First month for free!
Get started
Published 9/24/2025
At its most basic, machine learning for speech recognition is what allows a computer to understand and write down what we say. The whole idea is to train algorithms on massive audio datasets, teaching them to pick out the patterns, sounds, and words that make up human speech and convert it all into text.
Before you could ask your phone for directions or have a meeting transcribed in real-time, the journey of teaching machines to listen began with computers the size of a room. The earliest pioneers weren't tinkering with sophisticated neural networks; they were wrestling with fundamental hardware to solve one huge problem: how to make a machine hear.
Looking back, you can see a clear evolution from rigid, rule-based systems to the flexible, intelligent models we have today. The initial challenge was enormous. How do you take something as fluid and analog as a soundwave and turn it into the clean, digital information a computer can understand?
The story really gets going back in the 1950s. In 1952, Bell Labs unveiled "Audrey," one of the first systems of its kind. Audrey could recognize single spoken digits, but it was a massive piece of hardware that did so by analyzing the unique resonant frequencies in each sound. A decade later, IBM's "Shoebox" machine, a highlight at the 1962 World's Fair, could understand a whopping 16 English words. You can find more on these early days in the history of speech recognition on Wikipedia.
Of course, these early systems were incredibly limited. They were speaker-dependent, meaning you had to train them on one person's voice, and their vocabularies were tiny. Still, they were critical proofs of concept that proved machine-based listening was actually possible.
Think of this early phase like teaching a toddler to identify shapes. The system could match the spoken digit 'one' to its template, but it had no clue what 'one' meant in a broader context, nor could it recognize the digit if you said it a little differently.
This diagram shows the basic architecture that most speech recognition systems still follow in one form or another.
You can see how the raw audio is first broken down into key features. From there, an acoustic model figures out the sounds, and a language model pieces them together into something that makes sense.
The real breakthrough came in the 1980s with the rise of Hidden Markov Models (HMMs). This was a massive pivot. We moved away from trying to perfectly match sounds to rigid templates and started embracing a much smarter, statistical approach.
An old template-based system would ask, "Does this sound exactly like my recording of the word 'hello'?" An HMM system, on the other hand, asks, "Given this series of sounds, what is the most likely sequence of words that produced it?" That change was everything. It suddenly gave systems the flexibility to handle the natural variations in how people talk—from different accents to speaking speeds.
This statistical foundation laid the groundwork for the deep learning explosion that came later. By learning to think in probabilities instead of absolutes, machines took a giant leap toward truly understanding us. It was this evolution that set the stage for the incredibly powerful models that define machine learning for speech recognition today.
To really get how a machine turns spoken words into text, we have to look under the hood at the different models that drive the whole process. These are the engines of Automatic Speech Recognition (ASR), and each one has a unique way of tackling the incredible complexity of human speech. Think of them as a team of specialists, each bringing a particular skill to the job of listening and understanding.
Over the years, the field has moved from foundational statistical methods to intricate neural networks that feel much more like the human brain. This evolution is the reason today's voice assistants feel so natural compared to the clunky, robotic systems of the past.
Long before deep learning was on the scene, Hidden Markov Models (HMMs) were the backbone of speech recognition. They're built on a clever probabilistic idea. Imagine you’re trying to guess the weather (a hidden state) just by seeing what someone is wearing (an observable fact). If they have an umbrella and rain boots, you can infer it's probably raining, even if you can't see outside.
HMMs do something similar with speech. They treat the actual words someone is saying as a "hidden" sequence we want to figure out. The sounds the model hears—the raw acoustic signals—are the "observable" data. The HMM then calculates the most likely sequence of words that could have produced those specific sounds.
This approach was a huge leap. Back in the 1980s, HMMs allowed systems to expand their vocabularies from a few hundred words to several thousand, making them drastically more accurate. The rise of personal computing in the 1990s gave this a further boost, providing the power needed to run the complex calculations HMMs required.
As good as HMMs were, they had one big blind spot: a short memory. They could only analyze audio in small, isolated chunks. This is where Recurrent Neural Networks (RNNs) completely changed the game. RNNs are built from the ground up to handle sequences, which is exactly what a sentence is.
An RNN processes a sentence one word at a time, but—and this is the key—it remembers what it just heard. This memory, or "hidden state," allows it to build context. For example, to make sense of the command "Turn the lights on," the model has to remember "turn" and "lights" to correctly interpret "on."
