First month for free!
Get started
Published 12/25/2025
At its core, speech synthesis is the technology that lets machines talk. You might know it better by its common name, Text-to-Speech (TTS). Think of it as giving a computer a script and having it read the lines back to you, turning plain text into a human-like voice.
Ever had your GPS give you turn-by-turn directions? Listened to an audiobook on your commute? Or asked a smart assistant for the weather? If so, you've experienced speech synthesis firsthand. It's the invisible technology that connects the silent, digital world of text with the audible, human world of sound.
So, what is speech synthesis, really? It's a complex process where software, usually driven by artificial intelligence, analyzes written words and generates the corresponding sound waves that make up human speech. This isn't just about mechanically reading words. Modern systems strive to capture the subtle rhythms, intonations, and inflections that make a voice sound genuinely human.
To create a believable voice, the software first has to understand language much like we do. It starts by breaking text down into its fundamental phonetic components—the distinct units of sound that make up any language.
The journey from text to sound generally follows these steps:
At its heart, speech synthesis is about teaching machines the art of conversation. It's not just about converting characters to sounds; it’s about conveying meaning, emotion, and rhythm through a digitally crafted voice.
This table offers a quick breakdown of the core ideas behind the technology.
| Concept | Description |
|---|---|
| Primary Goal | To artificially generate human-like speech from written text. |
| Common Name | Text-to-Speech (TTS). |
| Input | A string of text (e.g., a sentence, paragraph, or document). |
| Output | An audio file or stream (e.g., MP3, WAV) containing the spoken version of the text. |
| Core Components | Text analysis, phonetic conversion, and audio waveform generation. |
| Key Challenge | Achieving natural-sounding prosody (rhythm, stress, and intonation) instead of a flat, robotic tone. |
| Modern Approach | Primarily uses deep learning and neural networks to model human speech patterns. |
Understanding this process unlocks a world of possibilities for developers and businesses. It's a powerful tool for creating more accessible and engaging applications. Think of automated customer service agents that can speak clearly with customers, or e-learning platforms that provide audio lessons for different learning styles. It’s the foundational technology that gives our digital interactions a voice.
For example, a simple sentence like, "Is this the right way?" requires the system to recognize it's a question and apply a natural-sounding upward inflection at the end. This ability to capture subtle linguistic cues is what separates the stiff, robotic voices of the past from the high-quality, natural audio users have come to expect today.
The natural-sounding AI voices we hear today have a surprisingly long and fascinating history. It’s a story that doesn't start with silicon chips and algorithms, but with gears, bellows, and an old-world curiosity about what makes us human: our ability to speak.
Long before anyone even conceived of a computer, inventors were tinkering with ways to build talking machines. These weren't software programs; they were complex, physical contraptions designed to mechanically replicate the human vocal tract. For their time, they were engineering marvels, and they laid the conceptual groundwork for everything that came next.
One of the most famous early attempts came from a Hungarian inventor named Wolfgang von Kempelen. In 1791, he showed off a speaking machine that used bellows to act as lungs, a reed for vocal cords, and even a soft leather "mouth" to form different sounds. By pumping the bellows and manipulating the parts, he could produce distinct vowels and consonants—basically, he built one of the world's first synthesizers.
These mechanical wonders were incredible, but they had their limits. The real future of speech synthesis wouldn't be in hardware, but in software.
The evolution of speech synthesis is a perfect example of a concept outliving its initial technology. The dream of a talking machine persisted for over 200 years, waiting for the right tools—computers and AI—to finally realize its full potential.
A huge leap forward came in 1968 when Noriko Umeda and her team created the first general English text-to-speech system. This was the moment the technology jumped from the physical to the digital world, proving software could turn text into audible speech without any moving parts. You can read more about the history of text-to-speech technology on Vapi.ai.
For the rest of the 20th century, computer scientists kept chipping away at the problem. The goal was to make the voices less robotic and more understandable, which meant diving deep into linguistic rules and pronunciation.
Then, in 1985, one of the most famous applications of this technology gave a voice to a brilliant mind. A system called KlattTalk, developed by Dennis Klatt, was adapted to become the synthesizer used by the renowned physicist Stephen Hawking.
His iconic, computerized voice became instantly recognizable across the globe. It was a powerful demonstration of how speech synthesis could provide a lifeline for communication and connection. That early voice, while robotic by today's standards, brought a new level of humanity and accessibility to the technology, forever changing how we saw its potential.
This rich history—from Kempelen’s mechanical contraption to Hawking’s distinct digital voice—shows just how far we've come. It’s the foundation upon which today's sophisticated, AI-driven systems are built, as we continue the centuries-old quest to teach machines how to speak.
Ever wonder how an AI voice goes from a string of text to sounding like a real person? It’s not just a simple lookup table of words and sounds. Modern Text-to-Speech (TTS) systems have to learn the very essence of human speech—the rhythm, the pitch, the subtle emotional cues that make a voice believable.
This whole process is generally broken down into two key stages.
