First month for free!
Get started
Published 11/9/2025
Finding a high-quality, flexible, and affordable text-to-speech solution can be a significant challenge for developers and businesses. Commercial APIs offer convenience but often come with restrictive licenses, high costs, and a lack of customizability. This is where the power of open source text to speech engines comes into play, providing unparalleled control over voice generation, from cloning unique voices to running entirely offline for enhanced privacy and performance. These tools solve the critical problem of converting text into natural-sounding audio without being locked into a specific vendor's ecosystem.
This guide dives deep into the best open source TTS options available today. We move beyond simple descriptions to provide a practical, developer-focused resource. For each tool, you will find a detailed analysis covering core features, installation guidance, honest pros and cons based on real-world usage, and specific integration tips. We will explore everything from lightweight, fast engines suitable for embedded devices to powerful, deep learning-based frameworks capable of producing incredibly realistic and expressive speech. Our goal is to help you select the right framework for your specific project needs, whether you're building a voice assistant, creating accessible applications, or generating dynamic audio content. Each entry includes direct links to get you started immediately.
Coqui TTS stands out as a powerful and flexible deep-learning toolkit for high-quality, open source text to speech synthesis. Descended from the original Mozilla TTS, it has become a go-to for developers needing advanced control over voice generation, including multilingual support and sophisticated voice cloning capabilities. It’s a comprehensive ecosystem rather than just a simple library.
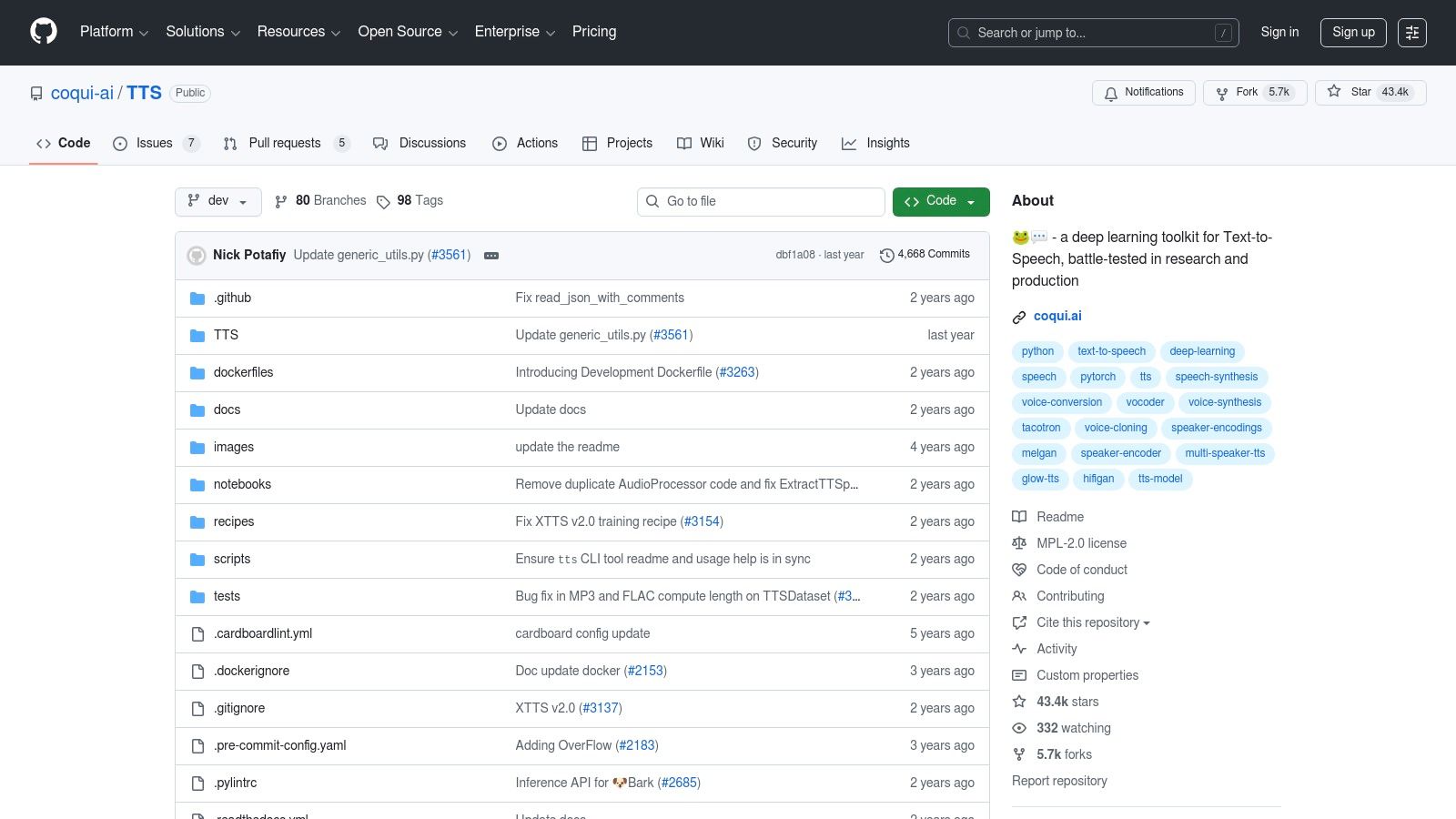
The platform is completely free and open-source under the Mozilla Public License 2.0. Its main strength lies in its extensive collection of pre-trained models, which allows for immediate implementation of natural-sounding speech across numerous languages. Developers can leverage the Python API for seamless integration or deploy a local TTS server quickly using the provided CLI and Docker images.
What truly makes Coqui TTS unique is its focus on customization. It provides detailed recipes and scripts for training new models or fine-tuning existing ones on your own data. This is particularly valuable for creating unique brand voices or applications requiring specific vocal characteristics.
| Feature Highlights | Implementation |
|---|---|
| Pre-trained Models | Multi-speaker & multilingual voices available |
| Voice Cloning | Support for XTTS-style few-shot cloning |
| Deployment | Python API, CLI, and Docker server |
| Customization | Training & fine-tuning recipes included |
Website: https://github.com/coqui-ai/TTS
Piper is a fast, lightweight, and entirely offline neural text to speech engine designed for high performance on edge devices like the Raspberry Pi. As a core component of the Rhasspy voice assistant ecosystem and the Open Home Foundation, its primary focus is on delivering responsive, private voice interactions for smart home and embedded applications. It leverages the ONNX runtime for efficient CPU-based inference.
