First month for free!
Get started
Published 12/2/2025
At its heart, speech recognition is a simple idea: it’s the technology that lets a computer understand what you're saying. Think of it as a bridge between the human world of spoken words and the digital world of text and data. This process, also known as Automatic Speech Recognition (or ASR for short), is the magic behind your smart speaker, the voice-to-text on your phone, and countless other tools we now take for granted.
So, how does a machine actually learn to listen? The core challenge is teaching a computer to process the chaotic, nuanced sounds of human speech and accurately convert them into structured, readable text. It’s a lot like a human stenographer who listens intently to every word in a courtroom and types it out verbatim.
This isn't just about convenience; it's about fundamentally changing how we interact with technology. From dictating a quick text message while your hands are full to asking your smart home to dim the lights, ASR is the invisible engine making it all possible. It’s a vital tool for accessibility, a huge boost for productivity, and a key driver of automation across industries.
The journey to get here has been a long one. This technology didn't just appear overnight; it's the result of decades of research and breakthroughs.
The core concepts have been around for a surprisingly long time. A major early milestone came back in 1952 when Bell Laboratories created 'Audrey,' a machine that could recognize spoken digits from a single speaker with over 90% accuracy. Fast forward to the 1960s, and IBM's 'Shoebox' machine was able to understand 16 different English words. For a deeper dive into these early days, you can explore the history of voice recognition and its evolution on ClearlyIP.
That jump from recognizing a few numbers to understanding complex, conversational language shows just how far we've come. What started as a clunky lab experiment has grown into a sophisticated technology that can:
Fueled by modern artificial intelligence and machine learning, today's ASR systems are constantly improving, making our interactions with machines feel more natural and intuitive than ever before.
To really get a handle on how this all works, it helps to break down the key components. These are the building blocks that every ASR system relies on to turn sound into text.
This table gives a quick overview of the essential ideas.
| Concept | Description | Analogy |
|---|---|---|
| Acoustic Model | Maps raw audio signals (the sounds you make) to the basic units of speech, like phonemes. | It's like a phonetic dictionary that helps the system recognize the sound "k" in "cat" versus "c" in "cell." |
| Language Model | Predicts the most likely sequence of words based on context and grammar rules. | This is the grammar expert, guessing that "ice cream" is more likely to be said than "eyes cream." |
| Feature Extraction | Isolates the important characteristics of a sound wave and filters out irrelevant background noise. | Think of it as a sound engineer cleaning up a recording to focus only on the speaker's voice. |
Understanding these three pillars is the first step to appreciating the complexity and power behind any speech recognition tool you use. They work together in a fraction of a second to deliver the accurate transcriptions we rely on.
Ever wonder how a machine makes sense of our spoken words? It's not about "hearing" in the human sense. For a computer, speech is just a messy stream of sound waves. The magic lies in breaking down that audio, analyzing its core components, and reconstructing it as text.
Think of it as a digital detective piecing together clues. It starts with a raw sound file and, through a series of clever steps, ends up with a coherent sentence.
