First month for free!
Get started
Published 11/24/2025
So, what exactly is ASR? The acronym stands for Automatic Speech Recognition, and it's the foundational tech that turns spoken language into written text. It’s the magic behind Siri understanding your question, Alexa playing your favorite song, or YouTube generating live captions for a video.
Essentially, ASR acts as a bridge between how humans talk and how computers understand information.
At its core, think of ASR as a highly sophisticated digital interpreter. It takes the sound waves of your voice and meticulously converts them into a format machines can process: text. But this isn't just a simple recording. ASR systems have to grapple with the complexities of human language—deciphering phonetics, understanding syntax, and even figuring out the context of a conversation to get the transcription right.
This technology has been around longer than you might think. Its roots go all the way back to 1952 when Bell Labs unveiled "Audrey," a system that could recognize single-spoken digits. It was clunky and slow, but it was the first step on a long road to the powerful, instant voice tools we have today.
ASR systems work by dissecting audio signals into tiny, recognizable pieces. This process is what allows us to use our voice as a natural way to interact with the digital world.
This single capability—turning speech into usable data—has paved the way for countless innovations. Without ASR, we wouldn't have some of the most common features we now take for granted:
To get a better sense of the nuts and bolts of how this works, you can find more information about voice to text AI technology.
To quickly review these core ideas, here’s a simple breakdown of the key concepts.
| Concept | Brief Explanation |
|---|---|
| ASR | Automatic Speech Recognition; the technology that converts spoken words into text. |
| Core Function | Acts as a digital interpreter between human speech and machine-readable text. |
| Key Components | Involves analyzing sound waves, phonetics, grammar, and context. |
| First System | "Audrey" was created by Bell Labs in 1952 and recognized spoken digits. |
| Modern Examples | Voice assistants, live video captioning, and in-car voice commands. |
This table provides a snapshot, but understanding these elements is the first step toward appreciating just how much ASR shapes our daily interactions with technology.
So, how does a machine actually listen? Think about how your own brain works when you hear someone talking in a noisy room. You instinctively filter out the background chatter and focus on the words being spoken. An ASR system does something very similar, but through a series of precise, lightning-fast steps.
The entire process kicks off the second a sound wave hits the microphone. The system’s first job is to clean up this raw audio. This is called signal processing, and its goal is to isolate the important stuff—the human voice—from any distracting background noise. Getting this step right is absolutely crucial; it’s like a sound engineer polishing a recording before it goes any further.
The diagram below gives you a bird's-eye view of this journey from spoken word to written text.
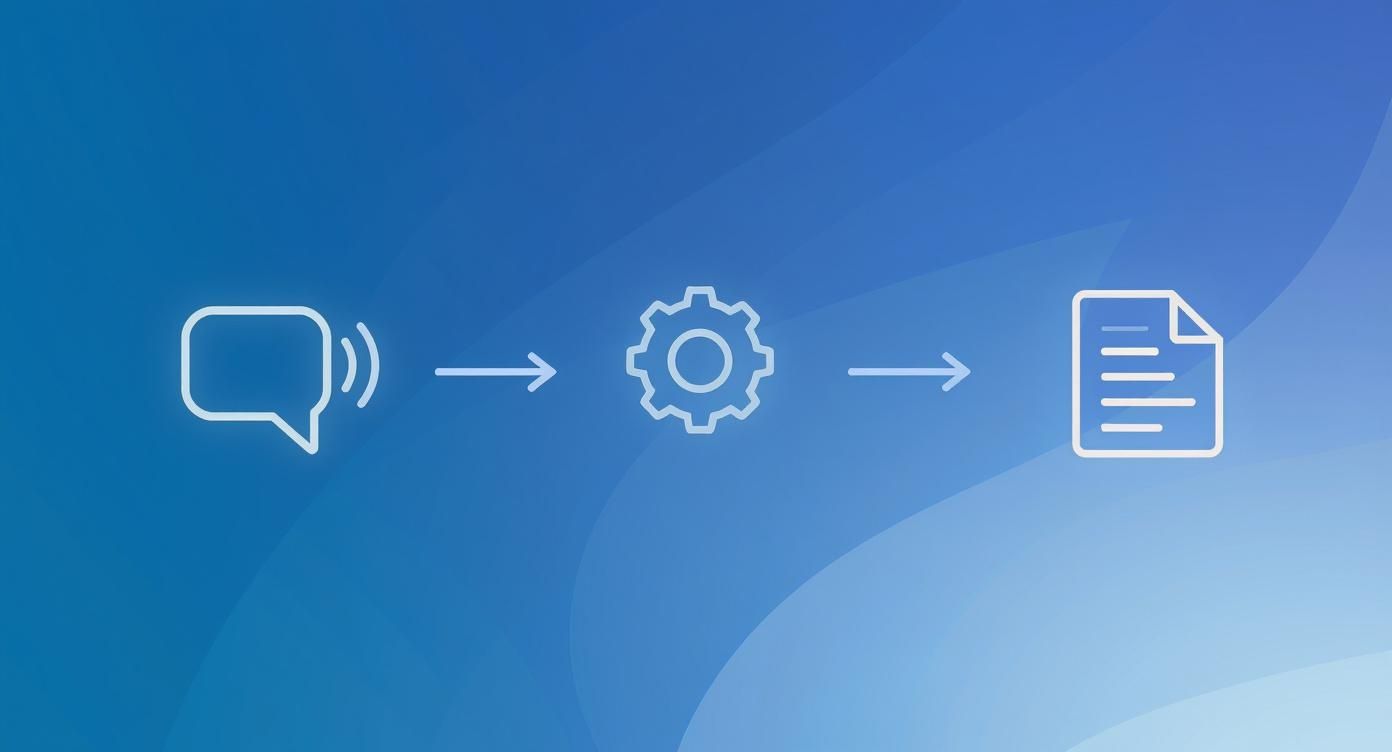
As you can see, raw speech goes in, the ASR engine works its magic, and structured text comes out the other side.
