First month for free!
Get started
Published 12/16/2025
From asking your smart speaker for the weather to seeing live captions pop up on a video call, speech-to-text models have woven themselves into the fabric of our daily lives. These aren't just simple dictation tools; they are complex AI systems that convert spoken language into written text. Think of them as digital interpreters, constantly learning to pick up on not just words, but also context, dialect, and even the subtle nuances of human speech.
At its heart, a speech-to-text model is a bridge between how we talk and how computers "think." It takes the messy, unstructured soundwaves of our voice and systematically turns them into clean, usable text. This simple-sounding process has unlocked incredible potential, making voice—our most natural communication method—a powerful way to interact with technology.
This guide will pull back the curtain on the AI doing all that heavy lifting. We’ll explore the key technologies driving this revolution, size up the leading model architectures like Whisper and Wav2Vec2, and get into the metrics that really matter when measuring performance.
Early speech recognition systems were clunky and limited. You had to speak slowly, enunciate perfectly, and stick to a small set of commands. Today's models are in a completely different league, easily handling natural, conversational speech even with background noise. This huge leap is all thanks to breakthroughs in deep learning and the availability of enormous datasets for training.
Modern systems can now:
The ripple effects of this technology are everywhere. It’s the engine running your favorite voice assistant, the accessibility feature generating automatic captions, and the analytical tool helping call centers understand customer sentiment.
Every time you dictate a text message, ask a smart home device to play a song, or see live subtitles scroll across a news feed, you're interacting with a speech-to-text model. It has quietly become a fundamental layer of how we experience the digital world.
By the end of this guide, you’ll have a clear map to the speech-to-text landscape. You'll know how to evaluate the options and choose the right model for your project, turning abstract AI concepts into practical, real-world solutions. Let's dive in and see how they work, why they’re so important, and how you can put them to work.
Today’s instant, accurate transcription didn’t just appear out of nowhere. It's the result of a long, winding road of innovation that started long before AI was a household name. The dream of a machine that could understand human speech was once pure science fiction, something you’d only see in ambitious research labs.
The very first attempts weren't about "intelligence" at all; they were more about brute-force pattern matching, run on machines that took up entire rooms. These pioneers laid the essential groundwork, and every small step they took became a crucial building block for the powerful speech-to-text models we use every single day.
The story really gets going in the 1950s. Back in 1952, Bell Laboratories unveiled 'Audrey,' a colossal machine that could recognize spoken digits from zero to nine. It hit an impressive 90% accuracy rate, but there was a catch—it only worked for the voice of its inventor. This really highlights how dependent these early systems were on a single speaker.
A decade later, IBM showed off its 'Shoebox' machine at the 1962 Seattle World's Fair. It was a bit smaller and could understand 16 spoken English words, not just digits. It could even do basic math from a voice command. This was a huge leap, though it still required you to speak isolated words very carefully. You can dig deeper into these early systems and the evolution of speech to text technology on norango.ai.
Here’s a look at the historic IBM Shoebox, a key milestone in voice recognition.
While it looks primitive now, the Shoebox proved that direct human-to-machine voice interaction was truly possible. It was a clear sign of the potential locked away in spoken language.
The 1970s became a major turning point, mostly thanks to a big push from DARPA, the U.S. Department of Defense's research arm. This funding shifted the entire field's focus from recognizing a few words from one person to something much, much bigger.
The new goals were incredibly ambitious and set the stage for the systems we have today:
This period of intense, government-backed research was absolutely fundamental. It sparked competition and collaboration between universities, leading to core statistical methods like Hidden Markov Models (HMMs) that would dominate the field for the next couple of decades.
This government push was the catalyst that took speech recognition from a lab curiosity and put it on the path to becoming a viable technology. It cracked many of the foundational problems that needed to be solved for real-world use.
The groundwork from the DARPA projects finally led to the first commercial products in the 1990s. Systems like Dragon Dictate brought speech-to-text to personal computers for the first time. They were revolutionary, but they still needed a lot of patient training and often stumbled on accuracy.
The real explosion in performance came from two game-changers: big data and cloud computing. As the internet boomed, companies like Google suddenly had access to an unbelievable amount of human language—billions of hours of audio and trillions of words of text. That massive scale, combined with the raw power of the cloud, made it possible to train deep neural networks.
