First month for free!
Get started
Published 11/26/2025

The difference between robotic narration and a truly human-sounding voice is night and day. Think about a generic automated phone menu versus your favorite podcast host. One is stiff and functional; the other pulls you in, builds trust, and keeps you listening. Getting that realism right isn't just a "nice-to-have"—it's the key to creating digital experiences people actually connect with.
We’ve all heard those old text-to-speech (TTS) systems. They were famous for their flat, monotone delivery. Sure, you could make out the words, but there was zero life behind them. Modern TTS is all about closing that gap by capturing the tiny details that make a voice feel genuine.
This is more than just about sounding pleasant. For any business or creator, the quality of your voice directly shapes how people see your brand, how long they stay engaged, and how accessible your content is. A natural-sounding voice can make an audiobook captivating, an e-learning course stick, and an accessibility tool a source of comfort for those who depend on it.
The jump from robotic to realistic speech isn't magic; it's a science built on a few core elements. These are the ingredients that turn a string of text into a believable performance. If any of them are missing, the whole thing falls flat.
We've summarized these crucial components below.
| Element | Description | Impact on Realism |
|---|---|---|
| Prosody | The rhythm, stress, and flow of speech—the "music" of a sentence. | Makes speech sound natural and fluid, not like a list of words being read. |
| Intonation | The rise and fall of pitch to convey meaning, like a higher pitch for a question. | Crucial for conveying intent, emotion, and context correctly. |
| Timing & Pacing | The use of natural pauses for breath, emphasis, or to let a point sink in. | Prevents a monotonous drone and makes the audio much easier to follow. |
| Expressiveness | The ability to convey subtle emotions like warmth, excitement, or empathy. | Adds a layer of connection that makes the listening experience far more immersive. |
The real challenge isn't just about clear pronunciation. It's about capturing the emotional and rhythmic texture of a real human conversation. When a voice gets the prosody and intonation right, it stops feeling like a tool and starts feeling like a companion.
This push for realism has lit a fire under the industry. The global text-to-speech market, valued at around USD 3.45 billion, is on track to explode to an estimated USD 28.02 billion. This growth is all driven by one thing: the demand for more natural, less robotic digital interactions. You can dig deeper into these market trends and what they mean for technology.
At the end of the day, the search for the perfect human sounding text to speech voice is about making technology feel less like a machine and more like us. When you can’t tell the difference between a synthetic voice and a real one, the barriers come down, and digital interactions finally start to feel natural.
The leap from robotic narration to genuinely human-sounding text-to-speech wasn't a small step; it was a complete paradigm shift. Early TTS systems were clunky, piecing together pre-recorded sounds like a clumsy audio collage. The results were often choppy and jarringly unnatural.
Today’s systems are far more sophisticated. Instead of just reassembling sound clips, they generate audio from the ground up. They learn the incredibly complex patterns of human speech to create something entirely new and fluid. This massive improvement is almost entirely thanks to neural networks.
At the core of today's most lifelike synthetic voices is Neural Text-to-Speech (Neural TTS). These models don't rely on a rigid, hand-picked library of audio snippets. Instead, they learn directly by analyzing thousands of hours of real human speech—absorbing the pitch, rhythm, pauses, and subtle emotional cues that make us sound human.
Think of it like an apprentice painter studying under a master. At first, they might just copy brushstrokes. But over time, they start to understand the why behind the technique—the emotion, the composition, the intent. They internalize these principles to create original art. Neural TTS models do the exact same thing with sound, learning the deep structure of what makes a voice authentic.
This is all about mastering the core components of natural speech.
