First month for free!
Get started
Published 12/19/2025
Speech recognition is the magic that lets our devices understand what we're saying. At its core, it’s a technology that translates our spoken words into text that a computer can read and act on. It's often called Automatic Speech Recognition (ASR), and it's the engine behind everything from your smart speaker to the voice commands in your car.
Think of it like having a personal translator for your computer. If you were trying to communicate with someone who didn't speak your language, you'd need an interpreter to bridge that gap. ASR does the same thing, but for machines. It listens to the sound waves of your voice and carefully converts them into digital text.
This simple but powerful process is what allows us to talk to our technology instead of just typing at it. We can ask our phones for directions, dictate an email on the go, or have an entire meeting transcribed automatically. ASR is the fundamental building block that makes these kinds of hands-free, natural interactions a reality.
Speech recognition didn't just appear overnight. Its journey from a clunky lab experiment to a tool we use daily has been a long one. The earliest systems were incredibly limited—they could barely recognize a handful of words spoken by one specific person. What really changed the game was the explosion of big data and the power of cloud computing, which gave researchers the ingredients to build much smarter, more accurate models.
For example, the giants in the field built their success on server-side models trained on absolutely massive datasets. Early versions of Google Voice Search were trained on text collections containing a staggering 230 billion words. This sheer scale is what helped the technology finally get good enough to understand the messy, unpredictable way real people talk. You can dive deeper into the history of speech recognition to see just how far it's come.
To give you a clearer picture of this evolution, here's a look at some of the major turning points.
This table highlights pivotal moments in the evolution of speech recognition, showing the progression from simple digit recognition to complex, large-vocabulary systems.
| Era | Key Development | Achieved Capability |
|---|---|---|
| 1950s | Bell Labs' "Audrey" system | Recognized spoken digits (0-9) from a single speaker. |
| 1960s | IBM's "Shoebox" machine | Understood 16 words and digits. |
| 1970s | DARPA's "Harpy" system | Could understand over 1,000 words, the vocabulary of a 3-year-old. |
| 1980s | Hidden Markov Models (HMMs) | Introduced a statistical approach, allowing systems to predict word sequences. |
| 2000s | Rise of Big Data | Massive datasets from companies like Google enabled much larger vocabularies. |
| 2010s | Deep Learning & Neural Networks | Accuracy rates surged, making speech recognition a mainstream consumer technology. |
As you can see, the leap from recognizing a few numbers to understanding conversational language was driven by decades of innovation and a fundamental shift in approach.
Speech recognition isn't about a machine truly "understanding" language like a person does. It's all about sophisticated pattern matching—finding the most likely string of words that matches the sound data it receives.
Today, this technology is woven so deeply into our lives that we often take it for granted. It's become an essential part of:
This wide-scale adoption shows just how useful it is, turning the simple act of speaking into a powerful and direct way to command our digital world.
Ever wondered what happens in the milliseconds between you speaking a command and your smart assistant getting it right? It's not magic, but it's close. Think of it as a highly skilled digital interpreter who doesn't actually speak a language, but instead deciphers sound waves, patterns, and probabilities at lightning speed.
The whole journey from a spoken word to digital text follows a clear, predictable pipeline. This process is the bridge between our analog world of speech and the digital realm of computers.