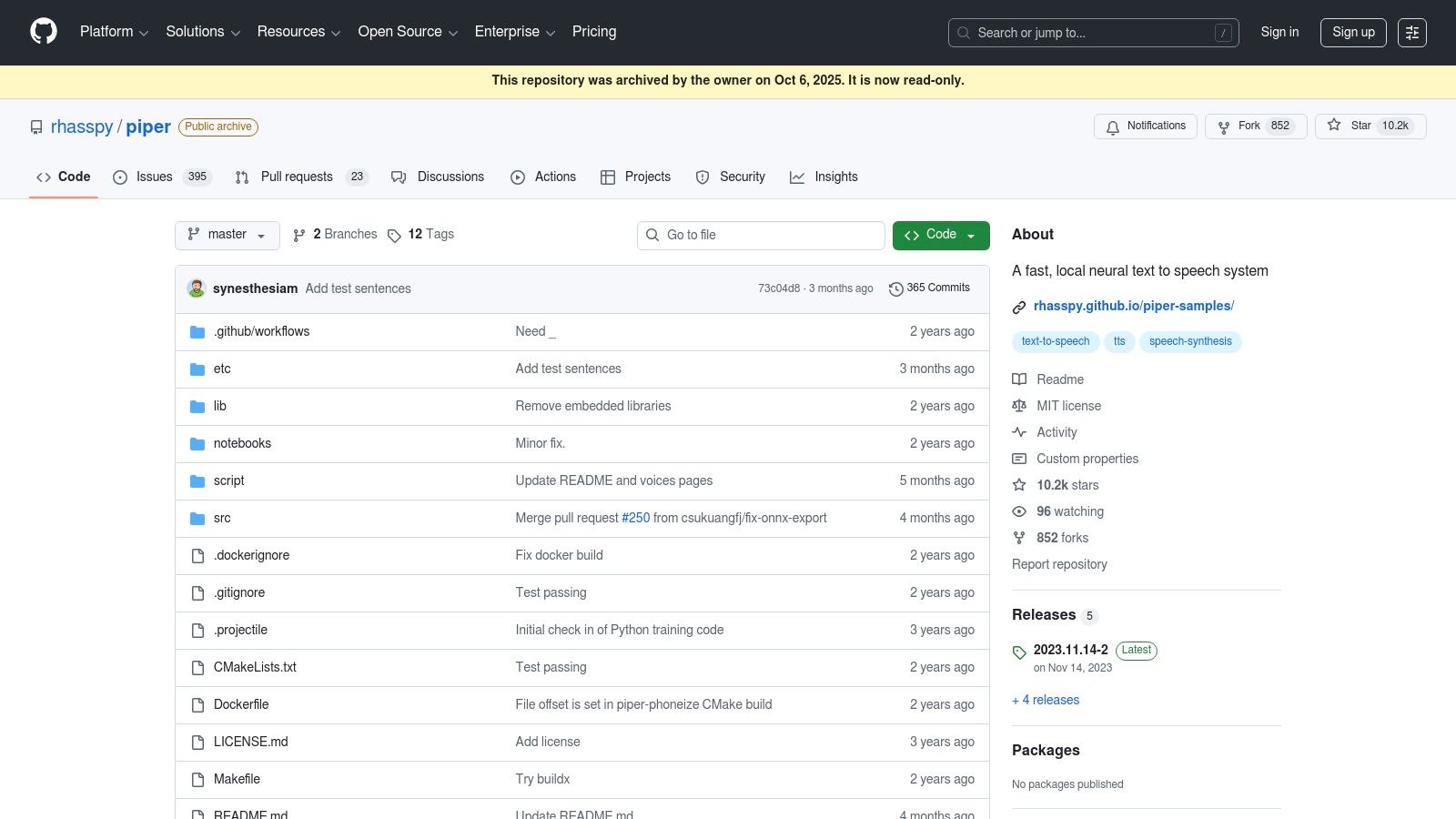
The system is completely free and open source, operating under a permissive MIT license. Its main draw is its speed and simplicity, making it an excellent open source text to speech choice for local projects where cloud latency is unacceptable. It offers a vast library of community-trained voices available for download in various languages and quality tiers, often hosted on Hugging Face.
What makes Piper unique is its optimization for resource-constrained environments. It achieves near-instantaneous speech synthesis on low-power hardware without needing a dedicated GPU. Integration is straightforward via its simple command-line interface, which supports streaming and JSON input, making it easy to incorporate into scripts and local applications.
| Feature Highlights | Implementation |
|---|---|
| Optimized for Edge | Fast, resource-efficient inference on CPU |
| Voice Library | Dozens of community voices in ONNX format |
| Deployment | Simple CLI with streaming and JSON input support |
| Offline Operation | Works entirely locally with no internet required |
Website: https://github.com/rhasspy/piper
Hugging Face has become the definitive hub for the machine learning community, and its text-to-speech section is no exception. Rather than being a single tool, it’s a vast, searchable catalog of thousands of open source text to speech models like VITS, Bark, and SpeechT5. It acts as a central repository where developers can discover, compare, and download a massive variety of voices and architectures.