A more advanced version, called a Long Short-Term Memory (LSTM) network, has an even better memory system. It can recall important context from much earlier in a sentence, which is crucial for understanding long, complex conversations.
While RNNs are brilliant at tracking sequences over time, Convolutional Neural Networks (CNNs) are masters of finding spatial patterns. They originally became famous for their uncanny ability to recognize objects in images, but it turns out that skill is incredibly useful for audio, too.
Here’s how it works: raw audio gets converted into a visual map called a spectrogram. It looks a bit like a heat map showing different sound frequencies over time. A CNN then scans this image, acting like a magnifying glass to spot tiny but critical acoustic features—like the distinct visual patterns that make up a "sh" sound versus an "ah" sound.
By spotting these patterns, CNNs help the system get a much clearer picture of the phonemes (the basic sound units) that form words. They are often paired with RNNs to create a system that’s the best of both worlds. You can see these principles at work in things like modern AI phone answering systems.
This visual map shows how raw audio data gets processed through different layers of a neural network before it finally becomes text.
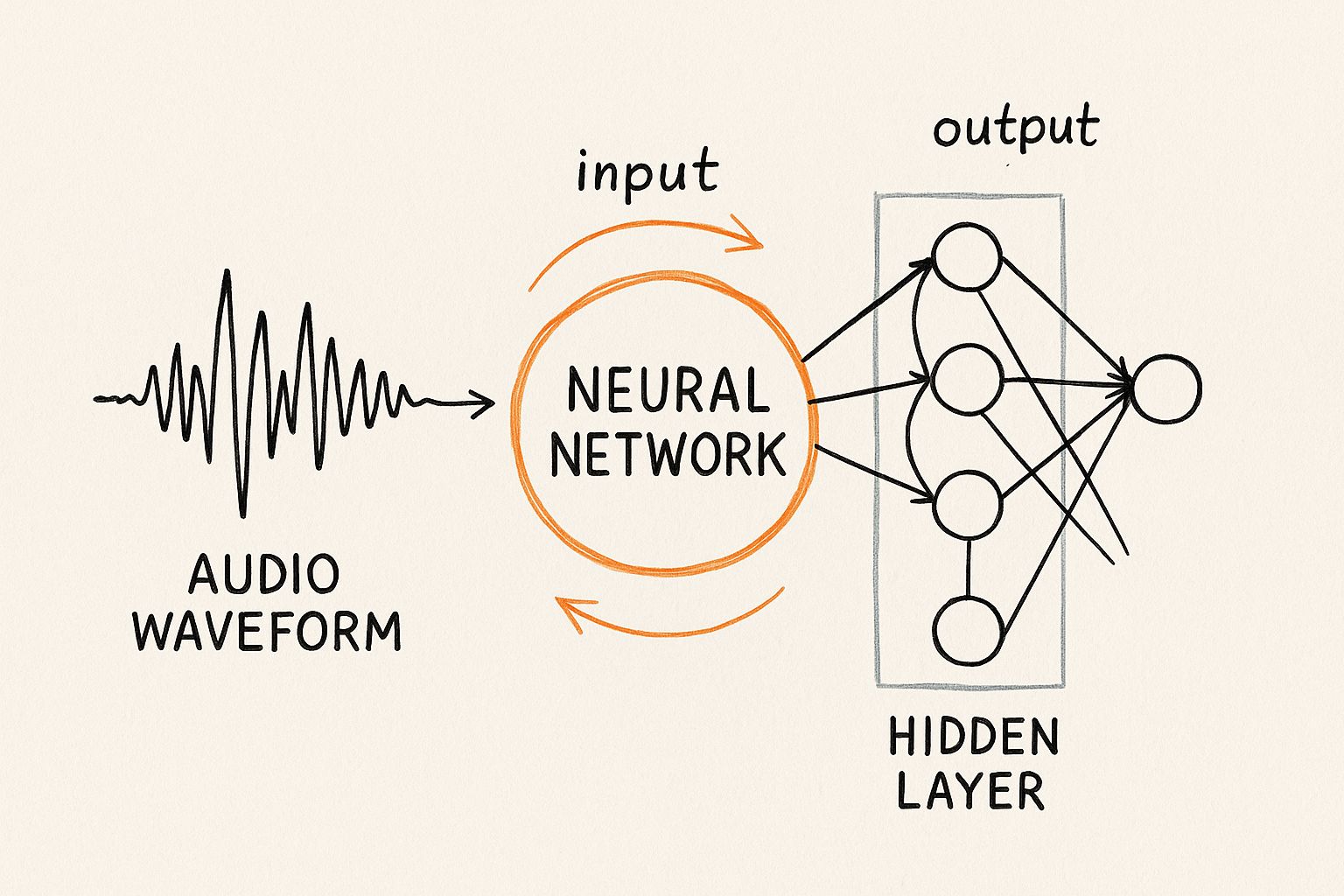
The diagram breaks down how a simple sound wave is transformed into complex, machine-readable features, showing the layered analysis that powers modern ASR.
