First month for free!
Get started
Published 10/3/2025

At its most basic level, speech synthesis is the technology that gives a voice to your devices. You might know it better as Text-to-Speech, or TTS. It’s the magic behind your GPS giving you turn-by-turn directions, your phone reading a text message aloud, or a virtual assistant answering your questions.
Essentially, it’s the process of teaching a computer to read.
Think of synthesis of speech as a sophisticated translation job. It takes the text we can read and converts it into sound waves that sound just like a person talking. This isn't just playing back a pre-recorded file; it's a dynamic, real-time creation of a voice that can read any text you give it.
This whole process boils down to three core stages. Each one hands off its work to the next, starting with simple letters and ending with a rich, audible voice.
Let's walk through how a computer actually learns to talk.
The first step is all about understanding the text. Before a computer can speak, it has to read—and comprehend. This initial phase, called text analysis, is like a meticulous editor preparing a script.
The system performs a couple of crucial tasks here:
This analysis ensures the machine knows exactly what to say and how to pronounce it before it even thinks about making a sound.
With the phonetic map ready, the system moves on to actually building the voice. This is where the magic really happens. The phonetic blueprint is used to generate a detailed acoustic model, which is often visualized as a spectrogram.
A spectrogram is a picture of a sound. It shows the sound's frequencies and intensity over time, capturing the unique timber and tone of a voice—much like a vocal fingerprint.
This visual map of the sound is then handed off to a component called a vocoder. The vocoder’s job is to take that spectrogram and turn it into the final digital audio waveform—the sound file we can actually hear.
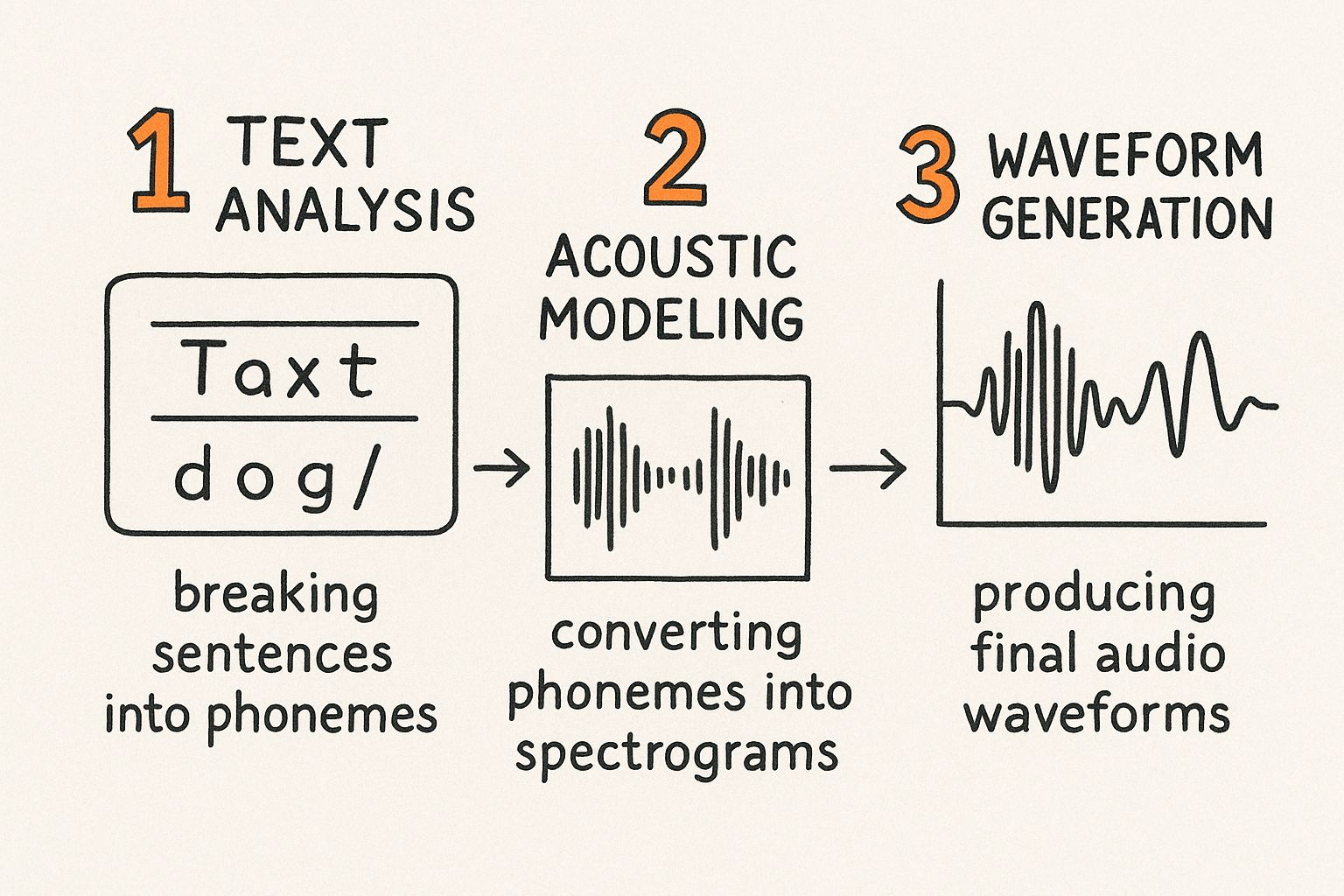
This entire workflow, from text analysis to the final audio, shows how abstract words on a page are transformed into the rich, nuanced sound of a human voice.
To put it all together, here’s a simple breakdown of the entire process.
This table summarizes the fundamental steps that turn text into audible speech.
| Stage | Process | Analogy |
|---|---|---|
| 1. Text Analysis | The system normalizes text (e.g., "$5" -> "five dollars") and converts words into phonetic units (phonemes). | A musician reading sheet music for the first time, understanding the notes and rhythm before playing. |
| 2. Acoustic Modeling | The phonetic information is converted into a detailed acoustic representation, like a spectrogram. | The musician imagining how the notes on the page should sound, planning the pitch, tone, and tempo. |
