First month for free!
Get started
Published 9/25/2025
Ever dictated a text message or asked your smart speaker for the weather? You've already used Automatic Speech Recognition, or ASR. It's the technology working behind the scenes, turning your spoken words into text that a computer can understand.
Think of it as a bridge connecting how we naturally communicate—with our voices—to the digital world of data and commands.

ASR is the engine that powers everything from the live captions on a video call to the voice commands in your car. It’s not just a neat trick for convenience; it's a powerful tool that makes technology more accessible and allows us to process massive amounts of audio information instantly.
At its heart, ASR gives machines the ability to listen. It enables them to comprehend human speech and act on it, creating a much more natural and efficient way for us to interact with the devices around us.
The main job of any ASR system is to answer one simple question: What was just said?
Getting to that answer is incredibly complex. The system has to take raw, analog sound waves from a microphone and meticulously convert them into digital text. This involves breaking our speech down into its smallest sound units (called phonemes), piecing them together into words, and then arranging those words into logical sentences.
It's a tough job because human speech is messy. A good ASR system has to contend with:
ASR essentially gives our digital world a pair of ears. It takes the unstructured, often chaotic flow of human speech and translates it into a clear, organized format that software can finally work with.
To make this process easier to visualize, let's break down the core components of ASR technology.
The following table outlines the key steps an ASR system takes to convert speech into text, from initial sound capture to the final, readable output.
| Component | Function | Real-World Example |
|---|---|---|
| Acoustic Model | Maps raw audio signals to the smallest units of sound (phonemes). | Distinguishing the "c" sound in "cat" from the "b" sound in "bat" amidst background noise. |
| Lexicon (Dictionary) | Contains a vast vocabulary of words and their corresponding phoneme pronunciations. | Knowing that the phonemes "h-e-l-o" form the word "hello." |
| Language Model | Predicts the probability of a word sequence to form coherent sentences. | Determining that "how are you today" is more likely than "how are shoe today." |
| Decoder | Combines inputs from all models to produce the most probable text transcription. | Assembling the final, accurate sentence: "Please schedule a meeting for 3 PM tomorrow." |
These components work together in a fraction of a second, enabling the near-instantaneous transcription we experience in modern applications.
The need for reliable ASR has skyrocketed, pulling it from a niche academic field into the mainstream. The market numbers tell the story loud and clear. Valued at roughly USD 9.1 billion in 2024, the global ASR market is on track to hit an estimated USD 30.5 billion by 2033.
This massive growth is fueled by breakthroughs in AI and machine learning, which have made ASR systems faster and far more accurate than ever before. Understanding the basics of machine learning fundamentals can give you a much deeper appreciation for the complex calculations happening under the hood.
As these models get even smarter, voice is quickly becoming one of the most important ways we interact with technology, cementing ASR's role for years to come.
Automatic Speech Recognition can feel like magic, but under the hood, it’s a systematic process that translates the vibrations of your voice into clean, readable text. It's like a digital detective piecing together clues—starting with a raw sound, filtering out the noise, identifying individual sounds, and finally assembling them into a coherent message.
The whole journey starts the moment you speak. Your voice creates analog sound waves, and a microphone in your phone or headset captures them. This is immediately converted into a digital audio signal, which is the only format a computer can really work with. This first step is the critical bridge from the physical world to the digital one.
But that raw digital audio is messy. It's filled with everything but your voice—the hum of a fan, a passing car, or background chatter. The ASR system's first job is to clean this up. Using signal processing techniques, it isolates your speech and quiets the interference, making sure the system focuses only on what matters: your words.
This infographic breaks down the basic three-step process, from the initial audio input to the final text output.