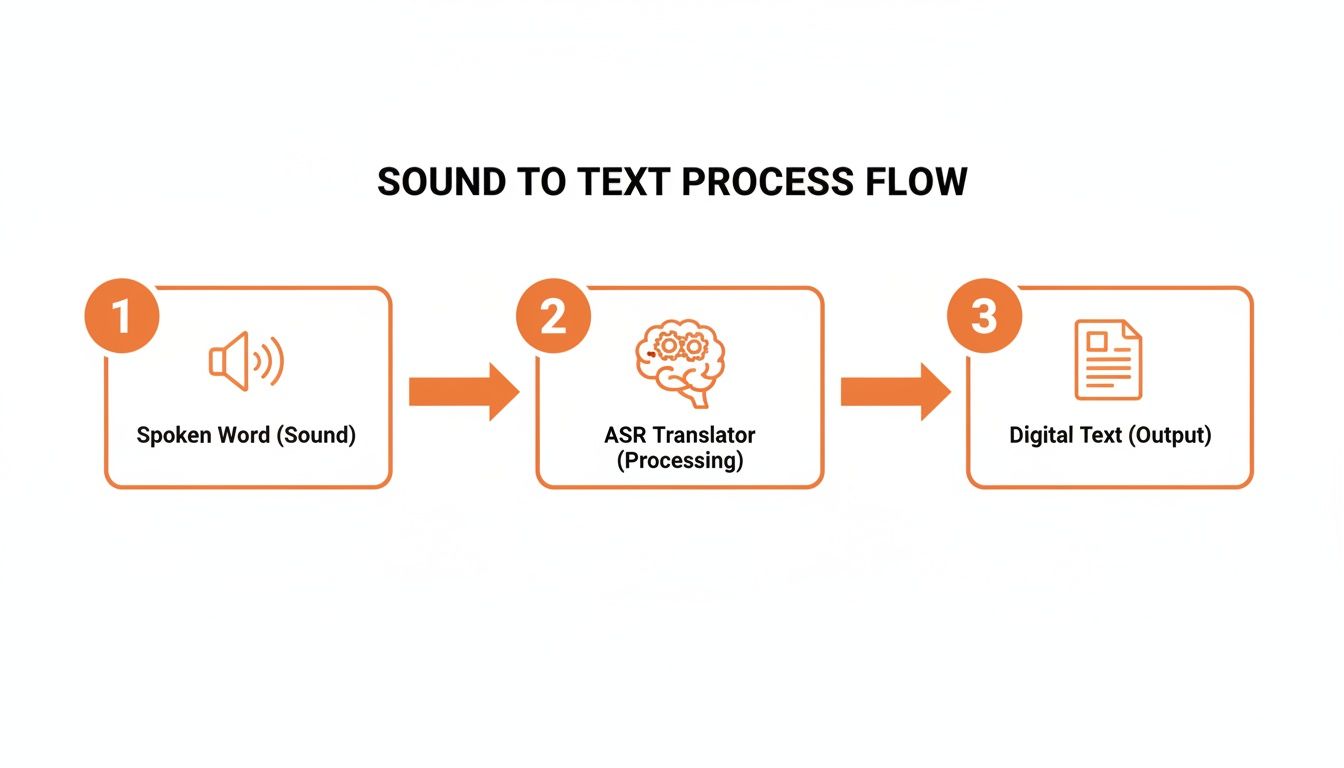
Let's break down exactly what's happening under the hood.
It all starts with a sound wave. When you speak, you create vibrations in the air that a microphone in your phone or speaker picks up and converts into a digital audio signal.
But let's be real—the world is noisy. Your voice is rarely the only thing the microphone hears. It also captures the hum of an air conditioner, distant traffic, or a dog barking next door. Before the machine can even begin to understand you, it has to perform signal processing to clean up that messy audio.
Think of it like a photographer adjusting the focus. The system sharpens your voice and blurs out the distracting background noise. A clean signal is everything; without it, the next steps are nearly impossible.
With a clean audio signal in hand, the system gets to work dissecting it into the smallest units of sound that differentiate one word from another. These are called phonemes. For example, the word "chat" is made up of three distinct phonemes: "ch," "a," and "t."
This is where the acoustic model takes center stage. This model is trained on massive libraries of labeled audio, so it has learned to map specific parts of a sound wave to their corresponding phonemes. It's like a phonetic detective, meticulously identifying the fundamental building blocks of the words you just spoke.
The acoustic model’s job is to answer one question: "Given this tiny slice of audio, which sound unit is it most likely to be?" It translates raw sound data into the core sounds of a language.
The accuracy here is absolutely critical. If the acoustic model mistakes a "p" for a "b," the word "pat" could easily become "bat," completely changing the meaning of your sentence.
Okay, so we have a string of phonemes. Now what? You can't just slap them together; you need context. This is where the language model comes in.
The language model is essentially a probability engine for words. Having been trained on colossal amounts of text from books, articles, and websites, it knows which word combinations are common and which are nonsensical. It understands that you're far more likely to say "how are you" than "how are shoe."
Using the phoneme sequence from the acoustic model, the language model calculates the most probable words and sentences. It's making a highly educated guess based on context.
