First month for free!
Get started
Published 11/20/2025
Finding the right open source text to voice engine can feel overwhelming. While commercial APIs from Google, Amazon, and Microsoft offer polished, easy-to-use services, they come with ongoing costs, privacy concerns, and a lack of customizability. For developers and businesses seeking greater control, data sovereignty, and cost-effective solutions, the open-source landscape provides powerful alternatives. This guide is designed to navigate that landscape, helping you select the best TTS tool for your specific project.
This comprehensive listicle dives deep into the most capable and actively maintained open source text-to-speech projects available today. We move beyond simple descriptions to provide practical, actionable insights. For each tool, you will find a concise overview, key features, and direct links to its repository and documentation. We also offer an honest assessment of its strengths and weaknesses, ideal use cases, and essential implementation notes to get you started.
Whether you are building a voice assistant for a local device, creating audio versions of articles, developing accessibility tools, or integrating voice feedback into an application, this resource will help you make an informed decision. We will explore everything from lightweight, fast engines like Piper to comprehensive research toolkits like ESPnet and NVIDIA NeMo. By the end, you'll have a clear understanding of which open source text to voice solution best aligns with your technical requirements, performance needs, and development resources.
Hugging Face has become the definitive central repository for the machine learning community, and its Text-to-Speech section is an indispensable starting point for anyone exploring open source text to voice solutions. Rather than being a single model, it’s a vast, searchable hub where researchers and developers share thousands of pre-trained TTS models, datasets, and interactive browser-based demos called "Spaces." This makes it an unparalleled resource for discovery and evaluation.
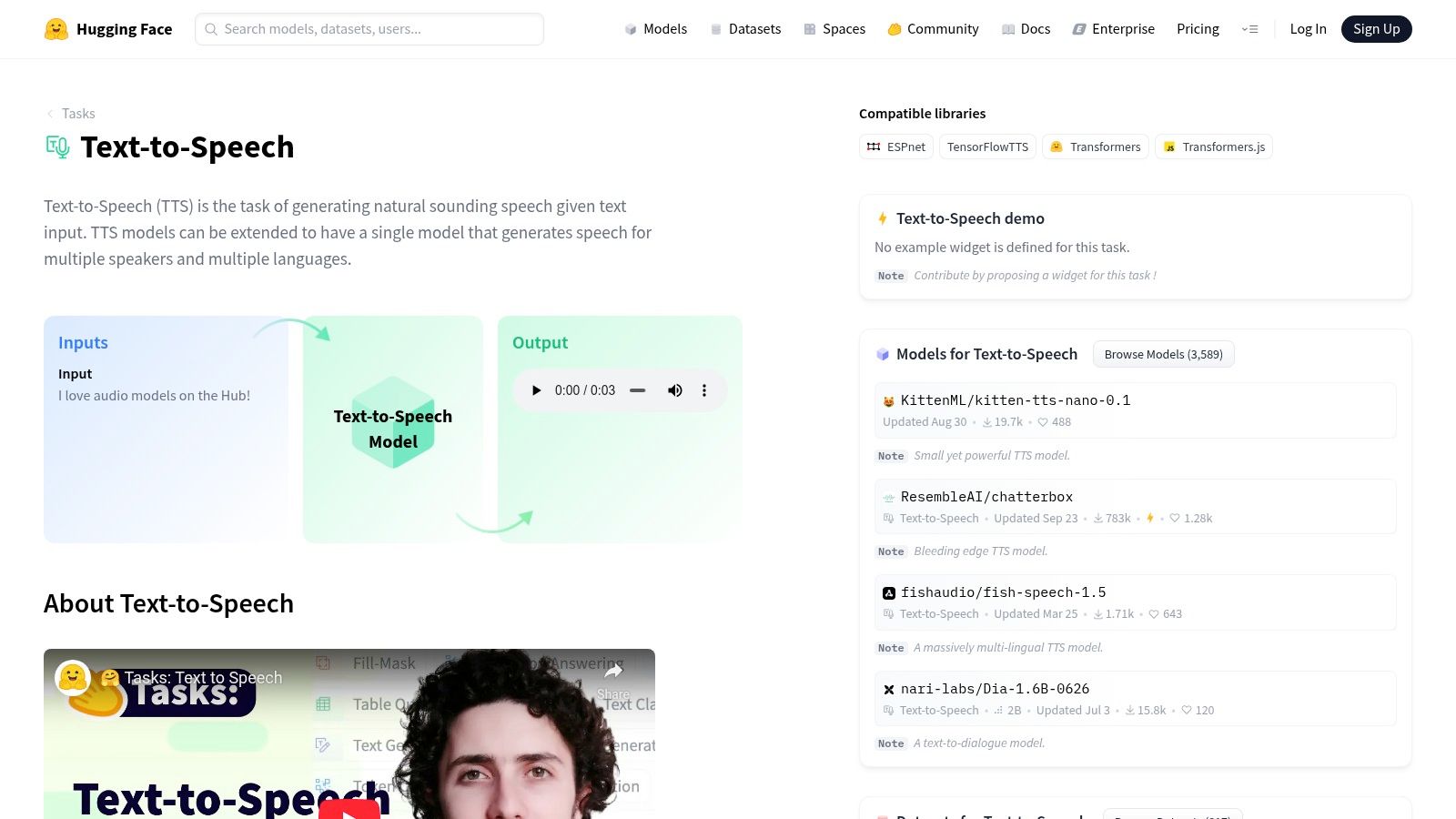