This shift allowed models to finally learn the incredibly subtle and complex patterns of human language in a way that was never possible before. It's what led directly to the accurate, always-on speech-to-text models that power so much of our modern world.
To really get what makes modern transcription so accurate, we need to pop the hood and look at the different kinds of speech to text models. These architectures are the engines driving everything from your phone’s voice assistant to the massive transcription systems used by big companies. Broadly speaking, they fall into two camps: the older, multi-part hybrid systems and the newer, all-in-one end-to-end models.
Think of a classic hybrid model like an old-school assembly line. First, an Acoustic Model listens to the raw audio, breaking it down into basic phonetic sounds—the "c," "a," and "t" in "cat." Then, a separate Language Model acts as the quality control inspector, using a massive dictionary and grammar rulebook to figure out that "the cat sat" is a far more likely phrase than "the cat sat tack." The system stitches these two outputs together to produce the final text.
This approach was the gold standard for decades, but it had its issues. Juggling and training multiple complex components was a headache. It was often rigid and could easily get tripped up by the messy, unpredictable nature of how people actually talk.
Today, the field has largely moved on to end-to-end models. This was a fundamental shift. Instead of a multi-stage assembly line, an end-to-end model is more like a single, highly skilled artisan who handles the entire process from start to finish. It’s one unified neural network trained to map raw audio directly to text.
This integrated design is what makes them so powerful. They learn complex accents, background noise, and conversational quirks directly from the data, leading to a huge leap in accuracy. The timeline below really shows how far we've come from those early, clunky systems.
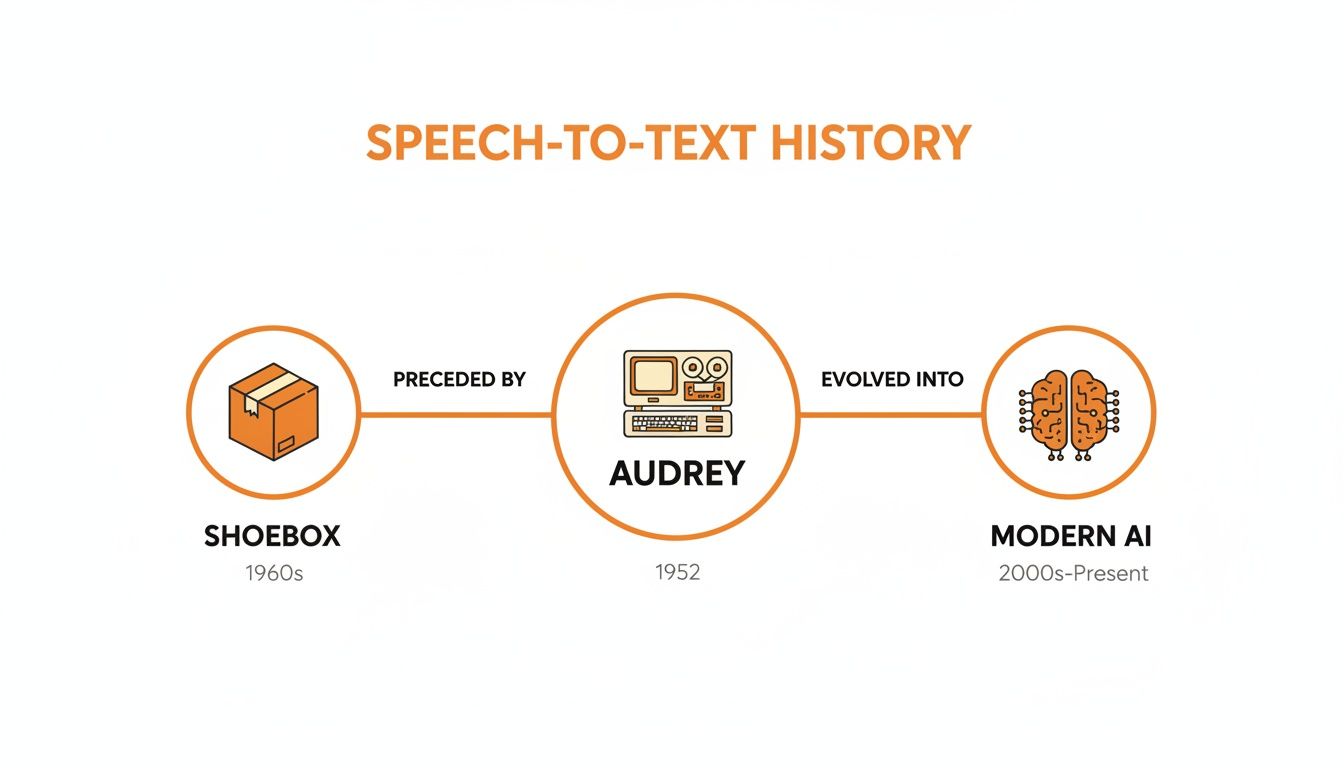
You can see the journey from single-purpose machines like 'Audrey' and 'Shoebox' to the sophisticated, data-hungry AI that defines speech recognition today.
