specific use cases. Its integration within the broader Google Cloud Platform (GCP) ecosystem allows developers to easily connect transcription results to other services like storage, analytics, and machine learning tools, creating a seamless workflow.
telephony, video), which significantly improves recognition accuracy for those scenarios.However, using the service requires setting up a Google Cloud account with a billing profile, which can be a barrier for casual users. While the initial 60 minutes on the v1 API are free, exceeding that limit incurs costs, and the newer v2 API has a different pricing model without a comparable monthly free allotment. Data logging for model improvement is enabled by default, and opting out can result in higher pricing.
Best for: Developers and businesses building applications that require a reliable, high-accuracy, and scalable transcription API. It's ideal for projects that can operate within the 60-minute free monthly limit or for those testing enterprise solutions before committing to a paid plan.
Learn More: Google Cloud Speech-to-Text Pricing
Amazon Transcribe is a fully managed automatic speech recognition (ASR) service from Amazon Web Services (AWS) that makes it easy for developers to add speech-to-text capabilities to their applications. While it's a commercial service, its inclusion in the AWS Free Tier makes it an excellent choice for developers and small businesses looking to experiment with high-quality, free speech recognition software without initial investment. This tier provides 60 minutes of transcription per month for the first 12 months.
Transcribe is designed for scalability and deep integration within the AWS ecosystem. It excels at processing both real-time audio streams and pre-recorded audio files stored in services like Amazon S3. Its standout features include automatic language identification, speaker diarization (channel identification), and the ability to create custom vocabularies to improve accuracy for domain-specific terms, product names, or unique jargon.
The primary limitation is the cost beyond the generous free tier. As usage scales, it becomes a paid service with per-second billing. Furthermore, specialized versions like Amazon Transcribe Medical and Amazon Transcribe Call Analytics are priced separately and have higher costs, making it crucial to understand the pricing model for your specific needs.
Best for: Developers and businesses already invested in the AWS ecosystem, or those needing a scalable, production-ready ASR solution with a generous introductory free tier. It's ideal for building voice-enabled applications, transcribing customer service calls, and creating media subtitles.
Learn More: Amazon Transcribe Pricing
NVIDIA Riva is a GPU-accelerated software development kit (SDK) designed for organizations that require high-performance, real-time speech recognition with complete data privacy. Unlike cloud-based services, Riva is deployed on-premises or in a private cloud, ensuring that sensitive audio data never leaves your infrastructure. This makes it a powerful free speech recognition software for enterprise-grade applications where latency and security are non-negotiable.
Riva’s core advantage is its optimization for NVIDIA GPUs, enabling incredibly low-latency streaming and batch transcription. It is engineered to handle massive, concurrent audio streams, making it suitable for call centers, live broadcasting, and virtual assistants. The SDK provides highly accurate, pretrained models that can be further customized on specific datasets to improve performance on domain-specific terminology.
The primary limitation is its hardware dependency; Riva requires a compatible NVIDIA GPU and technical expertise in Docker and server management for setup. While the core SDK is free for development and limited deployment, scaling for commercial enterprise use requires a paid subscription.
Best for: Enterprises, developers, and organizations that need a secure, low-latency, and scalable speech recognition solution running on their own infrastructure. It's ideal for building real-time voice assistants, call center analytics tools, and live captioning services.
Learn More: NVIDIA Riva
For Mac users, one of the most accessible and effective free speech recognition software options is already built into the operating system. Apple Dictation provides convenient, system-wide voice-to-text functionality, allowing users to dictate text anywhere they can type, from word processors and email clients to web forms. Its primary advantage is its seamless integration and ease of use, activated with a simple keyboard shortcut.
The experience is particularly powerful on Macs with Apple silicon (M1, M2, and later). On these devices, dictation processing happens entirely on-device, meaning it works offline, has no time limits, and ensures user privacy. This local processing makes it incredibly fast and reliable for everyday productivity tasks like drafting documents, writing notes, or replying to messages without an internet connection.
However, Apple Dictation is designed for direct input rather than transcribing pre-recorded audio files. It lacks the advanced features found in dedicated transcription tools, such as speaker identification or timestamping. Its feature set, including automatic punctuation and language support, can also vary depending on your region and system settings, and it offers minimal customization or enterprise-level controls.