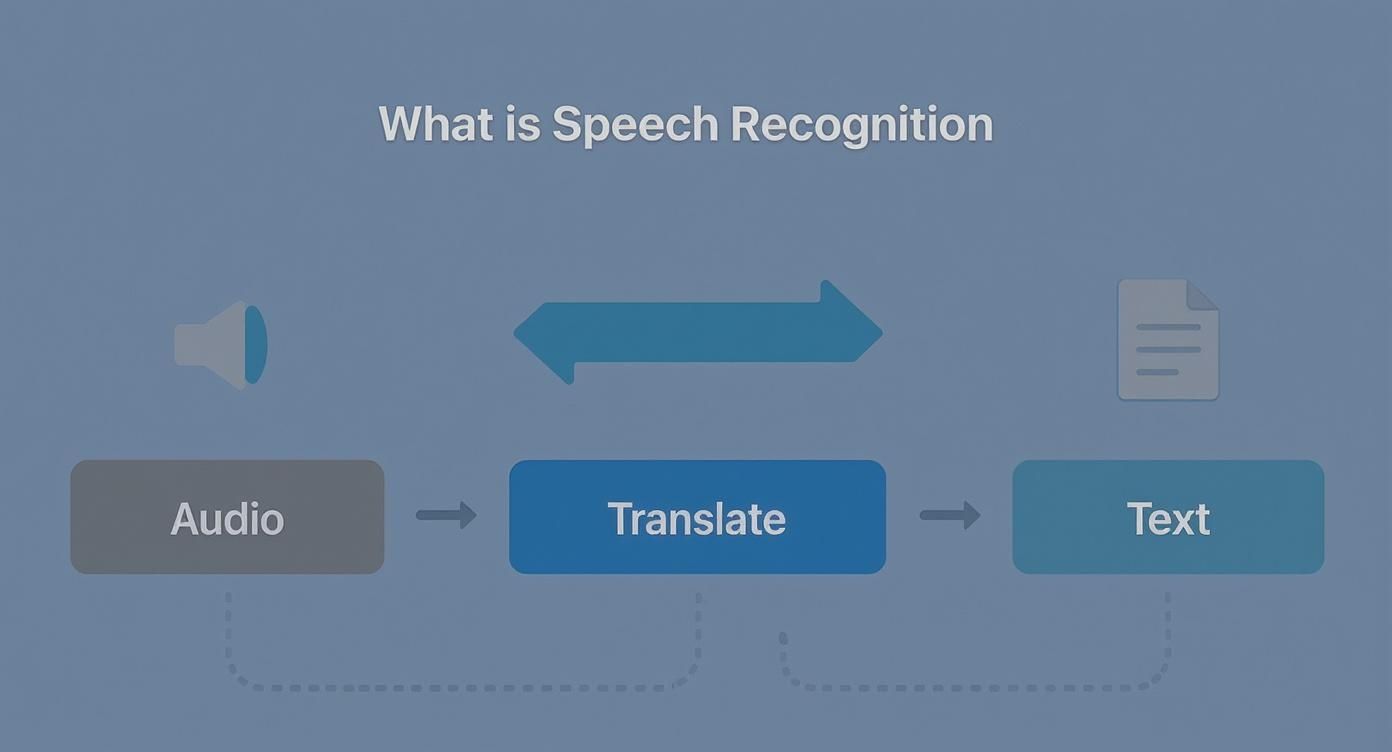
This process might look simple, but under the hood, a few critical things have to happen in perfect sync to get from sound to sentence.
The journey begins with Feature Extraction. A raw audio recording is a jumble of frequencies and background noise. The first job is to cut through the clutter and pinpoint the unique characteristics of human speech. It’s a lot like a sound engineer isolating a specific instrument in a full orchestra.
The system takes the analog sound wave, converts it to a digital format, and then slices it into tiny, millisecond-long segments. For each tiny slice, it extracts the key acoustic features, creating a distinct "sonic fingerprint" that sets one sound apart from another.
With these fingerprints in hand, the system moves on to the Acoustic Model. This is the phonetic specialist. Its entire job is to match those digital sound fingerprints to the fundamental units of speech, called phonemes.
For example, in English, we have about 44 phonemes—like the "k" sound in "cat" or the "sh" in "shoe."
The acoustic model has been trained on thousands of hours of speech, so it's incredibly good at calculating the statistical probability that a certain sound signature matches a specific phoneme. It’s constantly asking, "Given this sound, what's the most likely phoneme being said right now?"
By piecing together these probabilities, the model creates a chain of potential sounds. But a sequence like "ay-s-k-r-ee-m" could mean a few different things without more information. That's where the next step is crucial.
Now, the Language Model takes the stage. Think of this as the grammar and context expert. It examines the string of phonemes suggested by the acoustic model and figures out the most likely sequence of actual words. Having been trained on massive text datasets—books, articles, websites—it knows how words are supposed to fit together.
This model is all about probability. It understands that the phrase "ice cream" is far more common and makes more grammatical sense than "eyes cream." It provides the crucial context needed to transform a string of raw sounds into a meaningful sentence.
