First month for free!
Get started
Published 10/8/2025
When we talk about open source speech-to-text, we're talking about something fundamentally different from the paid, black-box services many people are used to. At its core, it's a collection of code and pre-trained models that anyone can use—for free—to turn spoken words into written text.
This approach gives developers total control over their data and the freedom to customize everything. It’s a world away from proprietary APIs, prioritizing transparency and flexibility so anyone can build, tweak, and launch their own voice technology without being tied to licensing fees.

Voice isn't a futuristic novelty anymore; it's woven into the fabric of our daily tech interactions. Whether we're asking a smart speaker for a weather update or dictating a quick note into our phone, we simply expect our devices to understand what we're saying. Open source speech-to-text (STT) is the community-driven engine that makes much of this possible.
Imagine it’s like a massive, global potluck for language technology. Instead of one company hiding its secret recipe for converting audio into text, the entire developer community shares and improves upon their "recipes" out in the open. This collaborative spirit has made powerful voice tools available to everyone, not just the big tech giants.
The appetite for voice-powered apps is growing like crazy. From startups and independent researchers to massive corporations, everyone is looking for ways to build in voice commands, transcription features, and better accessibility tools. This demand is fueling a huge market expansion.
The global speech-to-text API market was valued at USD 3.813 billion in 2024 and is expected to climb to USD 8.569 billion by 2030, growing at a compound annual rate of 14.1%. This isn't just a trend; it's a fundamental shift driven by the explosion of voice-enabled devices and applications. You can dig into a detailed market analysis over on Grand View Research.
For innovators, open source STT provides a vital pathway away from proprietary, locked-down solutions. It’s a way to build without worrying about restrictive licenses or sending sensitive user data to a third-party company.
The key advantages pushing its adoption are clear:
Open source speech-to-text truly democratizes voice technology. It shifts the power from a handful of gatekeepers to a global community of builders, ensuring innovation remains accessible and can be adapted to countless unique needs.
Getting a handle on this technology is no longer just for hardcore coders. It's essential for anyone who wants to create modern, voice-powered experiences without being stuck inside a closed ecosystem. To see the bigger picture, it's helpful to understand the rise of voice-activated interfaces and how we got here.
Ever wonder what actually happens when you talk to your phone or smart speaker? It feels like magic, but the journey from your spoken words to the text on your screen is a fascinating, multi-step process. An AI model has to painstakingly deconstruct your voice, piece by piece, to figure out what you're saying. This process is the engine behind any open source speech to text system.
Think of it like putting together a puzzle, but without the picture on the box. The AI doesn't "hear" words like we do. It gets a raw audio file—a messy jumble of soundwaves—and has to meticulously assemble it into coherent language. It does this in three main stages, with each one building on the last to get to the final transcription.
First things first, the machine has to "listen." Your voice is an analog wave, which is completely alien to a computer. So, the system's initial job is to translate it into a digital format it can actually work with.
This is called feature extraction. The system chops the continuous audio into tiny, millisecond-long chunks. For each of these little slices of sound, it analyzes core properties like pitch, tone, and frequency. It then converts these properties into a string of numbers called a feature vector.
It’s a bit like describing a song to someone who can't hear it. You wouldn't just play the whole thing. You'd break it down: "It starts with a low bass note, then a high-pitched synth, and then a steady drumbeat." That's what the AI is doing—creating a detailed, numerical "script" of the sound, moment by moment. This digital data is the raw material for everything that follows.
With the audio now digitized, the acoustic model steps in. This is where the AI gets down to the nitty-gritty of human speech. Its job is to map those numerical feature vectors to the specific sounds, or phonemes, that make up a language.
Phonemes are the fundamental building blocks of speech—think of them as the "alphabet of sound." The word "cat," for example, is built from three phonemes: "k," "æ," and "t." The acoustic model, which is usually a deep neural network, has been trained on thousands of hours of labeled audio to get incredibly good at recognizing these individual sounds.
A neural network is a system modeled loosely on the human brain. It learns to spot patterns by sifting through massive amounts of data, constantly tweaking its internal connections until it can reliably connect an input (a soundwave) with the correct output (a phoneme).
When your digitized voice hits the acoustic model, the neural network starts making educated guesses. It might hear a sound and decide there's a 70% chance it's a "k" sound and a 30% chance it's a "g." It runs this probability game for every tiny slice of audio, creating a long stream of likely phonemes.
The acoustic model gives us the raw sounds, but the language model provides the context, grammar, and common sense. This is the final and perhaps most crucial piece of the puzzle. It acts like a skilled editor, taking the messy stream of probable phonemes and figuring out which combinations form actual words and logical sentences.