| 3. Waveform Generation | A vocoder translates the acoustic model into an actual digital audio file that can be played as sound. | The musician finally playing the instrument, turning the planned notes into real, audible music. |
Each stage is a critical piece of the puzzle, working together to create a voice that sounds natural and clear. This structured approach is what allows modern TTS systems to handle virtually any text thrown at them.
To really get a feel for how incredible today’s human-like AI voices are, it helps to rewind the clock. Way back. The journey to teach machines how to talk didn't start with neural networks or cloud computing. It began with bellows, reeds, and complex mechanical contraptions that tried to copy the human vocal tract.
These early "talking machines" were genuine marvels of engineering for their time. Picture an inventor in the 18th century, carefully putting together a device with a rubber mouth and nose, trying to physically force air through it to make speech sounds. They were clunky and crude, but these experiments laid the foundation for the entire field of speech synthesis.
The game really changed with the arrival of electronics. Mechanical parts were swapped out for circuits and vacuum tubes, turning the challenge from a physical one into an electronic one. This was the true starting point for modern voice synthesis as we know it.
The mid-20th century was a hotbed for acoustics research, and the idea of an electronic voice went from science fiction to reality. Instead of building a physical "mouth," engineers figured out how to generate the fundamental sounds of human speech using electronic signals.
One of the first major breakthroughs was a technique called formant synthesis.
Think of formants as the unique frequencies that give vowels their character. It's the reason your brain can instantly tell the difference between an "ee" and an "oo," no matter who is speaking. The earliest synthesizers worked by recreating these specific frequencies.
This was a huge leap forward. For the first time, a machine could create understandable vowel sounds without a single moving part. This gave birth to that classic robotic, monotone voice that defined computers in pop culture for decades.
Building on these early ideas, the 1950s and 60s saw a flurry of innovation. Researchers at places like Haskins Laboratories and Bell Labs were laying the groundwork for everything we have today. They built devices that could turn pictures of sound waves (spectrograms) back into audible speech, proving the direct link between acoustic patterns and how we hear them.
A key milestone from this era was the Pattern Playback synthesizer, created by Franklin Cooper in 1951 at Haskins Laboratories. You can dive deeper into the history of these early machines, but they were foundational.