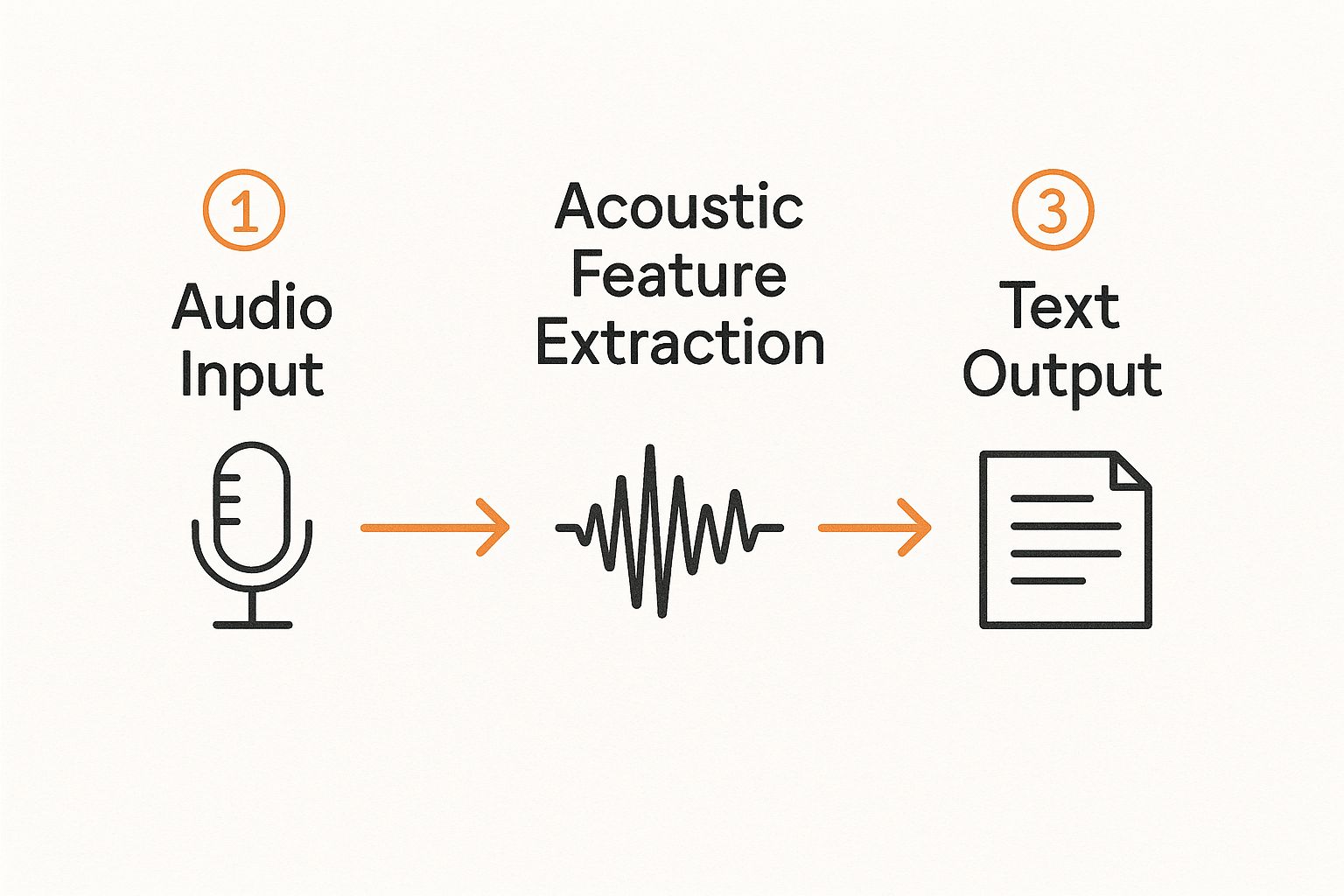
As you can see, it's a logical flow. Each stage refines the data, preparing it for the next phase of analysis.
Once the audio is clean, it's handed off to the Acoustic Model. You can think of this part as a highly trained phonetician. Its entire job is to listen to tiny segments of the audio—just fractions of a second—and match them to the smallest units of sound in a language, called phonemes.
For example, the word "cat" is made up of three phonemes: "k," "æ," and "t." The Acoustic Model analyzes the audio waveform and calculates the probability that a specific sound corresponds to one of these phonemes. This happens thousands of times a second, generating a running sequence of the most likely sounds.
This model is the heart of ASR, but it's not the whole story. On its own, it would just produce a jumbled string of sounds, not actual words. It might hear the phonemes for "eye scream," but it has no idea how to assemble them into the logical phrase "ice cream." That’s where the next component comes in.