Here's a simple way to think about how it chooses between two phrases that sound almost identical:
If you want to see this kind of advanced processing in action, check out how to create chapters in YouTube AI, a perfect example of machines learning to interpret spoken content to create structure.
This probabilistic approach, driven by deep learning and neural networks, is what gives modern ASR systems such remarkable accuracy. The final text you see is the system’s best guess—the most likely combination of sounds and word patterns. It shows how machines have truly learned not just to hear, but to listen.
You wouldn’t expect a single tool to fix every problem in a workshop, and the same is true for speech recognition. ASR technology isn't a one-size-fits-all solution. Instead, different systems are built for different jobs, each with its own strengths and weaknesses. Figuring out these differences is the key to picking the right tool for the task at hand.
The most basic way to slice it is by who the system is designed to listen to: a single, specific person, or absolutely anyone. This one distinction changes everything about how the technology is built and where it shines.
One of the very first systems, a 1952 Bell Labs project named “Audrey,” could recognize digits spoken by a single person with about 90% accuracy. That was a huge deal back then, but it also showed just how limited the technology was. By the 1970s, DARPA-funded research started pushing the envelope, leading to systems like Carnegie Mellon's Harpy, which could understand over 1,000 words. You can see how these early, highly specific models set the stage for the tech we use today by exploring the evolution of speech recognition.
Think of a speaker-dependent system as being like a dog trained to only listen to its owner. It’s been tuned to the specific pitch, accent, and quirks of one person’s voice. This intense, personalized training allows it to achieve remarkable accuracy for that single user.
Have you ever set up a new smart device by reading a bunch of phrases out loud? You were training a speaker-dependent model. That process creates a unique voice profile that helps the system lock onto your way of speaking.
On the other hand, a speaker-independent system is like the veteran barista at a bustling café who can make sense of orders from hundreds of different people, no matter their accent or how fast they talk. These systems are the backbone of modern voice tech, powering everything from Siri and Alexa to the automated menus you get when you call your bank.
These models are trained on massive audio datasets—we’re talking thousands of hours of speech from a huge variety of people with different ages, genders, and regional accents. This diverse training makes them flexible enough to understand most people right out of the box, with no individual setup needed.
The whole point of a speaker-independent system is to be a generalist. The goal is to build a model so robust that it can accurately transcribe speech from someone it has never encountered before.
Let’s clear up one common point of confusion: speech recognition is not the same as speaker recognition. They both analyze the human voice, but they're asking two completely different questions.
| Technology | The Question It Answers | What It Actually Does | A Real-World Example |
|---|---|---|---|
| Speech Recognition (ASR) | "What was said?" | Converts spoken words into written text. | Using voice-to-text to send a message or getting a transcript of a meeting. |
| Speaker Recognition (Voice ID) | "Who is speaking?" | Identifies a person by their unique vocal fingerprint. | Unlocking your phone with your voice or verifying your identity with your bank's security system. |
Put simply, ASR cares about the content of what you're saying, while speaker recognition cares about the identity of who is saying it. Many advanced ASR systems today actually incorporate speaker recognition to figure out who said what in a conversation. This feature is called diarization, and it's what creates those transcripts where each person's speech is labeled (e.g., "Speaker 1," "Speaker 2").
ASR technology has come a long way, moving from the rigid, rule-based systems of the past to the incredibly flexible deep neural networks we have today. This progress means that whether you need a system that understands one person perfectly or millions of people pretty well, there's a solution out there. Understanding this variety is the first step to finding the one that fits your needs.
It's easy to think of speech recognition as some futuristic concept, but the truth is, it's already woven into the fabric of our daily lives. This isn't just a cool party trick for your smartphone anymore; it's a powerful and practical tool that quietly makes things faster, safer, and a whole lot more convenient. You probably use it multiple times a day without a second thought.
The shift happened because voice commands and automated transcription solve real-world problems. This practicality is why speech recognition exploded into a multi-billion-dollar industry in the 2010s. From the voice assistant in your kitchen to the dictation software in your doctor's office, speech-enabled products have reached hundreds of millions of people. For a deeper dive, you can read more about the evolution of voice recognition technology.

Here are a few of the most common ways this tech shows up.