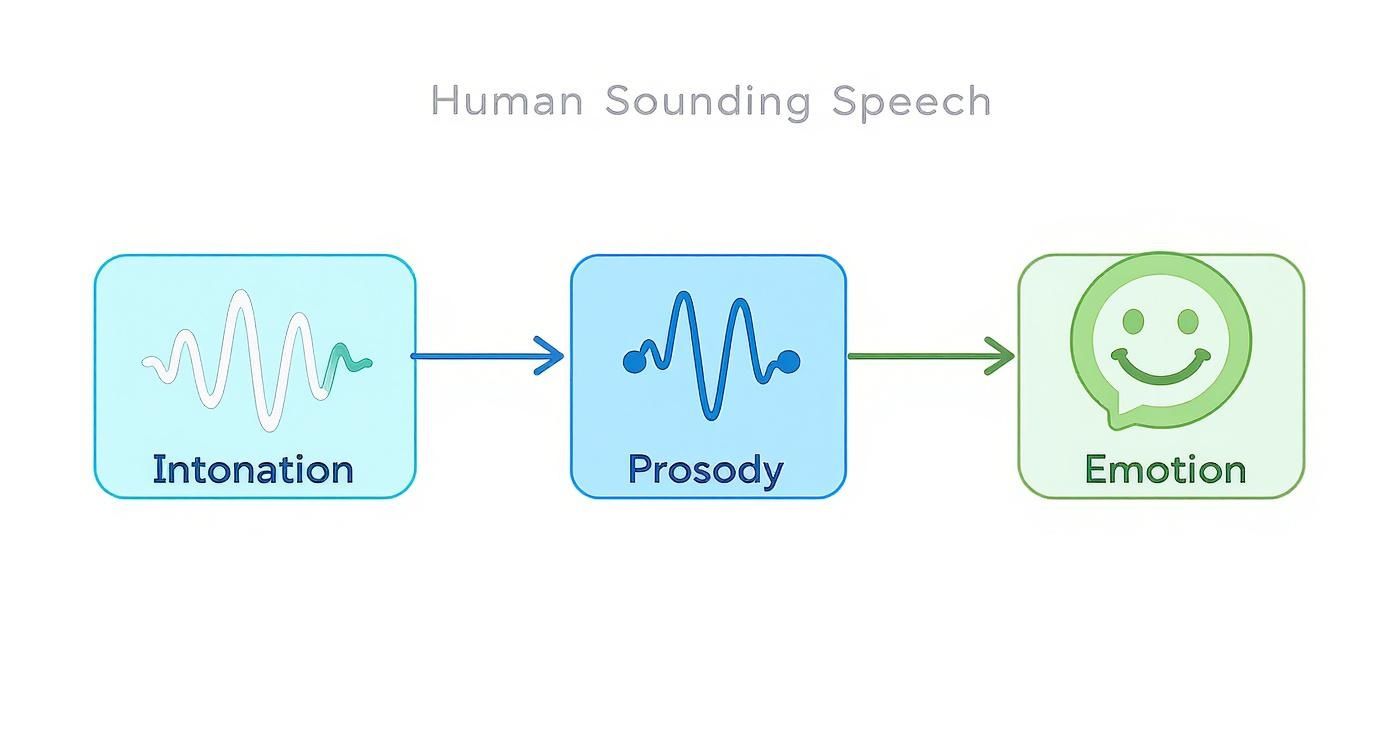
As you can see, it's the perfect blend of intonation (the rise and fall of the voice), prosody (the rhythm and stress), and emotional color that turns a flat reading into a believable performance.
So how does the AI actually create the sound you hear? It's a fascinating two-step dance.
First, one part of the neural network takes your text and creates a detailed acoustic blueprint called a spectrogram. Think of this as the sheet music for the voice. It contains all the instructions for pitch, timing, and volume, but it isn't actual sound yet.
That’s where the second part, the vocoder, steps in. The vocoder acts like a digital voice box. It takes that complex spectrogram and synthesizes the final, audible waveform that comes out of your speakers.
Key Takeaway: Neural TTS doesn't just "play back" words. It generates entirely new audio based on a deep understanding of human speech, first translating text into a rich acoustic map and then using a vocoder to turn that map into sound.
For a long time, vocoders were the weak link in the chain, often adding a metallic, buzzy quality that screamed "robot." But major breakthroughs like WaveNet and HiFi-GAN changed the game entirely. These modern vocoders are capable of producing incredibly high-fidelity audio, capturing the rich textures and subtle imperfections that make a voice sound real.
This rapid progress is fueled by deep learning architectures like Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs). These complex models are what give a TTS system the power to mimic human intonation and prosody with uncanny accuracy. They're the reason we’ve moved from voices that are merely understandable to voices that are genuinely lifelike.