This period also gave us another critical technology: Linear Predictive Coding (LPC).
Put simply, LPC was a much smarter way to model the vocal tract. Instead of just recreating a few key frequencies, it analyzed a speech signal to predict the next sound based on the ones that came before it. This method was incredibly good at creating a compact digital blueprint of a person's voice.
The most famous example of LPC in action was the Texas Instruments Speak & Spell, that iconic educational toy from 1978. The fact that it could speak words aloud from a single chip was a direct result of all that LPC research. From these early electronic murmurs, the path was paved for the sophisticated systems we use for everything from GPS navigation to helping people communicate.
The journey from clunky, electronic voices to the fluid, lifelike assistants on our phones is a story of a few key technological leaps. As computers got more powerful, so did our methods for creating speech. Today’s synthesis of speech is dominated by three main approaches, each with its own philosophy on how to build a believable voice from scratch.
These methods show a clear evolution, moving from what was essentially a cut-and-paste job to generating sound entirely from data. Understanding them helps explain why some AI voices sound remarkably human while others still have that tell-tale robotic edge.
Let’s break down how each one works.
Imagine you have a gigantic library of sound files—every single sound a person can make, all recorded by one speaker. Concatenative synthesis works by dipping into this library, finding the right audio snippets (phonemes, syllables, or even whole words), and stitching them together to form sentences.
This was a huge step forward from earlier electronic methods. Because it uses real human recordings as its building blocks, it can achieve incredibly high-quality, natural-sounding results for the specific voice it was trained on.
But this method has its weak spots. The seams between the stitched-together sounds can sometimes be obvious, creating a choppy or unnatural flow. This is especially true if the text requires an emotional tone or inflection that wasn’t in the original recordings. Plus, the massive audio database needed makes it bulky and inflexible.
Parametric synthesis takes a completely different path. Instead of storing a library of actual sounds, it holds a compact mathematical model—think of it as a "recipe" for producing speech. This recipe contains all the key ingredients, like vocal frequency, tone, and other acoustic properties.
When you give it text, the system follows this recipe to generate the sound from the ground up. This makes it far more flexible and efficient, requiring a tiny fraction of the storage space compared to concatenative systems. It also makes it easy to modify the voice's pitch, speed, or emotion just by tweaking the parameters in the recipe.
The trade-off is often in the final quality. The voices are perfectly clear, but they can sometimes sound a bit buzzy or artificial. After all, they are a mathematical approximation of a human voice, not the real thing.
Key Insight: The move from concatenative to parametric synthesis was a major shift from "assembling" a voice to "generating" one from a model. It prioritized flexibility and efficiency over the raw, pre-recorded sound of the older method.
This evolution really picked up steam through the 1970s and 80s. A great example is Dennis Klatt's KlattTalk System in 1981, which became a cornerstone for many future systems and was famously adapted to create Stephen Hawking's voice synthesizer.
This is the newest and most powerful approach, and it completely changed the game. Instead of being programmed with rules or parameters, a neural network learns how to generate speech by analyzing thousands of hours of real human voices.
Models like WaveNet, a trailblazer in this field, actually learn to create the raw audio waveform one sample at a time. This allows them to capture the incredibly subtle details of human speech—things like breath, pauses, and nuanced intonation. The result is a level of realism that was once pure science fiction.
Neural TTS can produce stunningly expressive and lifelike voices. Companies like Lunar Bloom AI are pushing the boundaries of what's possible with this technology. The main downside? These models are serious resource hogs, demanding a lot of processing power to train and operate.
Each approach to the synthesis of speech comes with its own set of trade-offs. The best choice really depends on the end goal, whether it’s a high-fidelity audiobook narration or a simple voice alert on a low-power device.