The latest and most powerful player in the field is the Transformer model. Transformers brought a brilliant new concept to the table called the attention mechanism.
Think about how you listen to a long story. You don’t give every single word the same amount of importance. Your brain instinctively focuses on the keywords that carry the real meaning. The attention mechanism lets an ASR model do exactly that.
As a Transformer processes a sentence, it can weigh the importance of all the other words to understand the current one in its full context. This ability to look at the entire sentence at once, instead of just plodding along word by word, gives Transformers an incredible knack for handling ambiguity and complex grammar. It’s this technology that powers many of the most accurate and human-sounding ASR systems today.
To pull all this together, here’s a quick summary of how these different models stack up against each other. Each has its own strengths and is best suited for certain kinds of tasks.
| Model Type | Core Concept | Primary Strength | Common Application |
|---|---|---|---|
| HMM | Statistical probability; calculates the most likely sequence of hidden states (words) from observable data (sounds). | Computationally efficient and effective for smaller vocabulary tasks. | Early digital assistants and simple command-and-control systems. |
| RNN | Sequential processing with memory; processes data one step at a time while retaining context from previous steps. | Understanding time-based context in sequences like sentences. | Language modeling, early machine translation, and basic ASR. |
| CNN | Pattern detection in spatial data; identifies key features in visual representations of audio (spectrograms). | Excels at identifying localized acoustic features and phonemes. | Often used in hybrid models with RNNs for feature extraction. |
| Transformer | Attention mechanism; weighs the importance of all words in a sentence simultaneously to build deep context. | Unmatched understanding of long-range dependencies and complex grammar. | State-of-the-art transcription services, translation, and advanced chatbots. |
Understanding these core models helps demystify how speech recognition has evolved from a niche technology into something we rely on every day. Each new model built upon the last, bringing us closer to a machine that can truly listen and understand.
Turning a raw audio file into a clean text transcript isn't a single event—it's a journey. Think of it like teaching a person a new language by having them listen to native speakers for thousands of hours. You start with basic sounds, then words, and eventually, the model learns the grammar and context of spoken language. This entire pipeline, from messy audio files to a polished, intelligent model, involves a few critical stages.
Everything starts with data. Lots of it. Modern machine learning for speech recognition is incredibly data-hungry, often requiring millions of hours of audio to reach high accuracy. But it's not just about quantity; quality and diversity are what truly matter. The training data has to be a true reflection of the real world, complete with different accents, speaking speeds, and all sorts of background noise.
Before a model can even begin to learn, we have to translate raw soundwaves into a language it understands. This is called data preparation, and it's all about turning unstructured sound into structured, machine-readable information.
This process usually breaks down into a few key steps:
Why turn sound into a picture? It allows us to apply powerful computer vision techniques to the audio. The model can literally "see" the unique visual signature of different sounds—like the sharp, vertical line of a "t" sound versus the soft, hazy shape of an "s."
With our data neatly formatted, the next step is feature extraction. The truth is, not all information in an audio signal is useful. The hum of a refrigerator is just noise, but the subtle shifts in frequency that form vowels and consonants are the signal we care about.
Feature extraction is all about zeroing in on those crucial acoustic signals. We use techniques like Mel-Frequency Cepstral Coefficients (MFCCs) to highlight the parts of sound that are most important for human speech while pushing the irrelevant background noise to the side. This helps the model focus on what actually matters for understanding words.
A well-trained model doesn't just hear the audio; it learns to separate the speaker's voice from the noise. This is achieved by feeding it countless examples, allowing the algorithms to distinguish the essential features of speech from random environmental sounds.