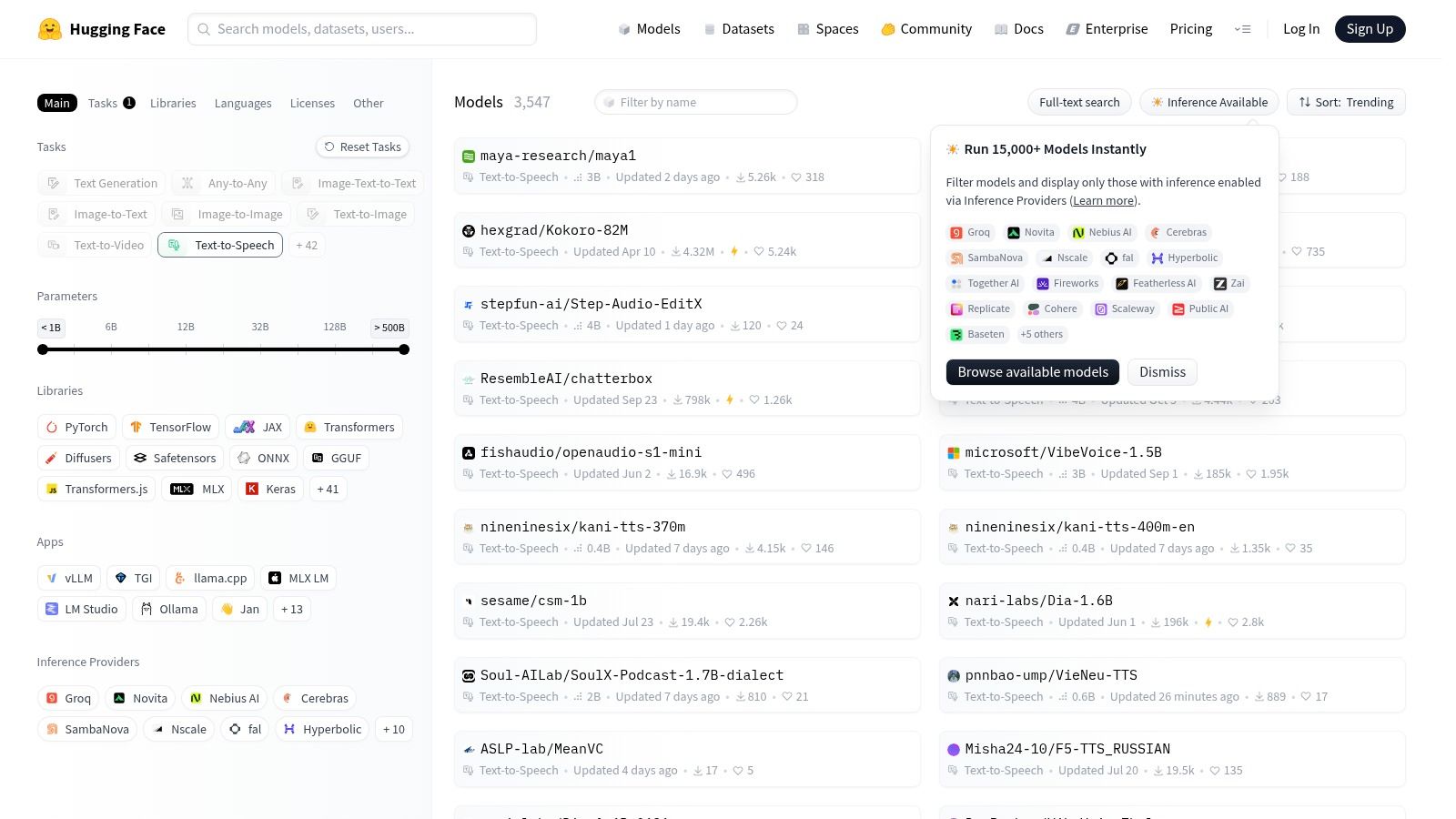
The platform is free for accessing and downloading models, with optional paid Inference Endpoints for hosting. Its strength is its accessibility; each model comes with a "model card" detailing its license, intended use, and code snippets for easy implementation using their transformers library. Many models also feature interactive demos called Spaces, allowing you to test a voice directly in your browser before committing to it.
This centralized approach simplifies the discovery process immensely. You can filter models by license, language, or underlying framework, making it easy to find a suitable option for your project. Hugging Face bridges the gap between complex research and practical application, providing the tools needed to quickly integrate a model.
| Feature Highlights | Implementation |
|---|---|
| Vast Model Hub | Thousands of models with powerful search filters |
| Model Cards | Detailed usage info, licensing, and code snippets |
| Interactive Demos | "Spaces" allow for in-browser model testing |
| Easy Integration | Standardized transformers pipeline for inference |
Website: https://huggingface.co/models?filter=text-to-speech
MaryTTS is a mature, open-source multilingual text to speech synthesis platform written entirely in Java. Developed by the German Research Center for Artificial Intelligence (DFKI), it serves as a robust client-server system that can be run locally on modest hardware. Its longevity and stability have made it a reliable choice for developers needing a self-hosted TTS solution with a straightforward setup process.