This is the one we all know. When you ask Siri, Alexa, or Google Assistant about the weather, you're using a sophisticated, speaker-independent ASR system. It’s a perfect illustration of the whole ASR pipeline in action.
Your device captures the sound of your voice, zips it off to a server in the cloud for processing, and gets the transcribed text back in a blink. The assistant then understands your request, finds the answer, and speaks it back to you. It's the ultimate solution for quick, hands-free information when you're cooking, driving, or just can't be bothered to type.
In a hospital, every second counts. Doctors and nurses have historically spent a huge chunk of their time on administrative work, especially updating patient records. This is where speech recognition has been a game-changer.
Instead of typing out long, detailed notes after an examination, a doctor can simply dictate them. A specialized medical ASR system, trained on a massive dictionary of complex medical terms, transcribes their words directly into the electronic health record (EHR).
This isn’t just about saving time—it’s about improving patient care. By freeing up clinicians from the keyboard, this technology lets them spend more time focused on the person in front of them, which can lead to better outcomes and less burnout.
We all know distracted driving is a huge risk. Speech recognition provides a simple, effective way to keep your hands on the wheel and your eyes on the road.
Modern cars come equipped with embedded ASR systems that let you manage navigation, make calls, or change the temperature, all with your voice. When you say, “Call Mom” or “Find the nearest gas station,” you’re using an ASR model specifically built to work in the noisy environment of a moving car. It's a clear-cut case of technology making our roads safer.
Ever called a company and heard an automated voice say, "In a few words, tell me why you're calling"? That’s speech recognition working behind the scenes in a call center.
These systems use natural language understanding to figure out what you need and get you to the right person, saving you from the headache of endless button-mashing menus. For businesses, this is a massive win. ASR handles the simple, repetitive questions, which frees up human agents to tackle more complex problems.
The applications for speech recognition are incredibly diverse and continue to expand. Here's a quick look at how different industries put this technology to work.
A comparative look at how different sectors leverage ASR technology to solve specific challenges and improve efficiency.
| Industry | Primary Use Case | Key Benefit |
|---|---|---|
| Healthcare | Medical Dictation & EHR | Reduces administrative burden, improves accuracy, and allows more patient-facing time. |
| Automotive | In-Car Voice Commands | Enhances driver safety by enabling hands-free control of navigation, media, and calls. |
| Customer Service | IVR & Call Routing | Improves efficiency by automating initial queries and directing customers to the right agent. |
| Finance | Voice Biometrics & Trading | Secures accounts through voice identification and enables faster, hands-free trade execution. |
| Media & Entertainment | Closed Captioning & Subtitling | Automates the creation of accessible content for broadcast and streaming platforms, saving time and money. |
| Education | Lecture Transcription & Language Learning | Provides searchable transcripts for students and offers real-time pronunciation feedback. |
As these examples show, ASR is far more than a novelty; it's a foundational technology that's deeply integrated into the tools and services we rely on every day.
As impressive as modern speech recognition has become, it's still far from perfect. We've all had that moment where a voice assistant mangles a simple request, turning "call mom" into "tall Tom." These mistakes happen because the real world is messy, noisy, and wonderfully unpredictable.
Understanding why these errors pop up is key for anyone using or building with ASR. It’s not about finding flaws; it’s about setting realistic expectations and knowing where the technology still has room to grow. At their core, these systems are just incredibly sophisticated pattern-matchers, and when the audio they hear doesn't fit the clean patterns they learned from, accuracy takes a nosedive.
By far, the biggest enemy of accurate speech recognition is a poor audio signal. Just think about trying to hold a conversation in a loud, crowded restaurant. The clatter of forks, the buzz of other conversations, and the background music all compete for your attention.
For an ASR system, that kind of environment is a nightmare. Background noise can easily warp the sound waves of a person's voice, making it nearly impossible for the acoustic model to figure out what’s being said.
Even if you have crystal-clear audio, the way people actually talk is a massive challenge in itself. Human speech is incredibly diverse and rarely follows neat, predictable rules. This natural variability is a constant hurdle for machines to overcome.
For instance, ASR systems trained primarily on standard accents can really struggle when they encounter a voice that doesn't fit the mold of their training data.