Best for: Mac users looking for a fast, private, and seamlessly integrated way to convert speech to text for personal productivity. It is perfect for drafting emails, writing documents, and general note-taking directly on their device.
Learn More: Using Apple Dictation on Mac
For users seeking a completely integrated and free speech recognition software solution, the native tools built into Windows are an excellent starting point. Voice Access in Windows 11 (an evolution of the older Windows Speech Recognition) provides robust system navigation and dictation capabilities right out of the box. There’s no software to install or API to configure; it’s a feature that can be enabled to control your entire PC with your voice, from opening applications to dictating documents.
The primary strength of this tool lies in its deep integration with the operating system. You can seamlessly switch between typing, clicking, and speaking commands without leaving your workflow. This makes it an invaluable accessibility tool and a practical hands-free option for general productivity tasks like writing emails, browsing the web, or managing files, all without incurring any costs.
While incredibly convenient, Voice Access is not designed for developer-centric tasks like batch-processing audio files or high-accuracy academic transcription. Its performance is also highly dependent on the quality of your microphone and the processing power of your PC. It offers fewer customization options compared to dedicated APIs or open-source models.
Best for: Everyday PC users, individuals with accessibility needs, and professionals looking for a no-cost, hands-free way to dictate text and navigate their Windows environment without installing third-party software.
Learn More: Use Voice Access to control your PC
Otter.ai is a cloud-based transcription service designed specifically for transcribing meetings, lectures, and interviews in real time. Unlike many developer-focused tools, Otter.ai is an end-user application that excels at creating live, collaborative notes. Its seamless integrations with video conferencing platforms like Zoom, Google Meet, and Microsoft Teams make it a standout choice for professionals, students, and teams who need instant, shareable meeting records.