The platform is completely free and licensed under the LGPL. Its standout feature is the user-friendly installer, which includes a GUI for easily downloading and managing different voice packages in various languages. MaryTTS utilizes a combination of unit selection and Hidden Semi-Markov Model (HSMM) based synthesis techniques. While not as fluid as modern neural networks, these methods are less computationally demanding.
What makes MaryTTS particularly useful is its HTTP API, which provides a simple and standardized way to integrate speech synthesis into a wide array of applications and services. This makes it a popular backend for many downstream tools that require a dependable open source text to speech engine.
| Feature Highlights | Implementation |
|---|---|
| Synthesis Method | HSMM & unit-selection voices |
| Deployment | Cross-platform Java server |
| API | Standardized HTTP endpoints |
| Voice Management | GUI-based installer for voice packages |
Website: https://marytts.github.io/
Festival is one of the original pioneers in the open source text to speech landscape, developed by the University of Edinburgh. It provides a complete, multi-lingual TTS system with a strong emphasis on research and extensibility. Rather than focusing on modern deep learning, Festival offers a classic, full-stack architecture that gives developers granular control over the entire synthesis pipeline.

The system is completely free and distributed under a permissive, non-restrictive license. Its primary strength lies in its robust architecture and powerful scripting capabilities using a Scheme-based command interpreter. This allows for deep customization of everything from text processing and phoneme conversion to intonation. When paired with its companion toolkit, FestVox, users can build entirely new voices from scratch.
What makes Festival unique is its academic foundation and time-tested reliability. While its default voices may not match the naturalness of modern neural networks, its architecture is invaluable for research, linguistics, and applications where rule-based control and predictability are more important than human-like prosody.
| Feature Highlights | Implementation |
|---|---|
| Full TTS Pipeline | Complete system with scripting via Scheme |
| Language Support | Extensible support for multiple languages |
| Voice Building | Deep integration with FestVox for creating new voices |
| APIs | C++ libraries, Scheme interpreter, and command-line access |
Website: http://festvox.org/festival/
Flite, short for festival-lite, is a small, fast, and portable open source text to speech engine developed in C. It was derived from the larger Festival Speech Synthesis System and designed specifically for resource-constrained environments like embedded systems or mobile devices. Its primary strengths are its minimal footprint and rapid execution speed, making it a go-to choice for applications where performance and efficiency are more critical than voice naturalness.
This completely free engine is licensed permissively, allowing broad use in various projects. Flite is incredibly simple to deploy, with command-line tools for quick synthesis and straightforward integration into C programs. Its portability is a key feature, and it is widely packaged in major Linux distributions, ensuring easy installation for developers working in that ecosystem. It’s an ideal solution for adding basic voice feedback to hardware projects or lightweight applications.
What sets Flite apart is its unapologetic focus on efficiency over quality. While it lacks the human-like intonation of modern neural TTS systems, its classic concatenative synthesis provides clear and intelligible speech with minimal processing overhead. This makes it a reliable workhorse for functional audio output where system resources are precious.
| Feature Highlights | Implementation |
|---|---|
| Lightweight Engine | Minimal footprint and fast runtime |
| Portability | Written in C, easily compiled on many platforms |
| Deployment | Command-line tools and C library |
| Voice Options | Built-in and loadable voices available |
Website: http://cmuflite.org/
eSpeak NG is a compact, cross-platform software speech synthesizer that uses formant synthesis, allowing it to support a massive number of languages and accents with a very small footprint. This classic open source text to speech engine is highly valued in accessibility tools, like screen readers, and embedded systems where resource usage is a primary concern. Its focus is on clarity and responsiveness over sounding human.
This synthesizer is completely free and licensed under the GPLv3. Its main strength is its efficiency and unparalleled language support, covering over 100 languages and accents out of the box. Unlike modern neural TTS engines that require significant processing power, eSpeak NG can run on virtually any device, from a Raspberry Pi to a high-end server, making it perfect for automation scripts and low-resource environments.