One of the biggest breakthroughs recently has been the rise of self-supervised learning, with Meta AI's Wav2Vec2 being a prime example. For years, the biggest bottleneck in training a speech model was getting enough high-quality, human-transcribed audio. It's an incredibly expensive and time-consuming process.
Self-supervised learning offers a clever workaround.
Think of it like a baby learning to understand speech. Long before they can read or write, they listen to thousands of hours of spoken language, picking up on patterns, tones, and the underlying structure of the language all on their own.
That's essentially what Wav2Vec2 does. The model is fed huge amounts of unlabeled audio, and parts of it are masked out. Its job is to predict the missing sounds based on the context. After this "pre-training," it has a deep understanding of the language. From there, it only needs a much smaller, manageable set of labeled data to be "fine-tuned" for a specific task, achieving incredible accuracy. This efficiency is a game-changer, making top-tier transcription from services like Lemonfox.ai both accessible and affordable.
Even within the end-to-end family, there are a few dominant architectures, each with its own personality and strengths.
RNN-T (Recurrent Neural Network Transducer): This is the go-to for real-time transcription. Because it processes audio in a continuous stream, it can output text almost instantly. It’s perfect for live captioning or voice commands where you can't have a delay.
Conformer: The Conformer is a brilliant mix of two powerful ideas. It uses convolutions (great for picking up on local details in the audio) and the attention mechanism from Transformers (great for seeing the big picture and understanding context across long sentences). This "best of both worlds" approach has pushed it to the top of many performance leaderboards.
Transformer-Based Models (e.g., Whisper): Made famous by OpenAI's Whisper, these models use the same powerful Transformer architecture that has shaken up the world of text-based AI. Trained on a mind-bogglingly diverse dataset from the internet, Whisper is incredibly tough, handling background noise, various accents, and nearly 100 different languages with ease.
To make these differences clearer, here's a quick cheat sheet comparing the main architectures.
This table provides a high-level comparison of the dominant speech to text architectures, highlighting their primary approach, key strengths, and common use cases to help readers quickly grasp their differences.
| Architecture | Core Principle | Key Strength | Best For |
|---|---|---|---|
| Hybrid (Legacy) | Separate Acoustic and Language models work together. | Established and well-understood technology. | Older systems or specific, highly-controlled environments. |
| RNN-T | Processes audio sequentially for real-time output. | Low latency and ideal for streaming. | Live captioning, voice commands, and real-time assistants. |
| Conformer | Combines convolution and attention mechanisms. | State-of-the-art accuracy on many benchmarks. | High-accuracy transcription where latency isn't the top priority. |
| Transformer (e.g., Whisper) | Processes entire audio sequences to capture global context. | Robustness to noise, accents, and multiple languages. | Offline transcription of diverse and challenging audio files. |
Each of these models represents a different philosophy for tackling the same core problem: turning spoken words into written text. The one you choose depends entirely on what you're trying to accomplish.
Picking the right speech-to-text model isn't as simple as looking for a single "accuracy" score. To really know what you're getting, you have to dig into a few key metrics. It’s a bit like buying a car—you wouldn’t just ask about the top speed. You’d want to know about fuel efficiency, handling, and safety, too. Each metric tells a different part of the story.
The single most important number in the world of speech recognition is the Word Error Rate (WER). This is the industry-standard yardstick for measuring how closely a transcription matches the original audio. Simply put, a lower WER means fewer mistakes, and that's always a good thing.
WER is more than just a simple percentage of wrong words. It’s a clever calculation that captures the different ways a model can mess up a transcription. The formula breaks down errors into three specific types:
You take all those mistakes, add them up, and divide by the total number of words in the original, perfect transcript (N).