These sophisticated AI models are responsible for the tiny, nuanced details that convince our brains we're hearing a real person. At the foundation of all this is the field of Natural Language Processing (NLP), which focuses on teaching computers to understand and interpret human language—a crucial prerequisite for speaking it convincingly.
Ultimately, today's best TTS technology is a powerful combination of several elements working in perfect harmony:
Together, these components have pushed text-to-speech beyond simple utility into the realm of truly expressive and engaging communication.
So, what separates a truly human-sounding voice from a robotic imposter? It’s not just about a gut feeling. While our ears are pretty good judges, the industry has developed some solid, objective ways to measure and compare human sounding text to speech quality.
Think of it this way: you wouldn't buy a car without looking at performance specs. The same logic applies here. These evaluation methods give you the data to confidently compare different TTS providers, ensuring you pick a voice that actually connects with your audience instead of just reading words off a screen.
Let's pull back the curtain on the key tests that help us sort the truly lifelike voices from the ones that are just functional.
The most trusted and widely used metric in the field is the Mean Opinion Score, or MOS. It’s a deceptively simple test that gets to the heart of the matter by asking real people a straightforward question: How good does this sound?
In a typical MOS test, a panel of human listeners rates a series of audio clips on a scale from 1 (bad) to 5 (excellent). All those scores are then averaged to create one single, powerful number that reflects the voice's overall perceived quality.
A MOS score of 4.0 or higher is the benchmark for a high-quality, natural-sounding voice. The best neural TTS systems consistently hit this mark, with some even getting close to the 4.5 score that authentic human speech typically receives.
This human-centric approach is so valuable because it catches all the subtle stuff that algorithms might miss—the natural rhythm, the believable intonation, and whether the voice is genuinely pleasant to listen to.
MOS is great for grading a single voice on its own merits, but what happens when you’re stuck between two really good options? That’s where comparison tests like ABX testing shine. They are designed for a simple purpose: can a listener reliably tell two audio samples apart?
The setup is pretty direct:
If people can consistently pinpoint which is which, it confirms there's a noticeable difference in quality. It’s an incredibly useful tie-breaker when you need to make a final call between two top contenders.
When you’re listening to a TTS voice, you’re actually judging two separate things at once, and it’s crucial to understand the difference: intelligibility and naturalness. A voice can be great at one and terrible at the other.
Intelligibility: This is the baseline. Can you understand every word clearly? A highly intelligible voice gets the message across without any ambiguity, even if there’s background noise. It’s about clarity.
Naturalness: This is the magic. Does the voice sound like a real person having a conversation? This covers all the nuances we've talked about—the prosody, the cadence, and the emotional color. A voice can be perfectly clear but still sound boring and robotic if it lacks naturalness.
For any TTS system to be worth its salt, it has to deliver on both fronts. You need the crystal-clear delivery of high intelligibility fused with the engaging, lifelike quality of naturalness. This perfect balance is what separates a good human sounding text to speech engine from a great one.
To help clarify these testing methods, here’s a quick breakdown of when to use each one.
| Method | What It Measures | Best Use Case |
|---|---|---|
| Mean Opinion Score (MOS) | Overall subjective quality and listenability, rated by humans on a 1-5 scale. | Establishing a baseline quality score for a single TTS voice or system. |
| ABX Testing | The perceivable difference between two distinct audio samples (A and B). | Making a final decision between two very similar, high-quality TTS voices. |
| Intelligibility Tests | How accurately and easily listeners can comprehend the spoken words. | Ensuring a voice is clear enough for critical applications, like public announcements or accessibility tools. |
Ultimately, choosing the right evaluation tools helps you look past the marketing and find a voice that achieves that critical blend of clarity and humanity.
Okay, let's get down to brass tacks. Moving from the "what" and "why" of TTS to the "how" requires a solid game plan. Integrating a truly human-sounding text-to-speech engine isn't just a matter of calling an API and hoping for the best. It’s a process that demands a thoughtful approach to data, fine-grained control, and performance.
Think of this section as your field guide for a real-world TTS implementation, walking you through the critical steps from start to finish.