You can instantly test popular models like Bark, VITS, and SpeechT5 directly in your browser without any setup. Each model has a "model card" detailing its architecture, intended use, limitations, and, most importantly, its open-source license. This transparency is crucial for determining if a model is suitable for commercial use. For developers, the transformers library offers a standardized Python pipeline to download and integrate these models with just a few lines of code.
Hugging Face is the best place to begin your search, allowing you to quickly survey the landscape of available open source TTS technology before committing to a specific model or framework.
Website: https://huggingface.co/tasks/text-to-speech
Piper is a lightweight and exceptionally fast neural text-to-speech engine optimized for local inference on CPUs and low-power devices like a Raspberry Pi. Maintained by the Open Home Foundation and known as the successor to Rhasspy, it has become a go-to solution for smart-home projects, particularly within the Home Assistant ecosystem. Its core strength lies in providing a high-performance open source text to voice system that can run entirely offline without requiring a dedicated GPU, making it perfect for privacy-focused and edge computing applications.
The project is designed for straightforward deployment. It offers a simple command-line interface, a Python API, and a web server, with pre-trained voice models distributed in the efficient ONNX format. This approach allows developers to get a high-quality TTS server running with minimal setup, often just a pip install or by using one of the provided Docker recipes. It supports a large library of voices across many languages and cleverly streams audio to minimize perceived latency, starting playback almost instantly.
Piper is the best choice when you need a responsive, private, and self-hosted TTS system that performs reliably without powerful or expensive hardware.
Website: https://github.com/OHF-Voice/piper1-gpl
For those embedded in the smart home ecosystem, the Home Assistant integration for Piper represents a practical and powerful application of open source text to voice technology. Rather than being a standalone development tool, this is a fully integrated solution designed to give your smart home a voice. It allows Home Assistant to use Piper, a fast and local neural TTS system, to generate spoken announcements, alerts, and responses for automations, routing them directly to smart speakers and displays throughout your home.