Finally, a Decoder pulls everything together. It weighs the evidence from both the acoustic model (the sounds) and the language model (the context) to make a final call. It then generates the most probable text transcription, finishing the entire journey from sound to text in a blink.
For a long time, speech recognition was a clunky beast, relying on complex statistical methods to get the job done. The go-to tech was something called a Hidden Markov Model (HMM). While brilliant for its era, it had some serious blind spots.
Think of an HMM like a detective who only looks at one clue at a time, completely isolated from the rest of the crime scene. It would analyze a tiny slice of audio and then guess the next sound based only on the one that just happened. This was a decent start, but it meant the system had zero grasp of the bigger picture. It struggled with accents, background noise, and the natural flow of a sentence, often getting the words right but fumbling the meaning.
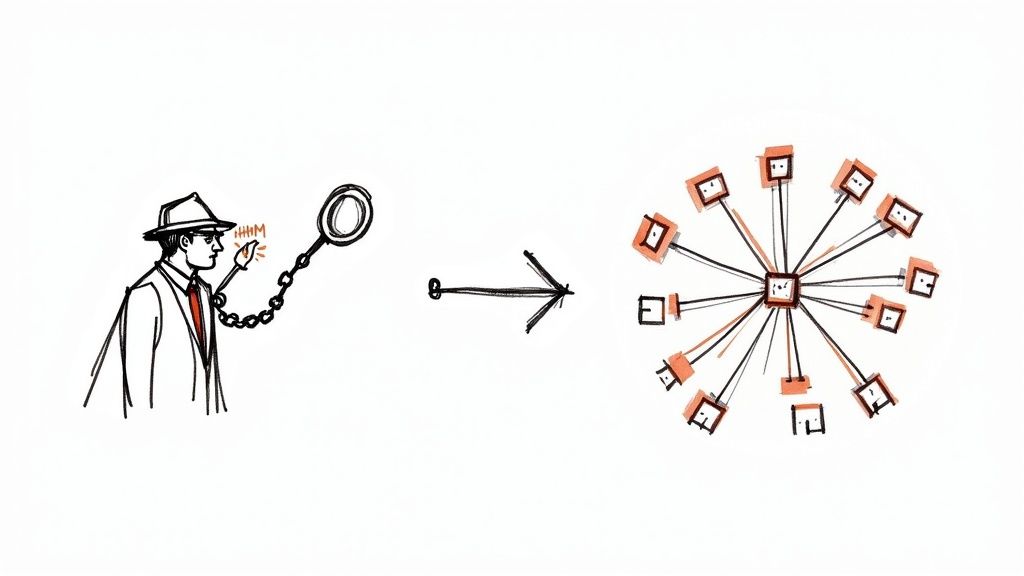
The real turning point came with the rise of deep learning and neural networks. These AI models are built to work more like a human brain, with layers of interconnected nodes that can process information in a much more holistic way. Instead of just looking at the previous sound, they can analyze entire phrases to understand what’s actually being said.
This was a massive leap. Models like Recurrent Neural Networks (RNNs) introduced a kind of short-term memory to the process. An RNN can remember words from earlier in a sentence, which helps it make far more intelligent predictions about what might come next. Suddenly, our detective could see how all the clues on the table related to one another.
Today’s state-of-the-art AI models, especially Transformers, have taken this even further. They don't just process a sentence sequentially; they look at the whole thing at once. This allows them to weigh the importance of every single word in relation to all the others, a concept called "attention." This is how they can nail complex grammar, pick up on sarcasm, and understand nuances that older systems would have completely missed.
You can see the results of this AI-first approach everywhere.
The big shift was from a probabilistic guessing game to a system that actually understands the context and rhythm of human conversation. That's why today’s voice assistants and real-time transcription services feel so seamless.
This AI-driven transformation is what made speech recognition a practical, everyday tool. It’s the engine running in the background when you dictate a text message or ask your smart speaker for the weather, making voice interactions a natural part of our lives.
Not all speech recognition systems are built the same. The magic behind a perfect voice command—and the frustration behind a mangled transcription—often comes down to a fundamental trade-off: speed versus accuracy. Getting this balance right is everything when you're choosing an ASR solution.