Here's a quick look at how the three main techniques stack up against each other.
| Technique | How It Works | Pros | Cons |
|---|---|---|---|
| Concatenative | Stitches together pre-recorded audio snippets from a large database. | Very natural-sounding for the source voice; high fidelity. | Large storage required; can sound choppy; inflexible. |
| Parametric | Generates speech using a compact mathematical model and acoustic parameters. | Small footprint; highly flexible and controllable (pitch, speed). | Can sound buzzy or less natural than concatenative methods. |
| Neural Network | A deep learning model learns to generate raw audio waveforms from scratch. | Extremely natural and expressive; can capture subtle nuances. | Computationally expensive; requires large training datasets. |
Ultimately, the rise of neural networks represents the current peak in the long quest for a truly human-sounding artificial voice. We've moved beyond simply assembling or modeling sound to a process of genuine audio creation.
Talking machines once felt like pure science fiction, but today, speech synthesis is so woven into our routines that we barely notice it. It's the helpful, disembodied voice that has become an ordinary part of our world—guiding us, entertaining us, and making technology feel more human.
Chances are, you interact with it constantly. When you ask your smart speaker for the weather or hear your GPS calmly reroute you through traffic, you're experiencing speech synthesis in action. The technology has become so smooth and reliable that we often take it for granted.
Its journey from a lab experiment to an everyday tool really took off with personal computers and the internet. The PCs of the 1990s brought early synthesis software into homes, but it was the boom in processing power and data analysis in the 2000s that truly changed the game. The stunningly natural voices we hear from virtual assistants today are a direct result of those breakthroughs, especially the shift to neural networks that can generate incredibly lifelike speech.
Perhaps the most profound impact of speech synthesis is in accessibility. For people with visual impairments, this technology is nothing short of a lifeline, opening up a digital world that might otherwise be closed off.
Screen readers are the perfect example. These tools use speech synthesis to read aloud everything on a screen—from website text and emails to app buttons and system menus. It’s what allows someone to navigate a smartphone or computer with the same ease as a sighted person.
Speech synthesis isn't just a cool feature; it's a cornerstone of digital equality. It tears down barriers and ensures that information and online services are available to everyone, regardless of their physical abilities.
And it goes far beyond just screen readers. The applications for accessibility are broad and powerful:
In the business world, speech synthesis is the voice that works around the clock. It drives automated systems that field millions of customer interactions every single day, creating efficiency for companies and on-demand convenience for us.
Think about the last time you called your bank or an airline. That polite, automated voice guiding you through the menu was powered by speech synthesis. These Interactive Voice Response (IVR) systems are essential for helping large organizations manage huge call volumes without making everyone wait for a human agent.
You’ll also hear it in public spaces. The calm, clear announcements at airports, train stations, and bus terminals are all delivered by TTS. That voice telling you about a gate change or the next stop is a perfect example of speech synthesis working reliably on a massive scale.
The creative world has also found incredible uses for speech synthesis. In video games, for example, it can generate dynamic dialogue for background characters, making game worlds feel more alive and reactive without developers having to record thousands of lines of audio.
For content creators, the technology is a massive time-saver. It’s a simple way to turn articles into podcasts, instantly reaching new audiences who prefer to listen. Automated voiceovers for explainer videos, e-learning modules, and corporate presentations are also becoming common, saving creators a ton of time and money.
From the directions we follow to the audiobooks we enjoy, the synthesis of speech has quietly become an indispensable part of modern life.
So, you understand the theory behind how machines learn to talk. That's the hard part. Now for the fun part: making it work for you.
Getting high-quality, human-like voices into your own projects isn't nearly as complicated as it sounds. The quickest and most effective way is to use a Text-to-Speech (TTS) API.
Think of an API (Application Programming Interface) as a direct line to a powerful, pre-trained speech engine. Instead of spending months or years building your own complex neural network, you just send a snippet of text over that line. Seconds later, a ready-to-play audio file comes back. It's a massive shortcut.
Services like Lemonfox.ai provide APIs that do all the heavy lifting. You don’t have to worry about managing huge voice datasets or the insane computational power needed to run these models. You just make a simple request, and their system handles the rest, putting top-tier voice technology right at your fingertips.
Getting started is surprisingly simple and usually boils down to three key steps. It doesn't matter if you're building a web app, a mobile game, or an accessibility tool—the basic idea is always the same. The goal is to get from a line of text to a polished audio file with as little friction as possible.
Here's what that journey typically looks like:
This simple three-part dance strips away almost all the complexity of implementing speech synthesis.