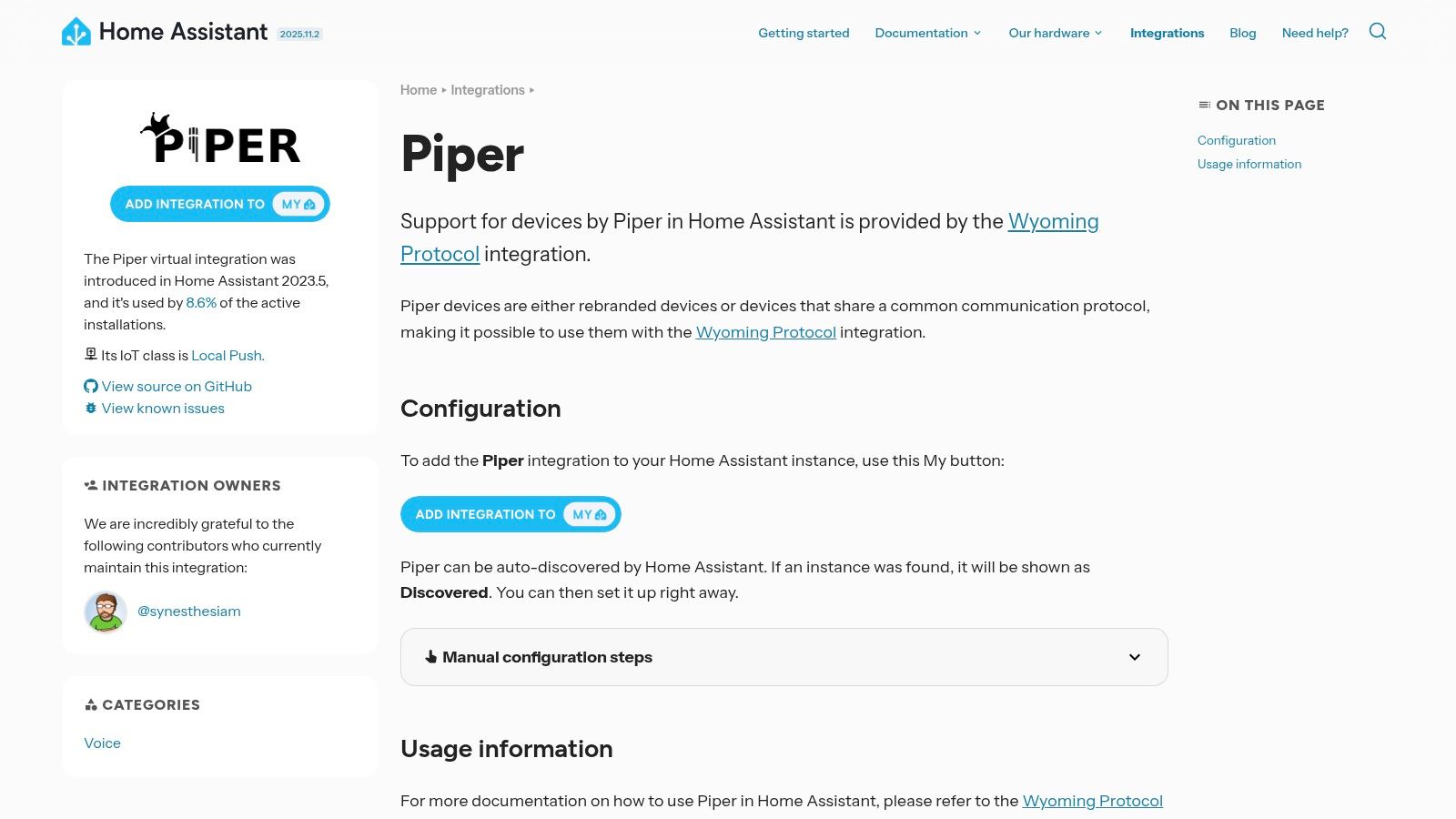
The integration is managed entirely through the Home Assistant user interface, making it exceptionally accessible to users who are not developers. Setup involves simply adding the Piper integration and downloading your preferred voices. Once configured, you can call the tts.speak service in your automations to make announcements like "The garage door has been left open" or provide real-time responses for custom voice assistants. This focus on practical, in-home application makes it a unique entry on this list.
Home Assistant's Piper integration is the ideal choice for smart home enthusiasts who want a private, local, and highly responsive text-to-voice engine to bring their automated home to life.
Website: https://www.home-assistant.io/integrations/piper/
eSpeak-NG (Next Generation) is a legendary, compact open-source speech synthesizer that prioritizes efficiency and broad language support over naturalness. Based on a formant synthesis method, it doesn't use large voice samples, allowing it to have an incredibly small memory footprint. This makes it a foundational piece of technology for accessibility tools like screen readers and a perfect choice for resource-constrained environments such as embedded systems or older hardware.
Unlike the neural network models that dominate modern TTS, eSpeak-NG generates speech algorithmically. While this results in a distinctly robotic and less human-like voice, it offers unparalleled speed and responsiveness. It can be used as a command-line tool, a shared library for integration into applications, and supports over 100 languages and accents. Its predictability and clarity at high speeds are highly valued in the accessibility community, making it a powerful open source text to voice tool where function triumphs over form.
eSpeak-NG is the go-to solution when performance, a small footprint, and wide language coverage are more critical than achieving a natural-sounding human voice.