For instance, the acoustic model might output phonemes that could be interpreted as "eye scream" or "ice cream." The language model, having been trained on billions of sentences from books and the internet, knows that "ice cream" is a far more common phrase. It calculates the probability of different word sequences to find the most plausible one.
This is also how the system can tell the difference between "write" and "right," or predict that a sentence starting with "Let's go to the..." is more likely to end with "park" than "parakeet."
The entire process of setting up these models on your own system follows a pretty straightforward workflow. The infographic below shows the typical steps you’d take to get an open source speech-to-text tool up and running.
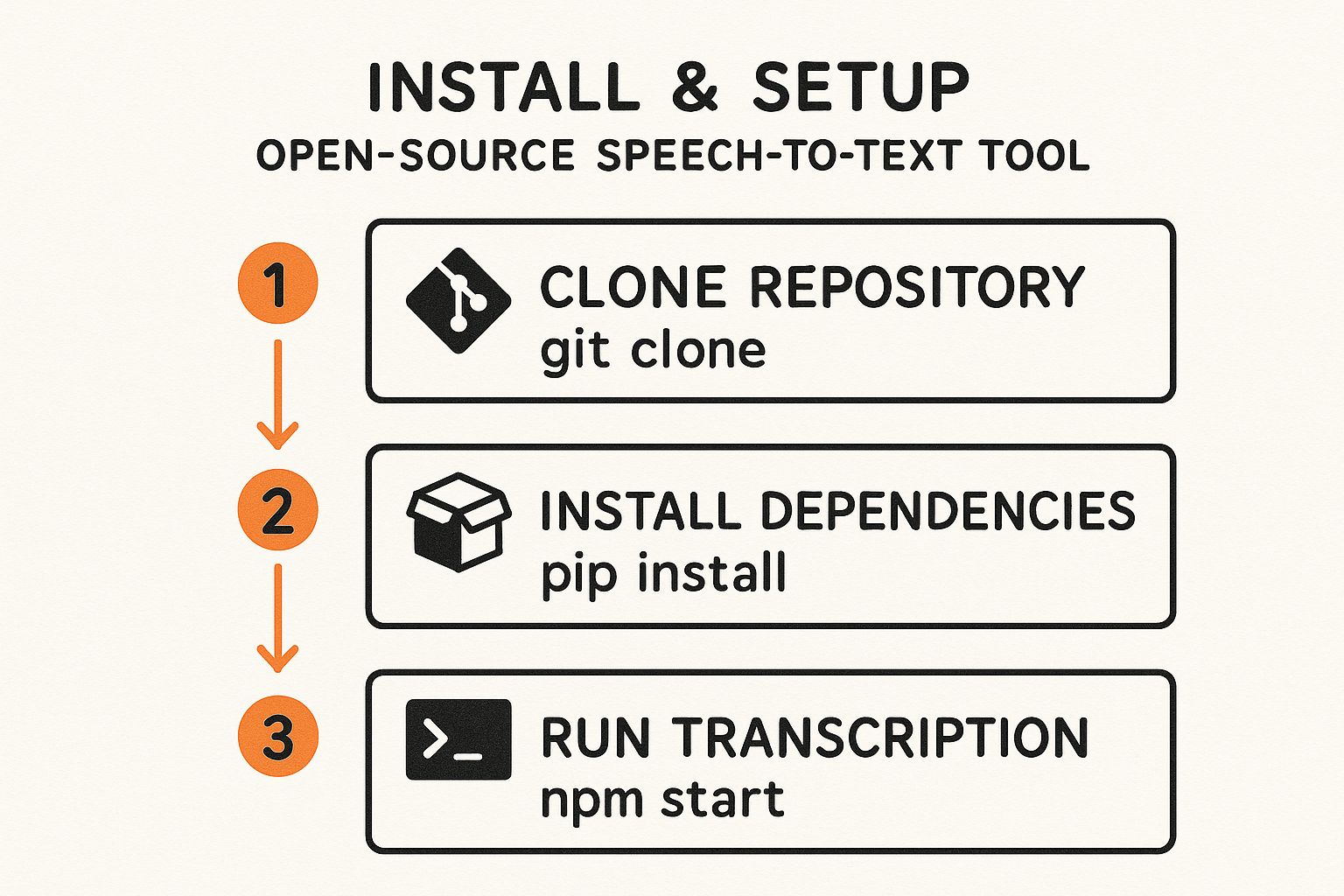
This simple three-step process—cloning the code, installing dependencies, and running the model—is your entry point to using these powerful systems on your own hardware.