Now we get to the heart of it: the training loop. This is where the model learns to connect acoustic patterns to written words. In more traditional systems, this was a job for two specialized components working in tandem.
The training itself is an iterative process. The model makes a guess, compares it to the correct transcript, and calculates how wrong it was using a loss function. A popular choice here is Connectionist Temporal Classification (CTC) Loss, which is great for handling the tricky alignment between audio that varies in length and text that's a fixed length.
An optimizer then nudges the model's internal settings to reduce that error. This loop of guessing, checking, and adjusting repeats millions of times, with the model getting a little bit smarter and more accurate with every single cycle.
So, you’ve trained a model on millions of audio clips. How do you actually know if it's any good? It's a lot like a student taking a test—the model needs a grade. In speech recognition, we use specific metrics to get an objective score, telling us precisely how well our machine is "hearing."
This isn't just a technical detail; it's a practical necessity. Businesses rely on these scores to pick the best ASR service for their needs. Developers live by them, tracking every tiny improvement as they tweak and retrain their models. Without these benchmarks, we’d just be guessing.
The go-to metric for grading ASR accuracy is the Word Error Rate (WER). You can think of WER as a simple "mistake counter." It works by comparing the model's transcription against a flawless, human-verified transcript and counts up three kinds of errors.
The formula is straightforward: add up all the errors (S + D + I) and divide by the total number of words in the original, correct transcript. The goal is always a lower WER, where 0% is a perfect score. In the real world, a system with a WER of 10% is often considered pretty solid for many uses.
Let's say the correct sentence is: "The quick brown fox jumps."
But the model's output is: "The a brown fox jumped."
Here, we have one substitution ("jumps" became "jumped") and one insertion (the extra "a"). That's two errors in a five-word sentence, which would result in a pretty high WER.
While WER is the industry benchmark, it doesn't always paint the full picture. Sometimes, other metrics are just as critical, depending on what you're building.
For languages with complex word structures or those that are more character-based, like Mandarin or Turkish, counting word errors can be misleading. This is where Character Error Rate (CER) comes in. Instead of counting whole words, CER tallies up mistakes at the individual character level, giving us a much finer-grained look at performance.
Accuracy is one thing, but speed is another. The Real-Time Factor (RTF) tells us how fast the model is. We calculate it by dividing the time it took to process the audio by the duration of the audio itself.
An RTF of 0.5, for example, means the model chewed through a 60-second audio file in just 30 seconds. For applications like live captioning or voice assistants, a low RTF isn't just nice to have—it's absolutely essential for the experience to feel instant and natural.
While the performance of today’s speech recognition models can seem almost magical, what happens in a quiet lab is a world away from the messy reality of everyday life. The real world is full of overlapping conversations, background clatter, diverse accents, and jargon that can easily trip up even the most sophisticated systems. These hurdles are the final frontier in the quest for truly seamless human-computer interaction.
One of the most classic and stubborn issues is the "cocktail party problem." Think about trying to follow one person's story in a crowded, noisy room. Your brain is a master at filtering out the clinking glasses and background chatter to focus on a single voice. Teaching a machine to do the same is one of the toughest challenges in machine learning for speech recognition.
This isn't just about loud environments, either. It’s also about separating multiple speakers who might be talking over each other. This requires more than just basic noise cancellation; it demands a deep understanding of unique voice patterns to untangle the conversation.
Beyond the noise, the sheer diversity of human speech itself presents another huge obstacle. A model trained primarily on one accent can stumble badly when it encounters another. The subtle differences in pronunciation, rhythm, and intonation can cause error rates to skyrocket.
This variability comes from all angles:
Successfully handling this diversity is what separates a good ASR system from a great one. A truly robust model must be trained on a massive and varied dataset that reflects the global tapestry of human voices, not just a narrow slice of it.
Another major roadblock appears when speech contains specialized vocabulary. A general-purpose model trained on everyday conversation will almost certainly fail when asked to transcribe a medical diagnosis or a legal argument. It has never encountered terms like "myocardial infarction" or "subpoena duces tecum" and will try to guess with more common, similar-sounding words.
Fortunately, the field is constantly coming up with clever solutions to these real-world problems. Researchers and engineers are using a range of machine learning techniques to make ASR models more resilient, adaptable, and accurate in just about any situation.