Website: https://github.com/espeak-ng/espeak-ng
MaryTTS (Modular Architecture for Research in Synthesis) is a mature, Java-based open source text to voice synthesis platform developed by the German Research Center for Artificial Intelligence (DFKI). Its client-server architecture makes it exceptionally well-suited for creating a self-hosted TTS server that can be accessed by various applications within a network. This makes it a stable and reliable choice for projects rooted in the Java ecosystem or for those needing a centralized, cross-platform voice service.
The platform is designed for modularity, allowing users to install different languages and voices via a component installer. While its default voices rely on older, less natural-sounding technologies like HMM-based synthesis, it provides a robust foundation for developers who need full control over their TTS environment. Its longevity means it comes with extensive documentation, integration examples, and even tools for building Android ports, making it a powerful system for specialized applications.
MaryTTS is an excellent choice for developers needing a stable, self-hosted, and highly customizable TTS server, particularly within established Java-based infrastructure where cutting-edge voice naturalness is secondary to system control and stability.
Website: https://github.com/marytts/marytts
Festival is one of the original, foundational speech synthesis systems, originating from the University of Edinburgh's Centre for Speech Technology Research (CSTR). Rather than a modern, single-purpose library, it's a comprehensive, multi-lingual TTS framework designed for research and deep customization. Its architecture is highly extensible, allowing developers to experiment with various synthesis methods, from older unit selection (clunits) to more modern HMM-based synthesis (HTS), making it an excellent platform for understanding the mechanics of open source text to voice technology.
The system's power lies in its Scheme-based command interpreter, which provides granular control over every stage of the synthesis process, from text processing and tokenization to phoneme generation and waveform creation. While its default voices sound more robotic compared to today's neural models, Festival's true value is its "hackability." It serves as an incredible educational tool and a robust backend for specialized applications where predictability and control are more important than achieving the most natural-sounding human voice.
Festival is best suited for academic research, linguistic experimentation, or embedded systems where resource usage and complete control over the synthesis pipeline are critical priorities.
Website: https://github.com/festvox/festival
Following the shutdown of the original Coqui company, the community, led by the Idiap Research Institute, has maintained and continued this powerful open source text to voice library. Coqui‑TTS is a deep learning toolkit for text-to-speech that implements a wide variety of state-of-the-art models. It provides a comprehensive framework for both using pre-trained models and training new ones from scratch, making it a favorite among researchers and developers who need fine-grained control.
Distributed as a Python package, the library offers a straightforward command-line interface and a flexible Python API for generating speech. It comes with an extensive collection of pre-trained models covering various languages and voice styles, which can be easily downloaded and used. Its advanced capabilities, such as multi-speaker synthesis and zero-shot voice cloning, set it apart as a tool for creating dynamic and customized voice applications. The project's active GitHub repository and community ensure it continues to evolve.
Coqui-TTS is an excellent choice for developers who need a robust, self-hosted toolkit with advanced features like voice cloning and the ability to train custom models.
Website: https://github.com/idiap/coqui-ai-TTS
NVIDIA NeMo is an open-source conversational AI toolkit built for researchers and developers working on high-performance models. While it covers the full speech AI spectrum, its contribution to the open source text to voice landscape is significant, providing a powerful framework for training new TTS models and fine-tuning existing ones. It is built on PyTorch and is designed from the ground up to leverage the full power of NVIDIA GPUs for accelerated training and inference.
NeMo provides a collection of pre-trained models and "recipes" that serve as excellent starting points for custom projects. Its standout feature is its production-oriented design, integrating seamlessly with NVIDIA Riva for deploying highly optimized, low-latency TTS services at scale. The framework includes robust tools for one of the most challenging parts of TTS: text normalization and processing. This makes it ideal for applications that need to handle complex, unstructured text with numbers, dates, and abbreviations.
NVIDIA NeMo is the go-to choice for teams with access to NVIDIA hardware who need to build and deploy custom, high-performance TTS models for production environments.
Website: https://github.com/NVIDIA/NeMo
For developers and researchers deeply integrated into the Google ecosystem, TensorFlowTTS provides a comprehensive toolkit for building and deploying open source text to voice models using TensorFlow 2. This repository offers high-quality implementations of popular architectures, including Tacotron 2 and FastSpeech 2, paired with modern vocoders like MelGAN and HiFi-GAN. Its primary focus is on providing a robust framework for training and inference within the TensorFlow environment.