What makes eSpeak NG unique is its algorithmic approach. Instead of using large voice models, it generates sound based on linguistic rules. While this results in a more robotic voice, it offers developers fine-grained control over pronunciation, pitch, and speed through its command-line interface and library bindings for languages like Python.
| Feature Highlights | Implementation |
|---|---|
| Synthesis Method | Formant-based for efficiency and small size |
| Language Support | 100+ languages and accents included |
| Platform Compatibility | Runs on Linux, Windows, macOS, and more |
| Integration | Command-line tool, C library, and language bindings |
Website: https://github.com/espeak-ng/espeak-ng
RHVoice is an open-source multilingual synthesizer designed with a sharp focus on accessibility. Its primary mission is to provide high-quality, free voices for languages often underserved by commercial TTS engines, making it a critical tool for blind and low-vision users worldwide. Rather than competing on hyper-realistic English voices, it excels at providing practical, reliable speech for a diverse linguistic landscape.

The synthesizer is completely free and developed by a dedicated community. Its key strength is its tight integration with major accessibility tools and operating systems. RHVoice offers dedicated installers and add-ons for screen readers like NVDA on Windows, system-level integration on Android via TalkBack, and broad support on Linux. This makes it a plug-and-play solution for users who need a dependable open source text to speech engine for daily use.
What makes RHVoice unique is its commitment to linguistic diversity and its user-centric development. While some voices may sound more robotic than premium alternatives, the emphasis is on clarity, responsiveness, and support for languages that might otherwise have no viable TTS options available.
| Feature Highlights | Implementation |
|---|---|
| Accessibility Focus | Direct integrations for NVDA, TalkBack, and more |
| Multilingual Support | Strong coverage for Eastern European and other languages |
| Platform Integration | Windows (SAPI), Linux (Speech Dispatcher), Android |
| Community Driven | Voices and improvements contributed by volunteers |
Website: https://rhvoice.org/
NVIDIA NeMo is an open-source conversational AI toolkit built for researchers and developers working on high-performance applications. Its text to speech collection offers state-of-the-art neural pipelines, such as FastPitch combined with HiFi-GAN, designed for GPU acceleration. This makes it an ideal choice for enterprise-grade systems where quality, speed, and reliability are paramount.
The framework is built on PyTorch and is completely free and open-source under the Apache 2.0 license. NeMo's key strength is its modularity, allowing developers to mix and match components like text-to-mel generators and vocoders. It provides a rich set of pre-trained models and clear recipes for training or fine-tuning, with a strong focus on optimized deployment paths using tools like NVIDIA Riva for scalable inference.
What sets NeMo apart is its deep integration with the NVIDIA hardware ecosystem. It’s engineered from the ground up to leverage GPU capabilities, making it one of the best open source text to speech options for production environments that demand high throughput and low latency.
| Feature Highlights | Implementation |
|---|---|
| Neural Pipelines | FastPitch+HiFi-GAN & Tacotron2+WaveGlow models |
| Modularity | Separate text-to-mel and vocoder components |
| Deployment | Optimized for GPU inference via NVIDIA Riva |
| Customization | Training & fine-tuning scripts for custom voices |
Website: https://docs.nvidia.com/nemo-framework/user-guide/latest/nemotoolkit/tts/intro.html
TensorFlowTTS provides a robust, real-time open source text to speech synthesis framework built entirely on TensorFlow 2. Developed by the TensorSpeech community, it offers clean and powerful implementations of popular TTS architectures like Tacotron 2 and FastSpeech 2, paired with high-fidelity neural vocoders such as MelGAN and HiFi-GAN. It is an ideal choice for developers already working within the TensorFlow ecosystem.
This free, open-source library (Apache 2.0 License) is designed for both research and production. It provides comprehensive examples, pre-trained models for various languages, and detailed training recipes. This makes it accessible for those looking to replicate state-of-the-art results or train custom voices from scratch.