When you start digging into the world of open source speech-to-text, you find a ton of powerful tools, each with its own personality. These aren't just side projects from hobbyists; they're serious, production-ready models built by big names like OpenAI, Meta, and Nvidia. Getting to know the major players is the first step in picking the right engine for whatever you're building.
Let's walk through some of the most popular and influential models out there. We'll look at where they came from, what makes them tick, and where they really excel. The goal isn't to find one "best" model, because that doesn't exist. It's about finding the best fit for your specific needs, whether that's real-time transcription, handling multiple languages, or something else entirely.
When OpenAI dropped Whisper in 2022, it was a game-changer for open source transcription. It was trained on an absolutely massive and diverse dataset—680,000 hours of multilingual audio scraped from the web. Because of this, Whisper’s biggest claim to fame is its incredible ability to understand dozens of languages, accents, and dialects straight out of the box.
It’s also surprisingly good at handling background noise and understanding technical jargon, which makes it a fantastic all-rounder. Whisper isn’t a one-size-fits-all model, either. It comes in different sizes, from tiny versions that can run on a laptop to much larger, more accurate models for heavy-duty work.
You can find all the different Whisper models over on Hugging Face, which has become the go-to hub for open source AI.
This collection shows just how flexible the Whisper family is, laying out the different sizes and their intended uses. The community has also built a whole ecosystem of tools around it, so getting it integrated into a project is pretty straightforward.
Meta AI’s Wav2Vec2 takes a completely different path. Its big idea is learning from huge amounts of unlabeled audio. Think of it like a baby learning the sounds of a language just by listening to people talk, long before they can connect those sounds to written words.
This self-supervised learning approach makes Wav2Vec2 incredibly flexible. It does require an extra step called "fine-tuning" to actually transcribe a specific language, but this two-stage process allows it to achieve phenomenal accuracy, even for languages that don't have a lot of training data available.
Wav2Vec2’s strength is its adaptability. It first learns the basic patterns of speech from raw audio, then uses a smaller, labeled dataset to get really good at specific transcription tasks. This makes it a beast for custom applications.
This model is a top choice if you need to build a highly specialized system for a niche field, like medical dictation or transcribing legal depositions. For example, developers are building free AI medical scribe tools that rely on this kind of specialized speech-to-text to help doctors with their clinical notes.
To make sense of the options, it helps to see them side-by-side. Each model brings something different to the table, whether it’s out-of-the-box performance, customizability, or raw power.
This table compares key features of popular open source STT models to help developers and businesses choose the right solution for their needs.
| Model Name | Primary Developer | Key Strengths | Best For | License Type |
|---|---|---|---|---|
| Whisper | OpenAI | Excellent multilingual support, robust in noise | General-purpose transcription, multilingual apps, ease of use | MIT License |
| Wav2Vec2 | Meta AI | High accuracy after fine-tuning, self-supervised | Custom solutions, specialized domains (e.g., medical), low-resource languages | Apache 2.0 |
| Granite Speech | IBM | Very low Word Error Rate (WER), high accuracy | Enterprise-grade applications where accuracy is paramount | Apache 2.0 |
| Parakeet TDT | Nvidia | High accuracy with fewer parameters, efficient | Real-time transcription, applications on resource-constrained hardware | Nvidia Open Model License |
| Kaldi | Community-led | Highly flexible and powerful toolkit | Academic research, building custom STT systems from scratch | Apache 2.0 |
| SpeechBrain | Community-led | Modern, easy-to-use PyTorch toolkit | Rapid prototyping, various speech tasks beyond transcription | Apache 2.0 |
As you can see, the "best" model really depends on your project's specific goals—balancing accuracy, speed, and the effort you're willing to put into customization.
The open source community never sleeps, and new and improved models are always popping up. The friendly competition between the tech giants has kicked progress into high gear, making high-quality transcription more accessible than ever.
For instance, IBM's Granite Speech model achieves a remarkably low word error rate (WER) of just 5.85%, while Nvidia's Parakeet TDT model hits a comparable 6.05% WER with a much smaller footprint, making it more efficient.
Here are a few other foundational projects worth knowing:
Each of these tools represents a different philosophy for tackling the incredibly complex challenge of machine listening. Your job is to figure out which philosophy best aligns with your project's needs for accuracy, speed, language support, and customizability.
Choosing an open source speech to text model is a lot like deciding to build a custom race car instead of buying one off the lot. Sure, you can tune it perfectly to your exact specifications, but it demands a completely different set of skills, tools, and resources.
This path gives you incredible power, but it also comes with its own set of very real challenges. You have to be ready for them. For some projects, the upside is a total game-changer. For others, the hurdles are just too high. Let's dig into the practical trade-offs to help you figure out what makes sense for your team, budget, and goals.