To pull off this feat, Automatic Speech Recognition relies on a few key components working in harmony. It's really a sophisticated partnership between analyzing sound and predicting language.
At its heart, an ASR system combines an acoustic model, a language model, and a decoding algorithm. The acoustic model is the first piece of the puzzle. It takes that clean audio signal and dissects it into the smallest units of sound, called phonemes. For instance, the word "chat" would be broken down into three distinct phonemes: /ch/, /a/, and /t/. For a more technical dive, you can explore this overview of how speech recognition models work.
But identifying sounds isn't enough. That's where the language model comes in. This component acts like a grammar and context expert, looking at the string of phonemes and figuring out the most likely words and phrases based on trillions of examples of how people actually talk.
Think of it like this: The acoustic model hears the raw sounds, but the language model provides the street smarts. It’s what helps the system understand that you probably said "recognize speech," not "wreck a nice beach," even though they can sound surprisingly similar.
By blending the "what it hears" from the acoustic model with the "what makes sense" from the language model, the ASR system can piece together an accurate and coherent transcript.
So, if not all Automatic Speech Recognition systems are created equal, how do we tell the good from the great? The go-to industry benchmark for this is a metric called Word Error Rate (WER).
Think of it like a golf score for transcription—the lower the number, the better the system performed. It’s a straightforward, mathematical way to grade a machine-generated transcript by comparing it to a perfect, human-checked version.
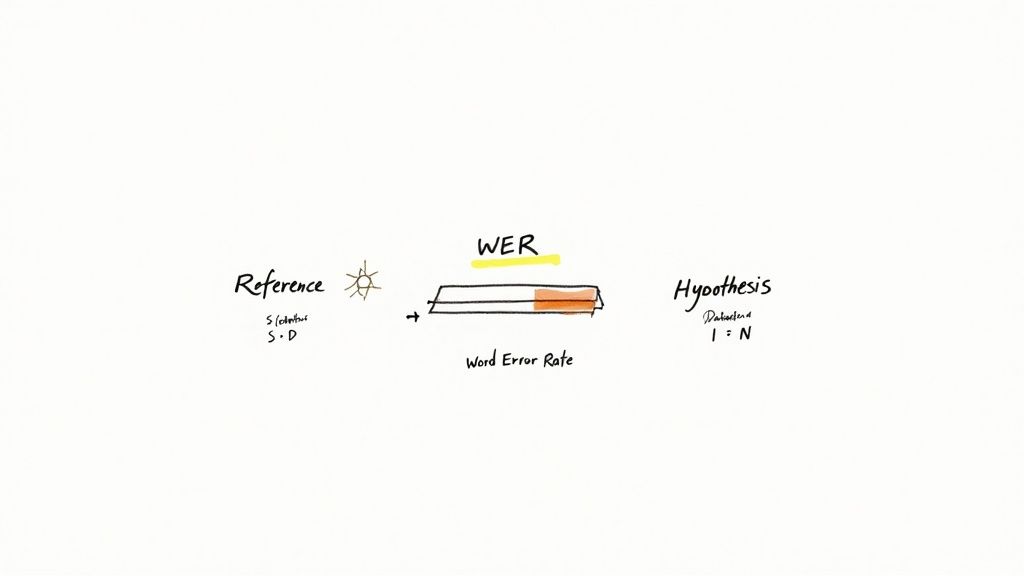
The WER calculation is pretty simple at its core. It tallies up three kinds of mistakes and then divides that total by the number of words in the original, correct transcript.
The errors it looks for are:
A system with a 20% WER would produce a transcript with a lot of obvious mistakes that would need a fair bit of manual cleanup. On the other hand, a transcript with a 5% WER is incredibly accurate and would only need a few light touch-ups.
Top-tier ASR models today can hit a WER as low as 2-5% under ideal conditions. That's a massive improvement from early systems that often had error rates north of 30%.
Word Error Rate is the main yardstick, but it's not the whole story. Other factors like latency (how fast the text shows up) and robustness (how well it handles background noise or different accents) are just as important for a genuinely good experience.