A key differentiator for TensorFlowTTS is its strong focus on deployment, particularly for mobile and edge devices. The repository includes clear guides and scripts for converting trained models to the TFLite format. This allows for efficient on-device inference on platforms like Android, making it a powerful tool for building applications that require offline TTS capabilities.
| Feature Highlights | Implementation |
|---|---|
| TTS Architectures | Tacotron 2, FastSpeech 2, and others |
| Neural Vocoders | MelGAN, HiFi-GAN for high-quality audio |
| Deployment Focus | TFLite conversion guides for mobile (Android) |
| Customization | End-to-end training recipes and pre-trained models |
Website: https://github.com/TensorSpeech/TensorFlowTTS
Silero Models provide a collection of pre-trained, high-quality open source text to speech models that prioritize simplicity and efficiency. Distributed via PyTorch Hub and pip, Silero’s main draw is its one-line implementation, allowing developers to get a functional TTS engine running with minimal setup. It's particularly noted for its strong support for languages often underserved by other platforms, including Russian, Ukrainian, and various Indic languages.
The models are completely free, released under a permissive license, and are designed for high-performance inference on commodity hardware, running efficiently on both CPU and GPU. Developers can quickly integrate TTS capabilities into their Python applications with just a few lines of code, making it an excellent choice for rapid prototyping or projects where complex model training is unnecessary. Example Google Colab notebooks are provided to demonstrate usage instantly.
Silero stands out for its straightforward, no-fuss approach. While it may not have the extensive customization frameworks of larger toolkits, it excels at providing reliable, ready-to-use voices with excellent quality, especially for its core supported languages.
| Feature Highlights | Implementation |
|---|---|
| Ease of Use | One-line setup via PyTorch Hub or pip |
| Performance | Optimized for fast inference on CPU/GPU |
| Language Support | Strong focus on non-English languages |
| Deployment | Simple Python API with multi-speaker options |
Website: https://github.com/snakers4/silero-models
OpenTTS is a Dockerized HTTP server designed to unify access to multiple open-source text to speech engines. Instead of being a single TTS model, it acts as a convenient wrapper, providing a single, consistent API for interacting with popular engines like Piper, Coqui-TTS, MaryTTS, and more. This makes it an excellent tool for developers who want to quickly evaluate and compare different voices and technologies without complex setup for each one.
The platform is entirely free and open-source, simplifying deployment through pre-built Docker images. Its core strength is abstraction; developers can switch between different backend TTS systems just by changing a parameter in an API call. This is ideal for prototyping or building applications where voice flexibility is a key requirement. It also offers a MaryTTS-compatible endpoint, making it a drop-in replacement for systems already built on that standard.
What makes OpenTTS unique is its "meta-engine" approach. By bundling various technologies, it provides a voice browser and sample pages that allow for immediate side-by-side auditory comparison. This practical feature saves significant development time during the initial research and selection phase of a project.
| Feature Highlights | Implementation |
|---|---|
| Unified API | Single HTTP endpoint for multiple engines |
| Engine Support | Wraps Piper, Coqui-TTS, MaryTTS, Festival, etc. |
| Deployment | Pre-configured Docker images |
| Compatibility | MaryTTS-compatible endpoint for easy integration |
Website: https://github.com/synesthesiam/opentts
| Engine / Toolkit | Core Features | Quality & Perf | Unique / USP | Target Audience |
|---|---|---|---|---|
| Coqui TTS | ✨ Python API, pretrained multi‑speaker models, Docker, fine‑tuning | ★★★★☆ — high neural quality, GPU accel 🏆 | ✨ Voice cloning, active community 🏆 | 👥 Developers, ML teams, researchers 💰Free (self‑host, GPU recommended) |
| Piper (Rhasspy) | ✨ ONNX voices, CLI, CPU‑optimized runtime for edge | ★★★☆ — very fast, CPU‑efficient | ✨ Edge/embedded optimized, many community voices 🏆 | 👥 Home Assistant, Raspberry Pi, embedded 💰Free (local) |