If you’re building a custom voice from scratch, everything—and I mean everything—comes down to the quality of your source audio. The old saying "garbage in, garbage out" has never been more true. A neural TTS model learns every single detail from the data you feed it, including background hums, microphone static, and choppy delivery.
To give your project a fighting chance, your audio dataset has to be pristine. That means recording in a professional, sound-treated space with high-fidelity equipment. For many, this is the most demanding part of the process, but skimping here will guarantee a robotic or flawed synthetic voice.
Key Takeaway: When it comes to a premium custom voice, it's not about the sheer quantity of audio data—it's about impeccable quality. A few hours of crystal-clear, consistently delivered speech will always beat hundreds of hours of noisy, inconsistent recordings.
Once you have a solid base voice, the real fun begins. You don't just want your app to read text; you want it to perform it. This is exactly where Speech Synthesis Markup Language (SSML) comes in, and it's an absolute game-changer. SSML is an XML-based language that lets you direct the TTS engine with surgical precision.
Instead of just sending plain text, you use SSML tags to manipulate key elements of the speech.
For instance, look at the difference between this plain text input:"I can't believe we won."
And this far more expressive SSML version:
I
The second version gives the AI explicit directions, leading to a delivery that sounds worlds more dynamic and human. Learning to wield SSML effectively is what separates a voice that merely reads from one that truly communicates.
Even with a top-tier model and expert SSML tagging, a little post-processing can take the final audio from good to genuinely great. This step is all about applying audio engineering techniques to polish the sound, much like a photographer edits a raw photo to make the colors pop.
Common post-processing tricks include:
These finishing touches add a professional sheen that makes a huge difference to the end user.
One of the most crucial decisions you'll face is the constant tug-of-war between audio quality and response time, or latency. The most advanced models that produce jaw-droppingly realistic audio often demand more processing power, which can introduce a small delay.
This reality forces you to make a strategic choice:
Figuring out this balance is a core part of designing a successful voice application. While the technology is constantly improving and closing this gap, it’s still a key consideration for developers today. The demand for these solutions is exploding; the global TTS market is projected to skyrocket from USD 3.6 billion to USD 14.6 billion. You can learn more about the growth of text-to-speech AI here. Understanding these practical trade-offs is essential to building a solution that meets both your quality standards and your users' need for a responsive experience.
All the theory in the world is great, but eventually, you have to pick a tool and start building. When you start looking, you’ll find the market for human sounding text to speech is a crowded space. The big cloud providers offer incredibly powerful tools, but they often come with enterprise-level price tags and a steep learning curve. For a startup, an independent developer, or any business trying to scale responsibly, that can be a deal-breaker.
This is where a new wave of TTS providers is making a real difference. They’re focused on making high-quality voice tech accessible, affordable, and respectful of user privacy. If your project needs a great-sounding voice but can't justify a massive budget, a solution like Lemonfox.ai is built for you. It’s designed to level the playing field.
Look, the giant cloud platforms are amazing, but their pricing can be a labyrinth, and costs can spiral quickly as you grow. Beyond the price, sending potentially sensitive text to a third-party server for processing is a non-starter for many apps, especially in fields like healthcare or customer service where privacy is paramount.
Lemonfox.ai was built to solve exactly these problems. It really shines in a few specific situations:
The Bottom Line: The "best" TTS isn't always the one with the longest feature list. It's the one that fits your project's real-world constraints. For many, that winning combination is low cost and high privacy.
One of the biggest advantages of a developer-focused platform is just how easy it is to get started. The whole point is to minimize friction and let you go from idea to implementation as fast as possible. A good TTS API should be dead simple, with clear documentation and endpoints that make sense.
For instance, plugging Lemonfox.ai into your project usually takes just a handful of lines of code. Whether you're a Python pro or a JavaScript developer, the process is refreshingly direct.
Here’s a conceptual Python example to show you what I mean:
import requests
api_key = "YOUR_LEMONFOX_API_KEY"
headers = {"Authorization": f"Bearer {api_key}"}
data = {
"voice_id": "stellina-en-us", # An example voice
"text": "Hello, world! This is a test of a truly human sounding text to speech API."