The single biggest reason developers jump into open source is the total control it gives them. When you self-host a model, you're not just a customer renting a service—you own the entire process, from the hardware it runs on to the data it's trained with. This unlocks some serious advantages.
First up is data privacy. In a world where keeping data secure is non-negotiable, sending sensitive audio to a third-party API is a no-go for anyone in healthcare, finance, or the legal sector. With an open source model running on your own servers, your data never has to leave your control.
Another massive win is cost, especially at scale. Commercial APIs bill you for every minute or hour of audio you process. Open source models are free to use. Yes, you have to pay for the servers, but for high-volume work, you can save a fortune over time. It's the difference between a never-ending operational expense and a predictable, one-time infrastructure investment.
And then there's the customization. The potential here is off the charts. You can fine-tune a model on your own unique data to get incredible accuracy for specialized tasks.
For projects with unique requirements or strict privacy constraints, open source isn't just an option; it's often the only viable path. The ability to mold the technology to fit your precise needs is its greatest strength.
While the benefits are huge, the "do-it-yourself" approach of open source STT comes with some real-world headaches. If you don't plan for them, you're setting yourself up for delays and surprise costs.
The first hurdle you'll hit is the need for powerful hardware. State-of-the-art models are hungry for computational power, especially GPUs. That means a serious upfront investment in either physical servers or a beefy cloud setup. This can be a hefty initial expense.
Next, you can't just download a model and flip a switch. Deploying and maintaining these systems requires a team with specific technical expertise. You need engineers who know their way around machine learning frameworks, server management, and model optimization. When something breaks or needs an update, it's all on you.
Finally, it’s important to have realistic expectations for out-of-the-box accuracy. A model like Whisper is fantastic, but it might not immediately perform as flawlessly as a top-tier commercial API that's been tweaked and polished for years. Hitting that same level of quality often means you'll need to do your own fine-tuning and data collection.
This trade-off between control and convenience is at the heart of the entire voice technology market. In fact, the speech and voice recognition market is projected to skyrocket to USD 23.11 billion by 2030, a massive jump from USD 9.66 billion in 2025. This explosive growth is fueled by both the demand for easy plug-and-play solutions and the need for deeply customizable open source tools. You can dive into more data in the full market analysis from MarketsandMarkets. The right path for you really depends on whether your organization is better equipped to invest time and expertise or a recurring budget.
Sooner or later, every project needing transcription hits a fork in the road: do you go with an open source speech-to-text model or pay for a commercial API? This isn't just a technical detail; it's a strategic choice that ripples through your budget, timeline, and how much control you have in the long run.
One path gives you complete freedom and the ability to tinker with every nut and bolt. The other offers speed, convenience, and a team of experts on standby. It really boils down to a classic build versus buy dilemma. Do you have the resources to build your own transcription engine, or does it make more sense to plug into a polished, ready-to-go service? There's no single right answer, but by looking at what matters most, you can find the perfect fit for your goals.
The first thing everyone notices is the price tag. Open source models are free to download, which is incredibly appealing. But don't let that initial "free" fool you. You have to think about the Total Cost of Ownership (TCO), which includes all the hidden—and often substantial—expenses.
When you decide to run your own open source model, you're signing up for:
Commercial APIs, on the other hand, wrap all of these headaches into a simple, predictable price. Services like Lemonfox.ai typically charge by the hour of audio you process, making it incredibly easy to budget.
Here’s a snapshot of what that looks like in practice—a clear, pay-as-you-go model.
This approach completely eliminates surprise server bills and the need to hire a dedicated machine learning team. For most businesses, this makes the total cost far more manageable and predictable.
This is where commercial APIs really shine. An API is specifically designed to be a plug-and-play solution. A developer can get a high-quality transcription service up and running inside their application within hours, sometimes even minutes, just by making a few simple API calls.
Commercial APIs are built for speed and simplicity. They abstract away the immense complexity of machine learning, allowing developers to focus on building their product, not managing AI infrastructure.
In stark contrast, setting up an open source model is a project in itself. You're looking at days or even weeks of work configuring servers, wrestling with software dependencies, managing massive model files, and then building all the code to handle the audio processing. If you're a startup trying to get a product out the door, that kind of delay can be a killer.