WER = (S + D + I) / N
Let's make this real. Imagine someone says: "the quick brown fox"
But the model's transcription comes back as: "the quick brown box jumped"
Here’s the breakdown:
Plugging this into the formula, you get (1 + 0 + 1) / 4 = 0.50. That’s a 50% WER. This little formula gives you a standardized, no-nonsense way to compare the raw accuracy of any two models.
Accuracy is king, but it doesn't exist in a vacuum. For many real-world applications, how fast you get the text back is just as crucial. This is where you need to look at latency and throughput.
Latency is all about the delay. It’s the time that passes from when the audio goes in to when the transcription comes out. For anything happening live—think real-time captions for a meeting or a responsive voice assistant—low latency is a dealbreaker. Too much lag and the whole experience falls apart.
Throughput, on the other hand, is about bulk processing power. It measures how much pre-recorded audio a system can chew through in a set amount of time. If you need to transcribe a massive archive of call center recordings, high throughput is your best friend. It means you can process your audio backlog faster and with less computational horsepower, saving you time and money.
Choosing a speech-to-text model is fundamentally about navigating these trade-offs. The most accurate model on the market might be painfully slow and incredibly expensive to run. Conversely, a zippy little model that runs on a phone might be perfect for a mobile app, even if its WER is a few points higher.
The good news is that modern models have made astonishing progress. Back in 2017, the best systems from major tech companies were hitting a 5% WER on common benchmarks, which is roughly on par with professional human transcribers. More recently, models like OpenAI's Whisper have completely changed the game, showing incredible accuracy in nearly 100 languages, even with background noise. That's what happens when you train a model on a staggering 680,000 hours of diverse audio. You can learn more about this journey from the evolution of speech to text API performance on krisp.ai.
Ultimately, you have to decide what matters most for your project. Do you need near-flawless accuracy for medical dictation, or is instant responsiveness for a customer service bot the top priority? Understanding WER, latency, and throughput gives you the framework to make a smart decision that truly fits your needs.
Moving from theory to practice with speech-to-text models requires a solid game plan. The market is full of fantastic options, so the goal isn't to find the single "best" model, but the one that's the absolute best fit for your specific job. This all starts with asking the right questions before you even think about writing a line of code.
Your first big decision point is all about timing. Are you building an application that needs real-time streaming for live captions or a voice assistant that has to respond instantly? Or are you doing batch processing on a huge archive of recorded audio files? The answer immediately splits the road, as models built for low latency (like RNN-T architectures) are engineered very differently from those designed for pure throughput.
Then, think about the audio itself. Will your model be operating in a noisy environment, like a busy call center or a factory floor? Or will it be listening to clean, studio-quality recordings? This helps you figure out how much to prioritize a model's robustness—a key advantage of massive models like Whisper, which learned from the wild and unpredictable audio of the internet.
To make a smart decision, you need to first outline your non-negotiables. Think of this as your checklist for comparing different speech-to-text models and providers.
Getting this down on paper first will help you build a shortlist of models that actually align with your project, saving you from wasting time on a poor technical match.
Another critical fork in the road is deciding where the model will run. You can either tap into a cloud-based API service or deploy a model on your own infrastructure (often called "on-premise"). Each path comes with its own set of pros and cons.
A cloud API, like the one from Lemonfox.ai, is the quickest way to get up and running. You send an audio file to their servers through a simple API call and get the transcript back. This approach gives you simplicity, massive scalability, and access to state-of-the-art models without the headaches of managing servers. For most businesses, the low upfront investment and pay-as-you-go pricing make it the most logical choice.
Deploying a model on-premise gives you maximum control and privacy, as your audio data never leaves your servers. However, this comes with the significant responsibility and cost of managing the required hardware, software updates, and security.
Here’s a quick breakdown to help you weigh the options:
| Factor | Cloud API (e.g., Lemonfox.ai) | On-Premise Deployment |
|---|---|---|
| Setup Speed | Fast (minutes to hours) | Slow (days to weeks) |
| Cost Structure | Pay-per-use, low initial cost | High upfront hardware cost |
| Maintenance | Handled by the provider | Your responsibility |
| Privacy | Data sent to a third party | Maximum data privacy |
| Scalability | Easy to scale up or down | Requires capacity planning |
For developers and businesses who need an efficient, powerful, and affordable solution, an API like Lemonfox.ai is often the perfect place to start. It lets you integrate top-tier transcription quickly, often with built-in features like speaker recognition and support for over 100 languages.