}
response = requests.post("https://api.lemonfox.ai/v1/tts", headers=headers, json=data)
if response.status_code == 200:
with open("output.mp3", "wb") as f:
f.write(response.content)
print("Audio file created successfully!")
This straightforward approach lets you bolt voice generation onto your app in no time. To see all the parameters and guides, you can dive into the official Lemonfox.ai API documentation.
Once you remove the barriers of cost and complexity, you can start getting really creative with voice. The possibilities for affordable, high-quality TTS are practically endless.
Here are just a few ideas to get the gears turning:
At the end of the day, having an affordable and private human sounding text to speech tool in your back pocket lets you build richer, more engaging, and more accessible products for everyone.
The world of human-sounding text to speech is moving incredibly fast. The voices we hear today are already impressive, but they're just a glimpse of what's to come. We're heading toward a future where synthetic voices aren't just realistic—they're dynamic, adaptive, and woven seamlessly into how we interact with technology.
One of the most exciting areas of research is real-time emotional adaptation. Picture a customer service bot that actually hears the frustration in your voice and immediately adjusts its own tone to be more soothing and patient. This isn't just a sci-fi concept; it's what developers are actively working on right now. The next wave of TTS won't just read words; it will interpret the context of a conversation and respond with genuine emotional nuance.
Another game-changer is the rapid improvement in zero-shot voice cloning. This mind-blowing tech allows an AI to hear just a few seconds of someone speaking and then replicate their voice with stunning accuracy. The creative doors this opens are huge—imagine personalizing your GPS with a parent's voice or having a digital assistant that sounds exactly like you.
Of course, with great power comes great responsibility. As these tools become easier to access, they raise serious ethical questions about misuse and deepfakes. The industry is grappling with this, developing safeguards like digital watermarking and other detection methods to ensure this technology is used for good.
The next generation of voice AI will be defined by its ability to listen, adapt, and respond with genuine emotional intelligence. The goal is no longer just to mimic a human, but to interact like one.
Looking at the big picture, these advances in voice are part of a much larger trend. For example, the way AI integration in publishing is changing how books are produced and marketed shows us what's possible. The ability to generate high-quality, emotionally-aware audio on the fly will completely reshape content, from audiobooks to video game dialogue and interactive learning.
The journey to create a perfect synthetic voice is far from over, but every new breakthrough brings us one step closer. We're quickly approaching a future where the line between a real human voice and a generated one isn't just blurry—it's gone.
Diving into the world of human-sounding text-to-speech can spark a few questions, especially when you're getting ready to build. Let's tackle some of the common ones that pop up for developers and creators.
This really depends on what you're trying to accomplish. If you're looking to fine-tune an existing model or do a basic voice clone, you might get away with just a few hours of clean, high-quality audio. It's surprisingly little to get started.
But if you want to build a brand new neural TTS voice from the ground up? That’s a whole different ballgame. You're talking about a massive undertaking that often requires hundreds, sometimes even thousands, of hours of professionally recorded speech from one person. This is the only way to capture all the subtle details that make a voice unique.
Key Takeaway: When it comes to custom voices, quality trumps quantity every time. A small, pristine audio dataset will always give you better results than a huge, noisy one.
Think of SSML (Speech Synthesis Markup Language) as a director's script for your TTS engine. It's a simple, XML-based language that lets you go beyond plain text and control the performance of the synthesized voice.
With SSML tags, you can tell the AI exactly how to deliver its lines. You can:
This is the secret sauce for turning a flat, robotic reading into something that sounds genuinely human and emotionally engaging.
Absolutely. Many modern TTS APIs are built for speed, making them perfect for real-time uses like chatbots and voice assistants. There is, however, a slight trade-off to be aware of.
The most expressive, highest-fidelity voice models can sometimes introduce a tiny bit of latency. On the other hand, models built purely for speed might not have the same vocal richness. When you're building a conversational tool, check the API's latency benchmarks. You need to make sure the response is quick enough to feel natural and keep the conversation flowing smoothly.
Ready to bring an affordable, privacy-first TTS solution into your next project? With Lemonfox.ai, you get access to premium, human-like voices through a dead-simple API, all at a fraction of the usual cost. Start building with our developer-friendly tools today.