After the Acoustic Model identifies all the possible sounds, the Language Model takes the baton. Imagine this model as a seasoned editor who has a deep understanding of grammar, syntax, and context. Its purpose is to take the sequence of phonemes and arrange them into the most probable words and sentences.
How does it do this? By analyzing massive datasets of text to learn which word combinations are common and which are statistical longshots. For example, the Language Model knows that the phrase "nice to meet you" is far more likely to appear than "nice to meat ewe," even if the phonemes sound identical to the Acoustic Model.
This is what gives the system its contextual intelligence. The Language Model helps the ASR system make smart choices between homophones (like "to," "too," and "two") based entirely on the surrounding words.
In essence, the Acoustic Model asks, "What sounds did I hear?" while the Language Model asks, "Based on those sounds, what words make the most sense in this order?" The collaboration between these two is what produces accurate, readable transcriptions.
The final step is decoding, where the ASR system combines the outputs from both the Acoustic and Language Models to generate the single most likely transcription. This process is all about weighing the probabilities from both models to find the best possible path.
It’s a balancing act:
Together, they work to solve the puzzle of what was actually said. The decoder sifts through all the possible word sequences and picks the one with the highest combined probability score. This sophisticated teamwork is what allows modern ASR systems, like the Lemonfox.ai API, to deliver text output that is not only fast but also remarkably accurate, even in noisy or challenging audio environments.
Talking to our devices feels like a very modern convenience, but the journey of Automatic Speech Recognition actually started long before the first smartphone. The whole idea of a machine that could understand us was once purely science fiction. It’s taken over seven decades for that dream to evolve from a lab curiosity into something woven into the fabric of our daily lives.
This transformation wasn’t a sudden leap forward. It was a slow, steady climb built on decades of research, plenty of setbacks, and a few game-changing breakthroughs. The story of ASR is a perfect example of how persistent innovation can turn a far-fetched idea into a practical, everyday tool.
The very first baby steps in ASR were taken all the way back in the 1950s. In 1952, Bell Labs unveiled "Audrey," a machine that could recognize spoken digits from a single speaker. While it was an incredible feat for its time, Audrey was a room-sized behemoth that could barely handle the numbers zero through nine. It was a groundbreaking proof of concept, but a long, long way from the seamless experience we have today.
Progress continued slowly through the 60s and 70s. Researchers managed to build systems that could recognize a small vocabulary of words, but there was a big catch: these early systems were speaker-dependent. This meant they had to be painstakingly trained on one person's voice and struggled immensely with continuous speech or different accents, which severely limited their real-world use.
The 1980s and 90s brought a huge shift in thinking with the rise of statistical modeling. Researchers started using a technique called Hidden Markov Models (HMMs), which offered a completely new way to tackle the problem. Instead of trying to match rigid, pre-defined patterns, HMMs used probabilities to figure out the most likely sequence of words from any given audio signal.
This statistical approach was a game-changer. It allowed ASR systems to become far more flexible and handle a much wider range of voices and vocabularies. For the first time, speaker-independent systems started to look like a real possibility. HMMs laid the foundational groundwork that would dominate the field for nearly two decades, powering the first generation of dictation software and call center routing systems.
But even with the leap forward that HMMs provided, they eventually hit a performance ceiling. The sheer complexity and nuance of human language—with its endless variations in tone, speed, and accent—posed a challenge these models couldn't quite overcome on their own.
The 2010s kicked off a whole new era for ASR, all thanks to the explosion of deep learning and neural networks. This new approach was designed to mimic the human brain's structure, allowing models to learn from enormous datasets and pick up on incredibly complex patterns in speech that were previously out of reach.
This was the moment everything changed. Today's modern ASR systems can achieve word error rates as low as 5%, a massive improvement from rates that often topped 20% just a decade ago. This leap in accuracy is what finally made voice assistants reliable enough for mainstream products, triggering a surge in adoption. By the early 2020s, voice assistant usage had ballooned to over 4 billion devices worldwide. You can explore the data behind the global rise of speech recognition on Statista.
So, the next time you ask your phone for directions, remember you're interacting with a technology that has a long and fascinating history. From Audrey's humble beginnings to the powerful neural networks of today, each stage of innovation has built upon the last, turning a sci-fi dream into a pocket-sized reality.