The project stands out for its practical deployment examples, particularly for on-device and mobile applications. It includes clear documentation and Colab notebooks demonstrating how to convert models to TensorFlow Lite (TFLite) for real-time inference on platforms like Android. With pre-trained models available for multiple languages, it serves as an excellent starting point for projects that require low-latency, offline speech synthesis and are built on the TensorFlow stack.
TensorFlowTTS is the go-to solution for teams committed to the TensorFlow ecosystem, especially those targeting Android or other edge devices where TFLite offers a significant performance advantage.
Website: https://github.com/TensorSpeech/TensorFlowTTS
ESPnet, which stands for End-to-End Speech Processing Toolkit, is a comprehensive and powerful framework primarily designed for speech research. While it covers various tasks like Automatic Speech Recognition (ASR), its TTS capabilities are state-of-the-art. It's less of a plug-and-play tool and more of a unified, open-source environment for training, evaluating, and deploying high-fidelity speech synthesis models. ESPnet provides researchers and advanced developers with reproducible "recipes" for training models on well-known datasets like LJSpeech.
The toolkit's main advantage is its integrated design, allowing for seamless experimentation across TTS, ASR, and even voice conversion within the same workflow. Instead of just offering a pre-trained model, ESPnet gives you the entire pipeline to create your own. This makes it an exceptional open source text to voice resource for academic purposes or for companies looking to build a deeply customized, proprietary TTS engine from the ground up using cutting-edge architectures.
ESPnet is the ideal choice for academic researchers or R&D teams who need a powerful, flexible, and reproducible environment for pushing the boundaries of speech synthesis technology.
Website: https://github.com/espnet/espnet
Parler-TTS is an innovative open source text to voice library and model collection developed by Hugging Face that focuses on generating high-quality, expressive speech guided by simple text prompts. Instead of selecting from a fixed list of voices, users can describe the desired audio characteristics like gender, speaking rate, pitch, and even background noise. The project stands out for its commitment to transparency, providing fully open weights, training recipes, and reproducible configurations.
This prompt-based control allows for a remarkable degree of creativity and nuance in the generated audio. For instance, a prompt could be "A high-pitched, female voice speaking quickly with a slight reverb." The library is built for performance, incorporating modern optimizations like Flash Attention to ensure efficient inference. It is distributed via the Hugging Face ecosystem, making it easy for developers to integrate using the familiar transformers library. Parler-TTS is an excellent choice for projects requiring highly customizable and natural-sounding speech synthesis.
Parler-TTS is ideal for developers who need more than just standard voice fonts and want to dynamically shape the characteristics of the generated speech with an entirely open framework.
Website: https://github.com/huggingface/parler-tts
Developed by Suno AI, Bark is a transformer-based generative audio model that goes beyond traditional speech synthesis. It is designed to create highly realistic, multilingual speech but can also generate other audio like music, background noise, and simple sound effects. This unique capability makes it a powerful tool for creative applications, setting it apart from more conventional open source text to voice systems focused solely on clean narration.
Bark’s approach is fundamentally different; it's a text-to-audio model, not just text-to-speech. This means it can interpret non-speech cues in the input text, like [laughs] or [sighs], and generate corresponding sounds, adding a layer of expressiveness that is difficult to achieve with other models. Released under a permissive MIT license, Bark is easily accessible for both commercial and personal projects. The official GitHub repository provides straightforward pip install instructions and notebook examples to get started quickly.
Bark is an excellent choice for projects where creative expression and atmospheric audio are more important than perfectly precise, robotic narration.