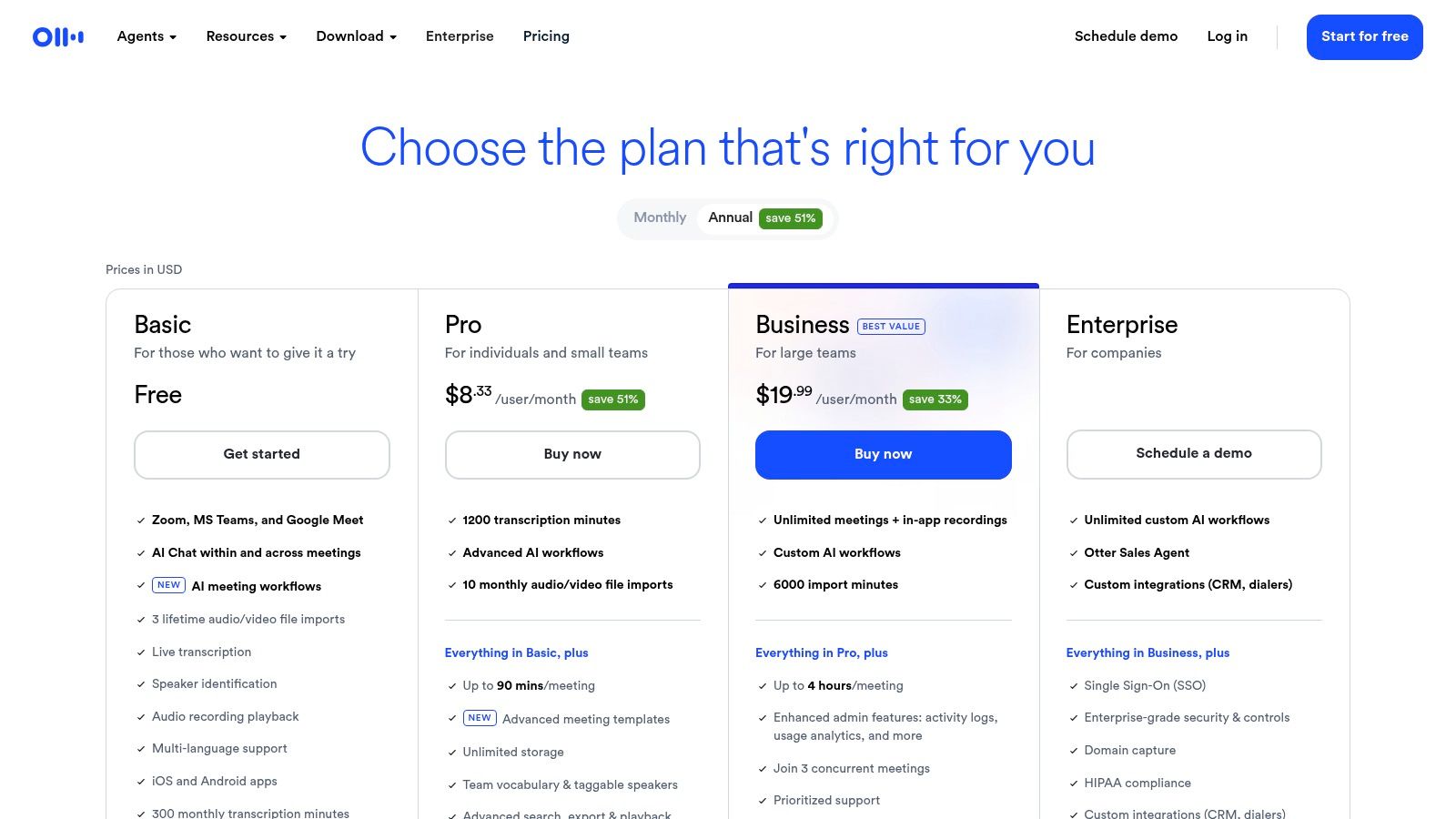
The platform's strength is its user-friendly interface and focus on collaboration. During a live meeting, the "OtterPilot" can automatically join, record, and transcribe the conversation, identifying different speakers and generating a summary with key takeaways afterward. This makes it an invaluable productivity tool, transforming spoken words into actionable text without manual effort. While it offers a generous free plan, users should be aware of its limitations and the cloud-based nature of the service.
However, the free plan has strict limits on transcription minutes (300 per month) and import file count (3 lifetime). For sensitive or confidential meetings, its cloud-based storage model may raise data privacy concerns compared to offline solutions.
Best for: Students, professionals, and teams needing an easy-to-use, automated notetaker for virtual meetings and lectures. It's a perfect example of free speech recognition software applied directly to a common business productivity challenge.
Learn More: Otter.ai Pricing
Picovoice Leopard offers a powerful on-device speech-to-text engine designed for applications where privacy, low latency, and offline functionality are paramount. Unlike cloud-based services that process data remotely, Leopard performs all transcription directly on the user's device, from microcontrollers to web browsers. This makes it an ideal choice for developers building applications that handle sensitive audio data or need to operate without a reliable internet connection.
Its unique selling point is its efficiency and cross-platform support. The SDKs are lightweight and optimized for performance, ensuring minimal resource consumption and fast processing times. The platform’s Forever-Free plan provides a generous allowance for non-commercial projects, making it one of the best free speech recognition software options for hobbyists, researchers, and developers prototyping new ideas.