To help you see the trade-offs more clearly, let’s put the two approaches side-by-side. This table compares the key factors you'll need to weigh when deciding between a self-hosted open source model and a commercial API.
| Feature | Open Source Models | Commercial APIs (e.g., Lemonfox.ai) |
|---|---|---|
| Initial Cost | Free (software only) | Pay-as-you-go (often with a generous free tier to start) |
| Total Cost | High (hardware, engineering, maintenance) | Predictable (based on usage, no infrastructure overhead) |
| Implementation Speed | Slow (requires setup, configuration, and expertise) | Fast (integrate in hours with simple API calls) |
| Accuracy | High (can be fine-tuned for specific domains) | Very High (models are continuously improved by experts) |
| Customization | Maximum (full control to modify and train) | Limited (some APIs offer custom vocabularies, but not full training) |
| Data Privacy | Complete (data never leaves your servers) | High (reputable providers delete data post-processing) |
| Ongoing Support | Community-driven (forums, GitHub issues) | Dedicated (professional support teams and documentation) |
| Scalability | Challenging (requires manual infrastructure scaling) | Effortless (built to handle massive, fluctuating workloads) |
Ultimately, the best choice hinges on what your organization values most. If you're a research group with an in-house AI team and ironclad data privacy requirements, an open source model is probably your best bet. But if you’re a fast-moving startup that needs to launch quickly and efficiently, the speed, reliability, and simplicity of a commercial API are almost always the winning combination.
Choosing the right voice technology isn't about finding a single "best" tool. It’s about finding the smartest fit for what you're trying to build, given the resources you actually have. We’ve looked at the world of open source speech to text and commercial APIs, and now it’s time to land the plane.
Making this choice is less about the tech and more about your strategy. It’s a decision that directly impacts your budget, your launch timeline, and your product's future. Let's walk through the key questions that will lead you to a clear, confident decision.
Before you commit to a path, get your team in a room and have an honest conversation about your capabilities and priorities. The right answer for you will become obvious once you lay everything out on the table.
Here are the essential questions to kickstart that discussion:
What's our real budget?
Don't just think about software licenses. You have to factor in the cost of beefy GPUs, the ongoing headache of server maintenance, and the salaries of the specialized engineers needed to babysit an open source model. Compare that total cost against the simple, predictable pricing of a commercial API.
How big of a deal is data privacy?
If your app handles sensitive information—think medical records, financial data, or private conversations—then keeping that data on your own servers might be a deal-breaker. A self-hosted open source model gives you complete control, which can be a huge win here.
Does our team have the right skills?
Be honest. Do you have engineers who are genuinely experienced with machine learning, deploying models, and tweaking them for performance? If not, the steep learning curve of an open source setup can cause major delays and a lot of frustrating, unexpected problems.
How quickly do we need to get this live?
Commercial APIs like Lemonfox.ai are built to get you up and running fast—often in a matter of hours. An open source solution, on the other hand, is a project in itself. It can easily take weeks of setup and fine-tuning before it's ready for real users.
Once you weigh your answers, you can confidently decide whether a self-hosted model, a commercial API, or even a hybrid approach makes the most sense. This clarity is what lets you build your next voice feature on a foundation that’s right for your business.
When you start digging into open source speech-to-text, a lot of practical questions pop up. Let's tackle some of the most common ones we hear from developers and teams trying to figure out if it's the right path for them.
This is the million-dollar question, and the answer is always changing. While OpenAI's Whisper gets a lot of attention for its all-around solid performance, competitors are constantly pushing the envelope. On certain benchmarks, models like Nvidia’s Canary Qwen and IBM’s Granite Speech have shown slightly lower Word Error Rates (WER) in perfect conditions.
But here's the catch: benchmark performance isn't real-world performance. The "most accurate" model is the one that works best on your audio. A model that perfectly transcribes a formal speech might fall apart when faced with noisy call center recordings or thick regional accents. True accuracy comes from testing models with your own data.
The software might be free, but running an open source speech to text model is anything but. You're trading a subscription fee for infrastructure and operational costs, and the biggest one is the hardware. These models need serious GPU power to run efficiently.
Here's a quick look at where the money goes:
For any application with serious volume, these costs can quickly add up to thousands of dollars every month.
Absolutely. In fact, this is where open source really shines. Modern models like Whisper were trained on a massive, messy collection of audio from all over the internet, which gave them incredible out-of-the-box support for dozens of languages and accents. Its ability to handle 99 languages really set a new bar.
The real power of open source emerges when you're dealing with unique dialects or low-resource languages. You have the freedom to take a pre-trained model and fine-tune it with your own audio data. This lets you build a highly specialized system for a community that commercial APIs might overlook. For global companies, that level of customization is a game-changer.
Ready for a simpler, more affordable solution? Lemonfox.ai provides a powerful Speech-to-Text API with top-tier accuracy and support for over 100 languages, all without the hardware and maintenance headaches. Get started with 30 free hours and see how easy high-quality transcription can be.