First up is text processing, often called the "front-end." This is where the AI acts like an editor, cleaning up the raw text. It figures out that "Dr." should be spoken as "Doctor," understands what to do with numbers and symbols, and then converts everything into a phonetic script. Think of it as the AI reading a screenplay and making pronunciation notes in the margin.
The second stage, waveform generation (the "back-end"), is where the audio comes to life. Using the phonetic script as a guide, the system generates the actual sound waves you hear. Over the years, engineers have come up with a few different ways to do this, each with its own set of pros and cons.
One of the first methods that worked reasonably well was concatenative synthesis. The concept is pretty straightforward: you record a voice actor saying thousands of different sounds, syllables, and words. The system then acts like a sound editor, grabbing these tiny audio snippets and stitching them together to form new sentences.
Because it’s built from real human recordings, the clarity can be excellent. The big problem? It often sounds choppy or disjointed. The rhythm and intonation can feel "off" because the pieces don't always blend together seamlessly, which is why this method is responsible for that classic robotic voice you might remember from older GPS devices.
To get smoother, more controllable speech, developers came up with parametric synthesis. Instead of gluing together raw audio clips, this approach uses a mathematical model of a voice called a vocoder. This model is trained to understand the core components of speech—things like pitch, tone, and volume.
When you feed it text, the system predicts the right parameters and uses the vocoder to generate the sound from this "blueprint." This gives you a ton of control; you can easily make the voice speak faster, slower, or in a higher pitch. The trade-off is that the audio quality often suffered, sounding a bit muffled or "buzzy" because it was a simplified approximation of a real voice.
Today, the state of the art is neural synthesis. This is where things get really interesting. This approach uses deep learning models—the same kind of AI that powers image recognition—to learn how to speak from the ground up.
These models are trained on thousands of hours of high-quality speech, allowing them to absorb the incredibly complex patterns and nuances of a human voice. When they generate speech, they're not just assembling pre-made parts. They are predicting the audio waveform sample by sample, creating a completely new, organic sound. This is the secret behind the stunningly natural and expressive AI voices we hear today.
This timeline gives you a bird's-eye view of how we got from clunky mechanical contraptions to today's sophisticated AI systems.
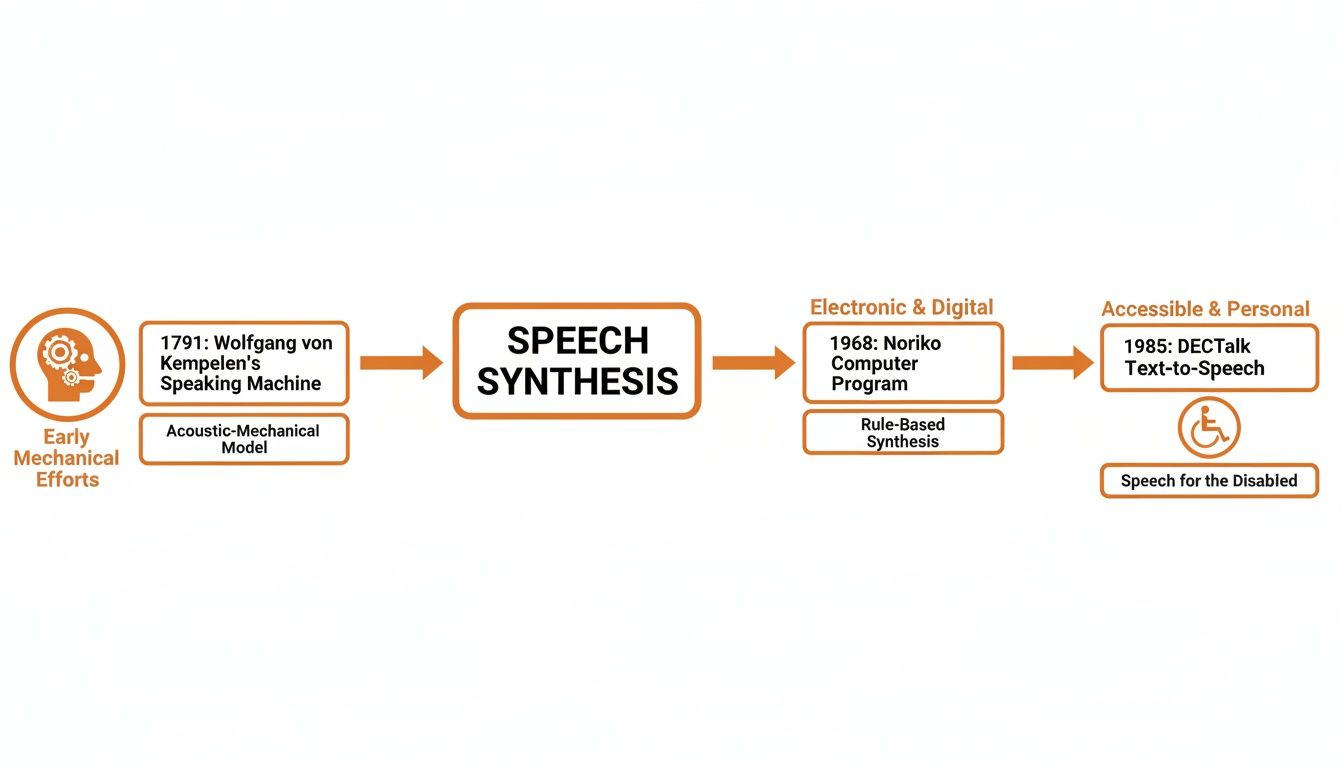
As you can see, the real breakthrough came when we moved from physical devices to computer-based systems, setting the stage for the AI revolution.