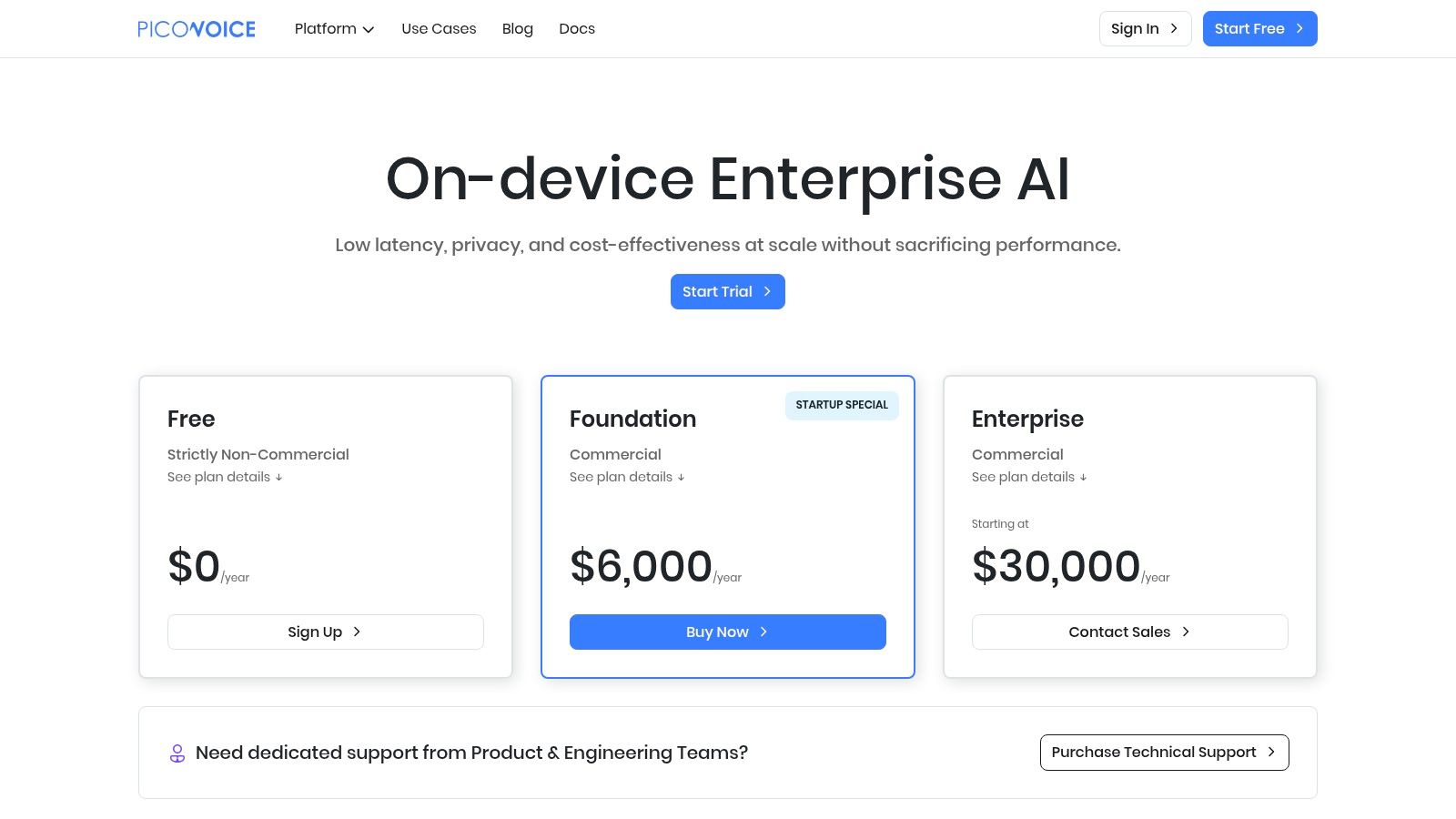
The main limitation is its licensing model. The free tier is strictly for non-commercial use, and while it's generous, it does have usage caps. Startups and businesses must purchase a commercial license, which can be a significant investment. However, for those building privacy-centric applications or exploring voice AI without initial costs, the free plan is exceptionally valuable.
Best for: Developers and hobbyists building privacy-focused, offline-capable applications. It’s perfect for prototyping voice interfaces, creating personal voice assistants, and developing tools for edge devices where cloud connectivity is not an option.