Automatic Speech Recognition has officially left the research lab and is now a core part of how countless industries operate. It's the quiet engine powering everything from better customer experiences to greater efficiency. We’re seeing it solve tangible problems everywhere, whether it's helping a doctor streamline their day or making a TV show accessible to a global audience.
This isn't just about convenience anymore; it's a fundamental business tool. Companies are using ASR to finally understand what their customers are saying, healthcare providers are getting precious time back in their day, and media giants are reaching millions of new viewers. Each use case shows just how versatile this technology has become and the direct line it has to improving both productivity and user happiness.
In the world of healthcare, every single minute is critical. For years, doctors and clinicians have been buried under a mountain of administrative work, especially when it comes to typing up clinical notes after seeing a patient. ASR provides a direct solution to this burnout-inducing problem.
Medical dictation software, built on highly accurate ASR models, lets a doctor simply speak their notes. The system captures their observations, diagnosis, and treatment plan, transcribing it directly into the patient's electronic health record (EHR). This isn't just about saving time; it's about capturing more accurate and detailed records because the clinician can document their thoughts the moment they have them. In fact, ASR systems can cut a physician's administrative workload by up to 30%, which means more time focused on patient care. You can dig deeper into these trends in this market research report.
The best part is that modern ASR goes beyond just turning speech into text. It can help structure the notes, pull out key medical terms, and even check for compliance, making the whole documentation process smoother from start to finish.
Contact centers are where companies and customers meet, and ASR is completely changing the game. By transcribing and analyzing calls as they happen, businesses get a crystal-clear window into customer feelings, agent performance, and any brewing problems. This real-time feedback is pure gold for improving service quality.
Here’s what that looks like in practice:
ASR is the backbone of modern customer voice analysis, turning spoken conversations into text data you can actually act on. When you understand what customers are truly saying, you can make smarter decisions about your products and services.
The results are hard to ignore. Many contact centers that adopt speech recognition and analytics see call handling times drop by as much as 40%, which saves money and keeps customers happy.
For the media industry, ASR is the key that unlocks content for a global audience. Think about it: manually creating captions and subtitles for thousands of hours of video is painfully slow and expensive. Automated transcription offers a fast and affordable way to get it done.
This has a few massive benefits:
But it’s not just about captioning. ASR is also used to build searchable archives of broadcast news and other media. This allows journalists, researchers, and creators to instantly find specific clips or mentions buried within years of footage, turning unstructured audio into a valuable, organized asset. In this context, ASR is a tool for universal access and effortless content discovery.

It’s a common misconception that all speech-to-text systems are basically the same. The reality is, they aren't. If you feed the same audio file to two different ASR models, you can get wildly different results. So, how do you tell which one is actually any good?
To pick the right tool for the job, you need a reliable way to measure and compare their performance. Think of it like looking at the spec sheet for a car engine—you need to understand the numbers to know what you’re really getting. Knowing these key metrics helps you cut through the marketing fluff and evaluate an ASR service on hard data.
The single most important metric for judging ASR accuracy is the Word Error Rate, or WER. It has become the industry benchmark for one simple reason: it’s a direct measurement of how many mistakes a system makes when compared to a perfect, human-generated transcript.
In short, a lower WER is always better.
The calculation is pretty straightforward. It adds up all the errors—substitutions, insertions, and deletions—and divides that total by the number of words in the correct transcript. A WER of 5% means the system correctly identifies 95 out of every 100 words. It’s like a golf score: the lower, the better.
Here’s a quick breakdown of those error types:
While a WER of 0% is the ultimate dream, it's not realistic. Even the best ASR models aren't perfect, and things like background noise, heavy accents, or poor microphone quality can make their job much harder.
While WER gets most of the attention, accuracy is only one piece of the puzzle. For many real-world situations, other performance factors are just as crucial for creating a tool that people can actually use. Focusing only on accuracy can lead you to a solution that looks great on paper but fails in practice.
You really have to consider the full picture. A model that’s 99% accurate but takes a minute to produce the text is completely useless for live captioning. Likewise, a fast and accurate system that can’t distinguish between different speakers is of little use in a contact center trying to analyze agent-customer interactions.