Even the most advanced ASR models can have a higher word error rate when processing speech from non-native speakers or those with strong regional accents. It’s not a flaw in the speaker; it’s a gap in the model’s training data.
This problem shows up in other common speaking patterns, too:
The good news is that these challenges aren't deal-breakers. The accuracy of any what is a speech recognition system can be dramatically improved by tackling these common issues head-on. Simple steps like using high-quality microphones, minimizing background noise, and choosing models trained on diverse voice data can make a huge difference.
For more specific needs, using a service that allows you to add a custom vocabulary or fine-tune the model can be a game-changer. Understanding these limitations isn't about being critical of the tech; it's the first step toward building applications that are not just powerful but truly reliable out in the real world.
Choosing a speech recognition tool isn't as simple as picking the one with the highest accuracy score on a marketing page. The "best" tool is the one that fits your specific project, budget, and technical setup. It’s all about finding that sweet spot where performance, cost, and features align perfectly with what you’re trying to build.
Think of it like choosing a vehicle. A Formula 1 car is incredibly fast, but you wouldn't use it to move furniture. Likewise, a massive cloud-based ASR model is overkill for a simple voice command on a mobile app, and a lightweight offline model would buckle under the pressure of transcribing a multi-speaker conference call. The goal is always to match the tool to the job.
Before you even look at a pricing page, it’s worth taking a moment to define exactly what you need. Getting clear on your priorities will help you slice through the marketing hype and focus on what actually matters.
As you start comparing different services, you'll notice a few common trade-offs. Understanding these will help you make a much smarter decision.
Choosing a speech recognition provider is a strategic decision. Look for partners who are upfront about their pricing and don't try to lock you into confusing, long-term contracts. You want a tool that grows with you, not one that springs surprise costs on you down the road.
This is where modern solutions like Lemonfox.ai really shine. The models are built to balance speed and accuracy, hitting a great middle ground for most common use cases. Plus, the straightforward pricing—less than $0.17 per hour—makes it one of the most accessible and affordable professional-grade options out there. And when choosing a tool, many users now expect advanced functionalities like text-based editing features to make their post-transcription work much easier.
Don't be afraid to dig in and ask some tough questions. A provider's answers will tell you everything you need to know about whether they're the right fit.
In the end, nothing beats a real-world test. Every provider offers a free trial or some credits to get started. Use them. Run your own audio files through each service and see the results for yourself. That hands-on comparison is the only way to know for sure which tool truly delivers.
As speech recognition weaves itself more deeply into our daily lives, a few key questions tend to pop up again and again. Getting to grips with the specifics helps demystify not only how this technology works today, but also where it's heading. Let's tackle some of the most common ones.
This is a classic point of confusion, but the distinction is actually pretty straightforward. Here’s the simplest way to think about it: speech recognition cares about what you say, while voice recognition cares about who is saying it.
They answer two totally different questions.
Yes, it absolutely can. Whether you need an online or offline system really just depends on the job you're trying to do. Cloud-based ASR systems tap into massive data centers to deliver incredibly high accuracy for complex tasks, but they need a stable internet connection to function.
On-device models, however, run directly on your phone or laptop. This approach offers huge advantages for privacy and speed because your data never has to leave your device. While they might not match the raw power of a giant cloud model, they're perfect for situations where internet is spotty or keeping data secure is the top priority.
The future of ASR isn’t just about making cloud models bigger; it’s also about making on-device models smarter and more efficient, bringing powerful processing directly to the edge.
The road ahead for speech recognition is all about making our interactions with technology feel less robotic and more human. Researchers are working on systems that go way beyond just turning words into text. Imagine a machine that can pick up on emotional tone, understand sarcasm, or grasp the unspoken context of a conversation.
Language accessibility is another huge frontier. The goal is to create truly universal systems that can switch between languages on the fly or even transcribe languages that have very little training data available. This isn't just a technical challenge—it's about breaking down communication barriers and making technology useful for everyone, everywhere. Ultimately, the aim is to make talking to a machine feel as natural as talking to another person.
Ready to integrate fast, accurate, and affordable transcription into your application? With Lemonfox.ai, you can transcribe audio for less than $0.17 per hour, with support for over 100 languages and a privacy-first approach. Start building with our simple-to-use Speech-to-Text API and get your first 30 hours free.