If you're curious to learn more about performance metrics and see just how accurate AI transcription truly is, there's a lot more to explore.
You probably use Automatic Speech Recognition technology every single day, often without even thinking about it. ASR has quietly become the invisible engine behind many of the modern conveniences we now rely on, turning our spoken words into actions.
Think about it. When you ask Siri for the weather, tell Alexa to play your favorite song, or use Google Assistant to set a timer while cooking, you're using ASR. It’s the same magic that lets you dictate a text message while driving or ask your car’s navigation for the quickest route home.
But ASR’s influence doesn't stop with our personal gadgets. It’s making a massive impact in professional fields, driving huge gains in efficiency and opening up new possibilities.
The real power of ASR becomes clear when you look at how it’s being applied across different industries. It’s not just about convenience; it’s about solving real-world problems.
It's easy to see the pattern here. In each case, ASR is tackling a specific, practical challenge. It's about making our interactions with technology feel more human while also making professionals more effective at their jobs.
Take a look at how a few different sectors are putting ASR to work.
| Industry | Primary Application | Key Benefit |
|---|---|---|
| Healthcare | Medical dictation and transcription | Reduces administrative burden on clinicians |
| Finance | Voice banking and fraud detection | Improves security and customer convenience |
| Retail | Voice search for e-commerce | Creates a faster, more natural shopping experience |
| Automotive | In-car voice commands for navigation & media | Enhances driver safety by enabling hands-free control |
| Education | Lecture transcription and language learning tools | Increases accessibility and provides new study aids |
As you can see, the applications are incredibly diverse. By translating the human voice into useful data, ASR is consistently bridging the gap between how we communicate and how our devices understand us.
https://www.youtube.com/embed/1oe8mTeoFtU
The world of Automatic Speech Recognition is moving incredibly fast, mostly thanks to big leaps in deep learning. We're on a path toward ASR systems that can achieve almost human-like accuracy, not just in a quiet room but out in the real world with all its diverse languages, dialects, and speaking styles.
This progress is making technology feel more conversational and natural. Think about systems that can follow the subtle twists and turns of a conversation, learn your unique way of speaking on the fly, and work perfectly even in a noisy, chaotic environment. The aim is to make interacting with voice so smooth that you forget you're even talking to a machine.
Even with all this exciting progress, some tough challenges are still on the table. The whole industry is rolling up its sleeves to crack a few complex problems that stand in the way of a truly perfect ASR experience for everyone.
Here are some of the biggest areas getting attention:
The ultimate goal isn't just to turn spoken words into text. It's to build ASR systems that grasp context and nuance with the same intuition a human listener would. This means we have to solve some deep-rooted challenges in both the data we use and how we design the models.
Figuring out these issues is the key to unlocking the next generation of voice-powered apps. The entire field is pushing for better accuracy, greater inclusivity, and more resilient systems, bringing us closer to a future where voice technology is truly dependable for anyone, anywhere.
You've got the basics of what ASR is and how the magic happens. But as this technology weaves itself more deeply into our daily routines, it's natural to have a few more questions. Let's clear up some of the common ones.
The sheer scale of this integration is pretty staggering. The global ASR market is on a massive growth spurt, with projections hitting $73 billion by 2031 and even $83 billion by 2032. This isn't just a niche tech; it's becoming a fundamental piece of our digital infrastructure, thanks to the broader push for AI everywhere. If you're curious about how we got here, it's worth taking a look at ASR's history and growth.
People often use these terms interchangeably, and for everyday conversation, that's usually fine. But technically, there’s a small but meaningful distinction.
Automatic Speech Recognition (ASR) is the broad scientific field. It’s the entire engine room of research, complex algorithms, and acoustic models that make it possible to understand spoken language.
Speech-to-Text (STT), on the other hand, is the specific application that comes out of that science. It’s the actual tool or feature you interact with to get a transcription.
A simple way to think about it is that ASR is the meticulously engineered engine, while STT is the car that engine powers. One is the core technology, the other is the product you drive.
So, whenever you use a transcription app, you're using an STT service that runs on ASR technology.
This is a great question because ASR and Natural Language Processing (NLP) are like two sides of the same coin. They are distinct AI fields, but they work together beautifully, usually one after the other.
Essentially, ASR hears, while NLP understands. An ASR system can turn the sound of "What's the weather like?" into those exact words, but it's an NLP model that grasps you're asking for a forecast.
Even with all its advancements, ASR still has some big hurdles. One of the classic, most persistent ones is the "cocktail party problem." Imagine trying to listen to one person talk in a loud, crowded room—that’s exactly the challenge. Isolating a single voice from a mess of background noise and overlapping chatter is incredibly difficult for a machine.
Beyond that, a couple of other major challenges keep developers busy:
Solving these problems is the key to making ASR truly seamless and dependable for everyone, no matter the situation.
Ready to put powerful transcription to work? Lemonfox.ai offers a developer-friendly Speech-to-Text API that delivers high accuracy in over 100 languages for less than $0.17 per hour. Start your free trial today and get 30 hours of transcription at Lemonfox.ai.