Choosing the best ASR solution often comes down to finding the right balance between these different factors. The table below dives into the key metrics you should be looking at and explains why each one matters.
| Metric | What It Measures | Why It Matters |
|---|---|---|
| Latency | The time delay between when words are spoken and when the text appears. | Essential for real-time applications like live captioning, voice commands, and agent assist tools where immediate feedback is required. |
| Speaker Diarization | The ability to identify who spoke and when, assigning labels (e.g., Speaker A, Speaker B). | Critical for transcribing meetings, interviews, and customer service calls to create a readable and understandable conversational record. |
| Robustness | How well the ASR performs in non-ideal conditions, such as noisy environments or with accented speech. | Determines the system's reliability in real-world scenarios, from busy call centers to outdoor field recordings. |
Ultimately, a thorough evaluation requires looking at this entire toolkit of metrics. By understanding WER alongside latency, diarization, and robustness, you can confidently compare different providers like Lemonfox.ai and choose an ASR solution that truly delivers on all fronts.
Alright, so you know what Automatic Speech Recognition is and how to tell if a system is any good. Now comes the hard part: choosing a service that actually fits what you’re trying to build. With so many options out there, it’s easy to get lost in the noise. The secret is to have a clear set of criteria to measure everyone against.
A top-notch ASR solution isn't just about nailing every word. It's about finding the right balance of performance, features, and price. Think of it as a scorecard. The best partner for you will be the one that scores high across the board, giving you a dependable engine for your application.
Before you sign on the dotted line with any provider, you need to put them to the test. These five points are your non-negotiables. They’ll help you figure out if a service can really handle your project, whether you’re building a simple note-taking app or a sophisticated real-time analytics platform.
The goal is to find a provider that confidently checks all these boxes. For a lot of developers and businesses, this search often leads them to solutions built for both peak performance and practical accessibility.
When you run Lemonfox.ai through this checklist, it quickly becomes clear why it's a compelling choice. It was built specifically to deliver state-of-the-art results without the eye-watering price tag that usually comes with high-end ASR.
Let’s see how it stacks up against our criteria:
By blending low latency, extensive language support, and a seriously competitive price, Lemonfox.ai makes powerful speech recognition a realistic option for just about any project you can dream up.
In the end, choosing the right ASR solution is about finding a partner that empowers you to build better products. With its powerful yet straightforward API, Lemonfox.ai bridges the gap between understanding the theory of ASR and actually putting it to work, giving you the tools to create amazing things with voice.
Even after getting a handle on the basics, a few questions about ASR tend to pop up. Let's tackle some of the most common ones to clear things up.
A great way to think about this is to imagine Automatic Speech Recognition (ASR) and Natural Language Processing (NLP) as two different specialists working together.
ASR is the scribe. Its one and only job is to listen to spoken words and write them down as text. Once the audio is converted to a transcript, ASR's work is done.
NLP is the analyst. It picks up where ASR leaves off, taking that raw text and figuring out what it actually means. NLP is the magic that helps a chatbot understand your question's intent or lets a program summarize a long meeting.
In practice, you almost always need both. ASR captures the conversation, and then NLP dives in to find the important insights hidden in the words.
Getting to 100% accuracy is the ultimate goal, but it's a huge mountain to climb. Human speech is just incredibly messy and unpredictable, which throws a few common curveballs at even the best ASR models.
Here are some of the main sticking points:
The future of ASR is all about making voice interactions feel completely invisible and natural. We're moving beyond just writing down words and into systems that can pick up on subtle cues like tone of voice and emotion.
We're already seeing huge strides in speaker identification, where an ASR system can figure out who is talking on the fly, without needing a voice sample ahead of time. Another exciting frontier is multilingual ASR, which can handle conversations where people switch between languages—sometimes even in the same sentence.
As these models get smarter and more efficient, expect to see high-quality ASR built into more of the tools and devices we use every day, making voice an even more central part of how we get things done.
Ready to integrate fast, accurate, and affordable speech-to-text into your application? Lemonfox.ai offers a powerful API that supports over 100 languages with low latency, all for less than $0.17 per hour. Start your free trial today and see the difference.