Think of a low-latency system as a lightning-fast speed-reader. It flies through the audio, getting the gist of what's said almost instantly. This is perfect for live captions on a news broadcast or for a real-time voice assistant. The goal is immediacy, even if a few words get slightly mixed up along the way.
Now, picture a high-accuracy system as a meticulous editor. It doesn't rush. It pores over every single sound, weighing context and grammar to produce a transcript that’s as close to perfect as possible. This is non-negotiable for things like medical dictation or transcribing legal proceedings, where one wrong word could have massive consequences. A little extra processing time is a small price to pay for precision.
To help you visualize this, here’s a look at how prioritizing one over the other changes things:
This table breaks down the typical give-and-take you'll find when evaluating an ASR solution. Deciding what matters most for your specific use case is the first step toward finding the right fit.
| Factor | High Priority on Speed (Low Latency) | High Priority on Precision (High Accuracy) |
|---|---|---|
| Ideal Use Case | Real-time applications: live captioning, voice commands, conversational AI. | Post-processing tasks: medical transcription, legal depositions, meeting summaries. |
| Response Time | Near-instantaneous (typically under 300ms). | Slower, as the model takes more time to analyze the audio. |
| Computational Cost | Generally lower, as it uses simpler models or processing techniques. | Higher, requiring more powerful hardware and complex algorithms. |
| Error Rate | Word Error Rate (WER) might be slightly higher. | Aims for the lowest possible WER, often below 5%. |
| Model Complexity | Often uses smaller, more streamlined neural networks. | Employs larger, more sophisticated models that understand deeper context. |
Ultimately, the choice isn't about which approach is "better" overall, but which one is better for you. The best systems, like what we're building at Lemonfox.ai, are engineered to give you the best of both worlds—blazing speed without sacrificing the accuracy you need.
Beyond the core engineering trade-offs, the real world has a funny way of interfering with performance. The single biggest factor? The quality of the audio you feed the system. Clear, crisp audio is just plain easier for a machine to understand.
Here are a few common culprits that can trip up even the best ASR models:
Let's clear up a common point of confusion. When we talk about ASR, we're focused on transcribing what someone is saying. But there's a closely related field called speaker recognition that’s all about identifying who is speaking.
Speaker recognition is like a vocal fingerprint. It analyzes the unique acoustic properties of a person's voice—their pitch, cadence, and tone—to figure out who they are. It's the tech that lets you unlock your phone with your voice or helps a smart speaker know which family member is making a request.
So, while both technologies work with the human voice, their jobs are totally different. ASR gives you the script of a conversation. Speaker recognition tells you who played which part.
Many modern platforms, including Lemonfox.ai, can actually do both at the same time. This process, known as speaker diarization, provides a transcript that not only tells you what was said, but also attributes every single word to the correct speaker. It's a game-changer for analyzing meetings, interviews, and multi-participant calls.
Chances are, you use speech recognition every day without even thinking about it. While voice assistants like Siri and Alexa are the most obvious examples, this technology is humming away in the background of countless applications, making our lives easier and our businesses smarter.
It’s the invisible engine powering everything from your car's navigation system to the automatic captions on your favorite videos. It has quietly become a fundamental part of how we interact with the digital world.
In a professional environment, speed and focus are everything. ASR technology is a massive productivity booster, especially in fields where hands-on work is critical. It allows people to capture information naturally—by speaking—without breaking their concentration to type.
Take the healthcare industry, for example. Doctors and nurses now dictate clinical notes directly into electronic health records. This simple change saves hours of administrative time every single week, leading to more accurate documentation and, more importantly, more time spent with patients. Similarly, lawyers can instantly transcribe depositions and client meetings, creating searchable records in a fraction of the time it used to take.
Media companies also lean heavily on ASR. Manually creating captions and subtitles for video content used to be a tedious and costly bottleneck. Now, it’s largely automated, making content immediately accessible to viewers who are deaf or hard of hearing and improving engagement for everyone else.