| Hugging Face – TTS Catalog | ✨ Hub of thousands of models, model cards, Spaces demos | ★★★☆ — quality varies by model | 🏆 Central discovery + hosted demos, licensing info ✨ | 👥 Researchers, devs exploring models 💰Free catalog / paid hosted inference |
| MaryTTS (DFKI) | Java server, GUI installer, HSMM/unit selection voices | ★★☆☆☆ — functional, less natural | ✨ Stable, easy self‑host, installer for voices | 👥 Integrators, Java shops, on‑prem deployments 💰Free (self‑host) |
| Festival | C/C++ API, full TTS pipeline, scripting, FestVox support | ★★☆☆☆ — dated naturalness, robust | ✨ Time‑tested for research and customization | 👥 Researchers, legacy systems, academia 💰Free (self‑host) |
| Flite (festival‑lite) | Small C engine, minimal footprint, CLI voices | ★★☆☆☆ — robotic but very fast | ✨ Ultra‑light for constrained devices 🏆 | 👥 Embedded, low‑power devices, IoT 💰Free (self‑host) |
| eSpeak NG | Formant TTS, 100+ languages, tiny footprint | ★★☆☆☆ — robotic, broad language support | ✨ Excellent accessibility & language coverage | 👥 Accessibility tools, automation 💰Free (self‑host) |
| RHVoice | Multilingual voices, screen‑reader integrations | ★★☆–★★★ — varies by language | ✨ Accessibility focus, OS integrations 🏆 | 👥 Blind/low‑vision users, accessibility devs 💰Free (self‑host) |
| NVIDIA NeMo (TTS) | Modular neural pipelines, pretrained checkpoints, export | ★★★★★ (on NVIDIA GPUs) — SOTA voices | 🏆 Enterprise SOTA; GPU‑optimized training/inference ✨ | 👥 Enterprise, research teams with GPUs 💰Free code / infra cost |
| TensorFlowTTS | TF2 implementations (Tacotron2, FastSpeech2), TFLite paths | ★★★★☆ — strong neural quality, mobile support | ✨ End‑to‑end TF2 recipes, TFLite conversion | 👥 TensorFlow devs, mobile engineers 💰Free (self‑host) |
| Silero Models (TTS) | pip / Torch Hub, simple API, efficient inference | ★★★★☆ — good baseline quality (selected langs) | ✨ One‑line usage, CPU‑friendly inference | 👥 Devs needing quick CPU TTS, fast prototyping 💰Free (self‑host) |
| OpenTTS | Dockerized server unifying many engines, Mary‑compatible API | ★★★☆ — depends on bundled engine | ✨ Unified API to compare engines quickly 🏆 | 👥 Evaluators, self‑hosted labs, devs 💰Free (self‑host; archived repo — limited updates) |
Navigating the vibrant landscape of open source text to speech technology reveals a powerful truth: high-quality, customizable voice synthesis is more accessible than ever. Throughout this guide, we've explored a diverse array of tools, from the production-ready Coqui TTS and the efficient, offline-first Piper to the vast model repository of Hugging Face. Each solution presents a unique combination of features, performance characteristics, and community support, catering to different project requirements and developer skill levels.
The key takeaway is that the "best" open source TTS engine is not a one-size-fits-all answer. Your ideal choice depends entirely on the specific context of your application. The journey from text to lifelike audio is no longer the exclusive domain of large tech corporations. It's a field rich with community-driven innovation, offering developers unprecedented control over the final vocal output.
Making an informed decision requires a clear understanding of your project's constraints and goals. Before committing to a library, carefully evaluate your needs against these critical factors:
The world of open source text to speech is dynamic and constantly evolving. The tools we've discussed empower you to build everything from accessible applications for the visually impaired to immersive gaming experiences and innovative voice-first products. The power to give your project a voice is in your hands, backed by a global community of developers pushing the boundaries of what's possible.
Start by experimenting with a few top contenders that align with your primary use case. Set up a simple proof-of-concept, test the voice quality, measure the performance, and engage with the community. By taking this hands-on approach, you will not only find the right tool but also gain a deeper appreciation for the incredible technology that turns silent text into compelling, expressive speech.
If your project requires enterprise-grade performance, reliability, and an even simpler integration path, consider exploring a managed solution. Lemonfox.ai leverages cutting-edge AI to provide a powerful, high-quality, and affordable Speech-to-Text API, helping you build sophisticated voice applications without the overhead of managing infrastructure. Check out our platform at Lemonfox.ai to see how we can accelerate your development.