Learn More: Picovoice Leopard Pricing
| Product | Core Features / Accuracy ★★★★☆ | User Experience & Quality ★★★★☆ | Value Proposition 💰 | Target Audience 👥 | Unique Selling Points ✨ |
|---|---|---|---|---|---|
| OpenAI Whisper | Multilingual, multiple model sizes, offline | High accuracy, flexible deployment | Free software cost, runs offline 💰 | Developers, researchers | Open-source, no cloud fees, strong ecosystem 🏆 |
| Vosk by AlphaCephei | 20+ languages, streaming API, multilingual | Lightweight, privacy-focused | Fully offline, Apache 2.0 license 💰 | Embedded systems, privacy-focused | Multi-language, lightweight, offline ✨ |
| CMU Sphinx / PocketSphinx | BSD license, lightweight, embedded use | Basic accuracy, well-documented | Free, permissive license 💰 | Academic, constrained devices | Embedded optimized, long-standing toolkit ✨ |
| Kaldi ASR | Advanced training, custom acoustic models | Professional level, steep learning curve | Free, open-source but expertise needed 💰 | Research teams, ASR experts | Highly flexible, production-proven 🏆 |
| Microsoft Azure AI STT | Real-time/batch, custom models, SDKs | Reliable, scalable, free tier 5h/month | Paid beyond free tier | Enterprises, cloud users | Enterprise-grade, global cloud ✨ |
| Google Cloud Speech-to-Text | Streaming & batch, diarization, multi-models | Mature, 60 free min/month (v1 API) | Paid beyond free tier | Developers, enterprises | Google ecosystem integration 🏆 |
| Amazon Transcribe | Real-time, PII redaction, custom models | Deep AWS integration, free tier 60 min | Paid beyond free tier | AWS users, enterprises | PII redaction, AWS integration ✨ |
| NVIDIA Riva | GPU-accelerated, on-prem, real-time ASR/TTS | Excellent performance, local privacy | Requires NVIDIA GPU, paid enterprise plan | Enterprise, GPU users | Local GPU for low latency & privacy 🏆 |
| Apple Dictation | System-wide dictation, automatic punctuation | Fast, no limits on Apple silicon | Free with macOS | Apple users, personal productivity | On-device, integrated macOS ✨ |
| Windows 11 Voice Access | Voice typing & control, multi-app support | Free, some offline functions | Free with Windows 11 | Windows users, general consumers | System integration, no extra software ✨ |
| Otter.ai | Real-time meeting notes, speaker ID | Easy use, good collaboration | Free tier with limits 💰 | Individuals, students, teams | Meeting-focused, conferencing integrations ✨ |
| Picovoice Leopard | On-device SDKs, low latency, privacy-first | SDK support, local processing | Free non-commercial plan, commercial paid 💰 | Developers, privacy-sensitive users | Local batch/stream STT, multi-platform ✨ |
Navigating the landscape of speech recognition technology reveals a powerful truth: there is no single "best" solution for everyone. As we've explored, the ideal tool is not about finding a one-size-fits-all champion but about identifying the software that perfectly aligns with your specific project requirements, technical skill set, and operational constraints. Your journey to finding the best free speech recognition software concludes with a careful evaluation of your own needs against the diverse capabilities of the tools we've detailed.
We've covered a wide spectrum, from the unparalleled offline accuracy of OpenAI's Whisper to the lightweight, on-device efficiency of Vosk and PocketSphinx. We've seen how legacy academic powerhouses like Kaldi and CMU Sphinx continue to offer deep customization for researchers, while modern OS-integrated tools like Apple Dictation and Windows 11 Voice Access provide seamless, out-of-the-box utility for everyday users. For those needing enterprise-grade features, the generous free tiers from cloud giants like Microsoft Azure, Google Cloud, and Amazon Transcribe offer a direct pathway to scalable, production-ready systems.
To move from analysis to action, you must filter these options through the lens of your unique use case. The selection process becomes much clearer when you answer a few fundamental questions. This structured approach will help you eliminate unsuitable options and zero in on the perfect fit.
Consider these critical decision points:
Once you've narrowed down your choices, remember that "free" often comes with its own set of costs. Self-hosted solutions require an investment in hardware resources (CPU/GPU) and the technical expertise to deploy and maintain the models. Cloud APIs, while free to start, operate on a usage-based model that can incur costs as your application scales. Always review the terms of the free tier to understand its limits and anticipate future expenses.
Ultimately, the best free speech recognition software is the one that empowers you to achieve your goals efficiently and effectively. Whether you're building the next great voice-activated application, archiving a library of audio content, or simply looking for a better way to take notes, the right tool is waiting. By thoughtfully considering your specific needs regarding accuracy, latency, connectivity, and usability, you can confidently select and implement a solution that transforms spoken language into valuable, actionable data.
Ready to move beyond the limitations of free tiers and into a scalable, high-quality production environment without the enterprise price tag? Lemonfox.ai offers a developer-friendly Speech-to-Text API that is up to 6x cheaper than major competitors like OpenAI's Whisper API, providing an affordable and powerful bridge from experimentation to full-scale deployment. Explore our simple pricing and get started in minutes at Lemonfox.ai.
{kind=link}