Beyond the office, speech recognition is key to building better, safer, and more intuitive products. Think about the voice commands in modern cars that let you manage music, maps, and calls without ever taking your hands off the steering wheel. That’s not just about convenience; it’s a huge leap forward for driver safety.
The technology is also making a massive impact on customer service. Businesses can now transcribe and analyze every single support call, unlocking a goldmine of data about what their customers are thinking and feeling.
By automatically converting call audio to text, companies can spot recurring problems, identify frustrated customers, and check if their support agents are meeting quality standards. This data-driven insight is the fastest way to build a better customer experience.
From a cool party trick to a core utility, speech recognition has cemented its place. It helps businesses run more smoothly, makes technology more inclusive, and creates a more natural connection between us and the devices we use every day.
Choosing a speech recognition partner is a big deal. It’s a decision that will ripple through everything from your user experience to your budget. With so many options out there, it's easy to get lost in a sea of marketing promises. The trick is to cut through the noise and focus on what actually matters for your project.
You’ll want to start with the core performance numbers. The industry standard for this is the Word Error Rate (WER), which is just a fancy way of saying "what percentage of words did the system mess up?" But while a low WER is great, it's not the whole picture. You also have to think about latency—how fast do you get the text back? For anything happening in real-time, even a tiny delay of a few hundred milliseconds can make the whole experience feel clunky and awkward.
Beyond just speed and accuracy, there are a few practical things that will make or break your experience. A super-powerful API doesn't do you any good if your developers need a Ph.D. to figure it out. And a confusing pricing structure can spring nasty surprises on you once you start scaling up.
Here’s what you should really be looking at:
Once you’ve made your choice, getting it right is all about the implementation. The single biggest thing you can control is the quality of your audio input. It’s the classic "garbage in, garbage out" problem.
A lot of people underestimate just how much audio quality matters. Simply using a decent microphone and cutting down on background noise can slash your error rate more than switching to a whole new ASR provider.
Finally, remember that no ASR system is ever going to be 100% perfect. Plan for mistakes. Design your app so that users can easily fix a misheard word or confirm a critical command. This kind of thoughtful design creates a smooth experience, even when the tech isn't flawless.
By balancing raw performance with these practical considerations, you can find a speech recognition solution that doesn't just work, but works for you.
As you get started with speech recognition, a few questions always seem to pop up. Let's tackle them head-on to clear up any confusion and give you a better sense of how this technology really works.
People often use these terms interchangeably, but they refer to two completely different tasks. It's a classic "what vs. who" situation.
Speech recognition is all about understanding what you're saying. Its entire job is to convert spoken words into written text. Think of it as a digital stenographer, diligently typing out every word.
Voice recognition, on the other hand, is about identifying who is speaking. It analyzes the unique qualities of a person's voice—their pitch, cadence, and tone—to create a "vocal fingerprint." This is the tech behind biometric security systems that unlock your phone with a voice command.
AI, and specifically deep learning, is the secret sauce that took speech recognition from a clunky, often frustrating tool to the incredibly accurate systems we have today. Before AI, these systems were easily thrown off by accents, background noise, or fast talkers.
Modern AI models are trained on massive amounts of real-world audio data. This allows them to learn the subtle patterns of human language, much like we do. They can now distinguish between homophones (like "to," "too," and "two") based on context, filter out a noisy café, and understand a wide range of accents with impressive accuracy.
It's this deep, contextual understanding that pushed ASR to near-human performance. AI isn't just matching sounds to words; it's learning to comprehend language.
Yes, absolutely. It's a common misconception that you always need an internet connection. While many well-known services are cloud-based, they send your audio to be processed on powerful remote servers.
But that’s not the only way. Many modern ASR systems are built for on-device or edge processing. These are lightweight, efficient models designed to run directly on a smartphone, a car's infotainment system, or an IoT device. This approach offers significant advantages: it's faster, keeps sensitive data private, and works perfectly even when you're completely offline.
Ready to add fast, accurate, and affordable transcription to your application? With Lemonfox.ai, you can get a world-class Speech-to-Text API for less than $0.17 per hour. Start your free trial today and get 30 hours of transcription on us.