Website: https://github.com/suno-ai/bark
| Tool | Core features | Quality & UX | Price / Value | Target audience | Standout |
|---|---|---|---|---|---|
| Hugging Face – Text-to-Speech hub | ✨ Repo of 1000s models, hosted demos, inference endpoints | ★★★–★★★★ (model‑dependent) | 💰 Browse free; hosted endpoints paid | 👥 Devs, researchers, evaluators | ✨Huge model variety · 🏆Best for discovery |
| Piper (Open Home Foundation) | ✨ Lightweight ONNX voices, CLI/Python, CPU/edge focus | ★★★ (very fast on CPU) | 💰 Free/open; easy self‑host | 👥 Edge devs, Home Assistant users | ✨Edge‑optimized · 🏆Fast CPU inference |
| Home Assistant – Piper integration | GUI setup, autodiscovery, speaker routing | ★★★★ (user‑friendly) | 💰 Free with Home Assistant | 👥 Smart‑home users, non‑devs | ✨Plug‑and‑play HA routing |
| eSpeak‑NG | Formant TTS, 100+ languages, tiny footprint | ★★ (robotic but fast) | 💰 Free/open; ultra‑lightweight | 👥 Embedded systems, accessibility | ✨Tiny footprint · 🏆Broad language support |
| MaryTTS | Java server, REST API, voice installers | ★★★ (stable, older voices) | 💰 Free/open; good for Java stacks | 👥 Java devs, local server deployments | ✨Mature Java platform · 🏆Stable for local use |
| Festival | Multi‑voice techs, Scheme scripting, C++ API | ★★★ (hackable, research‑oriented) | 💰 Free/open | 👥 Researchers, educators | ✨Highly extensible · 🏆Great for teaching/research |
| Coqui‑TTS | Many architectures, pretrained checkpoints, Docker | ★★★★ (neural quality varies) | 💰 Free/open; GPU recommended | 👥 Researchers & devs with GPUs | ✨Feature‑rich toolkit · 🏆Strong community support |
| NVIDIA NeMo | PyTorch recipes, text norm, GPU containers | ★★★★–★★★★★ (with GPUs) | 💰 Free code; best with NVIDIA HW | 👥 Enterprise, GPU users | ✨Production tooling & GPU accel · 🏆Enterprise grade |
| TensorFlowTTS | TF2 models, vocoders, TFLite/mobile examples | ★★★★ (TF/TFLite friendly) | 💰 Free/open; mobile focus | 👥 TF developers, mobile engineers | ✨TFLite/mobile support |
| ESPnet | Unified ASR/TTS, SOTA recipes, Colab demos | ★★★★–★★★★★ (research SOTA) | 💰 Free/open; research‑centric | 👥 Researchers, reproducible experiments | ✨SOTA recipes · 🏆Research benchmarks |
| Parler‑TTS | Promptable style control, open weights & recipes | ★★★★–★★★★★ (high fidelity) | 💰 Free/open; heavy HW for best results | 👥 Researchers, high‑fidelity devs | ✨Prompt style control · 🏆Transparent training |
| Bark (Suno) | Generative text→audio (speech + music/effects) | ★★★★ (expressive/creative) | 💰 MIT licensed; GPU helps | 👥 Creators, experimenters | ✨Music & SFX generation · 🏆Creative versatility |
Navigating the vibrant landscape of open source text to voice technology reveals a powerful truth: high-quality, customizable speech synthesis is more accessible than ever before. We've explored a wide array of tools, from the venerable and lightweight eSpeak-NG to the cutting-edge, near-human quality of models like Bark and VITS-based systems like Piper. Each project offers a unique set of trade-offs, underscoring the central theme that the "best" solution is entirely dependent on your specific project requirements.
Your journey began with a need for synthetic voice, and now you are equipped with the knowledge to make an informed decision. The core takeaway is that the choice is no longer just about finding any tool, but about finding the right tool that aligns with your technical expertise, infrastructure capacity, and desired user experience.
As you weigh your options, the decision between a self-hosted open source model and a managed API hinges on a few critical factors. Reflecting on these will illuminate the most practical path forward for your application.
With this comprehensive overview, your path forward is clearer. Don't let analysis paralysis set in; it's time to experiment.
Ultimately, the world of open source text to voice empowers you to build more immersive, accessible, and engaging applications. Whether you choose the path of ultimate control by fine-tuning your own models or the path of efficiency by leveraging a managed service, you are building on the incredible progress of a global community. The voice you create is now an integral part of your user's experience, so choose the tool that lets you build it with confidence and quality.
If your goal is to achieve production-grade performance without the heavy lifting of managing infrastructure, consider a managed API built for developers. Lemonfox.ai offers a high-quality, affordable, and incredibly fast Speech-to-Text API, allowing you to focus on your application while we handle the complexity of the AI models. Explore our simple and powerful API at Lemonfox.ai.