Sometimes, an off-the-shelf model just won't cut it, especially when you need peak accuracy with highly specialized language. This is where fine-tuning enters the picture. Fine-tuning is the process of taking a powerful, general-purpose model and training it just a little bit more on your own curated dataset of audio and matching transcripts.
Imagine a law firm that wants to transcribe depositions. By fine-tuning a base model on thousands of hours of their own recordings, the model essentially becomes an expert in legal terminology. It learns to perfectly transcribe words like "subpoena" or "affidavit" that a general model might trip over. This process adapts the model to your unique linguistic world, pushing its accuracy to the absolute limit for that specific job. It's more work, but for niche applications, the performance boost can be a game-changer.

The real magic of speech-to-text isn't in the algorithms themselves, but in how they solve tangible problems out in the world. When we move past the technical jargon, we see these models creating genuine value by converting spoken words into structured, usable data. The applications are surprisingly diverse and are quietly reshaping how businesses work.
Take customer service, for instance. Call centers use real-time transcription to keep a finger on the pulse of their customer interactions. This isn't just about record-keeping; it's about powering live sentiment analysis to flag frustrated callers for immediate supervisor intervention. It also gives managers objective transcripts for coaching agents, helping them sharpen their skills.
Healthcare has been completely changed by this technology. Physician burnout is a serious problem, often driven by the mountain of administrative work. Speech-to-text models, like Nuance's Dragon Medical, cut right through that. They let doctors dictate clinical notes naturally, shaving hours off their screen time and letting them get back to focusing on patients.
Media companies are also huge adopters. Imagine trying to find a specific quote in thousands of hours of video archives. By automatically transcribing their content, they make their entire library instantly searchable. This same process also generates captions, which makes content accessible and gives search engines a trove of text to index, boosting SEO.
On a more personal level, one of the most common uses is simply translating voicemail to text for convenience, a small but significant time-saver for millions.
Of course, the most obvious success story is sitting in our pockets and on our kitchen counters. Voice assistants are everywhere. While the groundwork was laid in the 90s and early 2000s, it was Apple's Siri in 2011, followed by Amazon's Alexa and Microsoft's Cortana in 2014, that made voice interaction mainstream.
By 2017, the best models from these tech giants hit a critical milestone: a 5% word error rate (WER) on clean audio, effectively matching human performance.
These success stories aren't just about convenience. They demonstrate a direct line from a specific model architecture—like a low-latency RNN-T for a voice assistant or a high-accuracy Conformer for medical notes—to solving a critical business problem.
Each use case is a testament to how finding the right balance of accuracy, speed, and cost can open up entirely new ways of doing things.
As you dive into the world of speech-to-text models, a few common questions always seem to pop up. Let's tackle them head-on to clear up any confusion and give you a better sense of how this technology works in the real world.
This is a great question. Think of it this way: speech recognition is focused entirely on the what. Its job is to listen to a piece of audio and convert the spoken words into a text transcript.
Speaker diarization, on the other hand, answers the who and when. It’s the process that chops up an audio file and assigns different segments to different speakers. Modern systems often merge these two, giving you a transcript that not only shows what was said but also attributes each line to the correct person. This is a game-changer for transcribing meetings or multi-person interviews.
Top-tier models get their power from being trained on enormous datasets filled with voices from all over the globe. This massive exposure to different accents and dialects helps them become surprisingly good at understanding a wide variety of speakers right out of the box.
But what if you need to handle a very specific regional accent? That's where fine-tuning comes in. You can take a powerful, pre-trained model and give it some extra training on a smaller dataset of your target accent. This sharpens its performance for that specific group without having to build a whole new model from scratch.
Fine-tuning is like giving a generalist doctor a specialty in cardiology. The model already has a deep, foundational knowledge of language; you're just providing focused training to make it an expert in a specific area.
Absolutely. Many of the best models are built for what's called "streaming" transcription. They're engineered for low latency, meaning they process audio in tiny, continuous chunks and spit out the text almost instantly.
This real-time capability is what powers some of the most familiar voice applications out there:
It’s this near-instant feedback that makes interacting with voice technology feel so natural and seamless.
Ready to put fast, accurate transcription to work in your own application? With Lemonfox.ai, you get access to a state-of-the-art Speech-to-Text API that’s both affordable and incredibly easy to integrate. Start your free trial and get 30 hours of transcription today.