Let's see this in action. The best way to test an API without writing a single line of code is with a tool like cURL, which is a common command-line tool for sending web requests.
Here's an example from the Lemonfox.ai documentation that shows just how clean this process is.
This screenshot shows the whole command in one shot. You can clearly see the API key, the chosen voice ("Adam"), the text to be spoken, and the name of the output file. It’s all neatly bundled into one request.
What’s great about this is how flexible it is. By just changing a couple of those parameters, you could instantly switch from a male to a female voice or change the entire message. It’s a powerful way to plug synthesis of speech into any workflow.
Key Takeaway: The API model hides the immense complexity of neural network-based speech synthesis. A developer can get a high-quality, natural-sounding voice with a single command, letting them focus on building their app instead of wrestling with the underlying AI.
Of course, a single generic voice won't cut it for every situation. The real magic of a modern TTS API is in the customization. You can fine-tune the audio to perfectly match the tone, pace, and personality you need.
These options are what let you create a voice that feels unique to your brand or project. The most common knobs to turn are:
Once you make a successful API request, you get an audio file back. What you do next is entirely up to you and your application. There are two main approaches.
1. Real-Time Streaming
For apps that need to talk now—like a virtual assistant answering a question or a GPS giving turn-by-turn directions—you'll want to stream the audio. The API sends the audio data in small chunks, and your app plays it as it arrives. This keeps latency low and feels seamless to the user, who doesn't have to wait for a full file to download.
2. Saving the File for Later Use
In other cases, it makes more sense to save the audio file. If you're creating voiceovers for a video, generating narration for an e-learning module, or turning articles into podcast-style episodes, you’ll want to save the MP3 or WAV file. This lets you use the audio clip over and over without making new API calls, which saves you time and money. It’s the perfect method for any content creation workflow.
As you start working with AI voices, you'll probably find a few questions coming to mind. This technology is moving so fast that it's completely normal to wonder about what it can do, what it costs, and where the ethical lines are drawn.
Let's clear up some of the most common curiosities people have when they first dive into synthesizing speech. Think of this as your quick-reference guide to the important details.
It's really easy to mix these two up, but they're fundamentally different things. Getting the distinction right is the first step to using this tech responsibly.
Speech Synthesis (TTS) is all about creating a voice from scratch to say whatever you type. The voices are usually pre-made options from a library—think generic but high-quality voices named "Adam" or "Olivia." The whole point is to generate clear, natural-sounding audio for everyday applications.
Voice Cloning, on the other hand, is a much more specialized process. It's about creating an exact digital replica of a specific person's voice. This isn't easy; it requires a lot of audio from that person to train a custom AI model that sounds just like them.
The core difference really comes down to identity. Speech synthesis creates a great-sounding, anonymous voice. Voice cloning aims to perfectly copy a real, identifiable person's voice.
Modern TTS APIs have gone global. We’re a long way from the early days of a single, robotic-sounding English option. The best services today, built on neural networks, can handle dozens—sometimes hundreds—of languages.
And we're not just talking about word-for-word translation. These systems learn from massive amounts of audio from native speakers, so they pick up on the specific rhythms, tones, and accents that make a language sound authentic. This means you can get audio in British English, Australian English, or American English, and each one will sound genuinely distinct.
The price for using a speech synthesis service isn’t a simple flat rate. A few key things determine the final cost, which is almost always based on how many characters or seconds of audio you create.
Here’s a breakdown of what typically moves the needle on pricing:
With the ability to create incredibly realistic voices comes a heavy responsibility. While this tech can be used for amazing things, it also has the potential for misuse. The biggest ethical red flags are tied to deception and misinformation.
Making it sound like someone said something they never did is a serious ethical breach, whether it’s for a harmless prank, a political deepfake, or financial fraud. Any reputable TTS provider will have strict rules against this. The golden rule is to always be transparent when an AI voice is speaking and never, ever impersonate a real person without their explicit permission.
Ready to bring clear, affordable, and ethically-built voices into your next project? With the Lemonfox.ai Text-to-Speech API, you can generate human-like audio effortlessly. Get started with our simple-to-use API and make premium voice technology accessible for any application.