To deal with the cocktail party problem, engineers use advanced noise suppression algorithms trained to isolate human speech frequencies from ambient sounds. For multi-speaker environments, a technique called speaker diarization is crucial. It essentially answers the question, "Who spoke when?" by identifying and separating the distinct voices in an audio stream. The end result is a clean, speaker-labeled transcript.
When it comes to specialized language, the most effective strategy is fine-tuning. This involves taking a powerful, pre-trained model and continuing its training on a smaller, domain-specific dataset. By feeding it audio and transcripts filled with medical, legal, or financial jargon, the model quickly learns this new vocabulary and becomes an expert in that specific field.
To effectively navigate the complexities of converting spoken language to text, evaluating the best speech to text software solutions is essential for finding a tool that can handle these diverse challenges. These systems show just how far the technology has come in bridging the gap between controlled training environments and the beautifully unpredictable nature of human conversation.
If you think speech recognition is impressive now, just wait. The entire field is in the middle of a massive shift, moving far beyond just turning words into text and into a new territory of truly intelligent, natural interaction.
What we're seeing is a fundamental change in how the models themselves are built. The big move is toward end-to-end models, which are a complete rethink of the classic ASR pipeline. Instead of juggling separate acoustic, pronunciation, and language models, these new systems learn everything from a single, unified neural network. It's a cleaner approach that often delivers a serious boost in accuracy.
At the same time, not everything is about building bigger models in the cloud. A huge area of innovation is happening right on our devices with Edge AI. The idea is to create highly efficient, lightweight models that can run directly on your phone, in your car, or on your smart speaker.
This isn't just a novelty; it solves two of the biggest problems in speech tech:
This shift toward on-device processing will make our interactions with technology feel more immediate, reliable, and trustworthy, especially when you don't have a stable internet connection.
The ultimate goal is to move beyond just understanding words to grasping intent, context, and even emotion. Future systems won't just hear what you say; they will understand how you say it.
This deeper, more human-like understanding is where things get really exciting. It's the key to unlocking hyper-personalized assistants that anticipate your needs, real-time translation tools that capture cultural nuance, and a form of human-computer interaction that feels less like giving commands and more like having a genuine conversation. Speech technology is evolving from a simple tool into a true conversational partner.
As you dive into the world of speech recognition, a few key questions tend to pop up again and again. Let's break down some of the most common ones to give you a clearer picture of how this technology really works.
Think of a traditional speech recognition system as having two distinct parts. The acoustic model is the "ears" of the operation. Its only job is to listen to raw audio and figure out the fundamental sounds—or phonemes—that make up the speech. It doesn't know what words mean; it just translates soundwaves into phonetic building blocks.
The language model, on the other hand, is the "brain." It takes that string of phonemes from the acoustic model and pieces together the most likely sequence of words. For instance, it's the language model that knows "how are you" makes a lot more sense than "how oar shoe," even if they sound almost identical to the acoustic model. It's worth noting, though, that many modern end-to-end systems now blend these two functions into a single, unified network.
The short answer? Human speech is incredibly messy and diverse. We all have different accents, pitches, and speaking speeds. Then, throw in all the unpredictable background noise of the real world—a barking dog, a passing siren, a busy café—and the complexity skyrockets.
A model needs to learn from millions upon millions of examples to have any hope of performing well across all these different speakers and environments.
Without a massive and varied dataset, the model would only perform well for the specific voices and conditions it was trained on. It's this sheer volume of data that gives a model the robustness to handle the vast spectrum of human communication, preventing it from failing in everyday scenarios.
This extensive training is what allows a system to generalize and become truly useful.
Connectionist Temporal Classification (CTC) Loss is a clever algorithm that solves one of the biggest headaches in training speech models: unaligned data. It’s nearly impossible to perfectly line up every millisecond of an audio clip with the exact letter or phoneme being spoken.
CTC gets around this beautifully. It allows the model to predict "blanks" in between characters, effectively giving it breathing room. Then, it calculates the probability of all the possible ways the audio could align to produce the correct final text.
This was a game-changer because it removed the need for perfectly synchronized audio-text data, which is incredibly difficult and expensive to create. It’s one of the key reasons why modern machine learning for speech recognition can be trained so effectively on huge, real-world datasets.
Ready to integrate powerful, accurate transcription into your application? With Lemonfox.ai, you can access a state-of-the-art Speech-To-Text API for less than $0.17 per hour. Get started today with a free trial and see the difference for yourself.