The jump to neural synthesis was huge. Instead of hard-coding the rules of speech, we started showing the AI countless examples and letting it figure out the rules for itself. That shift from a rule-based to a learning-based approach is what finally unlocked truly natural-sounding voices.
For those curious about the nuts and bolts of training these models, checking out resources like Parakeet AI's blog for deeper insights can be a great next step.
So, how do these different approaches really stack up against each other? The choice of method involves a classic trade-off between quality, cost, and control. This table breaks down the main differences.
| Method | How It Works | Pros | Cons |
|---|---|---|---|
| Concatenative | Stitches together pre-recorded snippets of a human voice. | High clarity and intelligibility since it uses real audio. | Can sound choppy and unnatural; requires a massive audio database. |
| Parametric | Uses a mathematical model (vocoder) to generate speech from parameters. | Highly controllable (pitch, speed); requires less data than concatenative. | Often sounds muffled, buzzy, or less natural than real recordings. |
| Neural/Deep Learning | A neural network learns to generate audio waveforms directly from text. | Produces the most natural, expressive, and human-like voices. | Computationally intensive to train and run; requires powerful hardware. |
Ultimately, neural synthesis has become the industry standard for a reason—the quality is simply unmatched.
Leading TTS APIs, including what we’ve built here at Lemonfox.ai, rely on neural synthesis to deliver high-fidelity, expressive voices. This approach is what allows us to produce top-tier audio at a cost that makes it accessible for any developer or business.
The technology behind speech synthesis is fascinating, but its real value comes to life when you see what it can do. AI voices are quietly working behind the scenes in countless applications that businesses and developers are building, making information more accessible and creating entirely new ways for us to interact with devices.
These aren't just futuristic ideas. They're practical tools solving real problems right now. Companies are using text-to-speech (TTS) to create better user experiences, cut operational costs, and reach more people. The clunky, robotic voices of the past are gone, replaced by clear, natural-sounding audio that genuinely helps.
One of the most important jobs for speech synthesis is in accessibility. For millions of people with visual impairments, the internet would be a silent, unreadable wall of text without screen reader technology.
These essential tools use TTS to read everything on a screen aloud—website content, navigation menus, emails, you name it. This provides a critical bridge to the digital world, giving users an independence and access to information that many of us take for granted.
It doesn’t stop there. Speech synthesis also helps individuals with reading disabilities like dyslexia by offering an audio alternative to written text. It’s a simple but incredibly powerful way to make digital content more inclusive.
In the customer service world, TTS is the backbone of modern communication. Interactive Voice Response (IVR) systems in call centers rely on AI voices to greet callers, guide them through menus, and provide information like account balances or order statuses, all without tying up a human agent.
This has a huge business impact:
Today's neural TTS makes these interactions feel less like you're talking to a machine and more like a real conversation. A natural-sounding voice can put a caller at ease, turning a potentially frustrating experience into a smooth and efficient one.
The goal of modern TTS in business isn't just to automate tasks—it's to do so in a way that feels human and helpful. A high-quality voice can be the difference between a satisfied customer and a lost one.
The reach of speech synthesis goes far beyond these specific use cases; it's woven into the technology we use every single day.
Think about the in-car navigation systems giving you clear, hands-free directions. They let you keep your eyes on the road, which is a massive win for safety. In the same way, voice assistants like Siri, Alexa, and Google Assistant have made speech synthesis a part of our homes, letting us get weather updates, set timers, and control smart lights just by talking.
Content creators are also getting in on the action. News outlets and blogs are now using TTS to offer audio versions of their articles on the fly. This is perfect for people who want to listen while commuting, working out, or cooking—effectively turning every written article into a mini-podcast.
From empowering users with disabilities to streamlining global business operations, the practical applications of speech synthesis are growing every day. It's evolved from a niche technology into a fundamental tool for building smarter, more accessible, and more engaging digital experiences.
Knowing how speech synthesis works is one thing, but actually putting it into your application is a whole different ballgame. Thankfully, you don't need a team of AI researchers to get started. Modern Text-to-Speech (TTS) services have made integration surprisingly straightforward for developers, typically by using a TTS API.
Think of an API (Application Programming Interface) as a bridge connecting your app to the AI voice engine. You simply send a request across that bridge with your text and a few settings (like which voice to use). The provider's server does all the heavy lifting—processing the text, generating the audio with its complex models—and sends the finished sound file right back to you. This means you get all the power without having to build or maintain the AI yourself.

This simple request-and-response cycle is really all it takes to bring speech synthesis into almost any project.
Most TTS APIs, including what we offer at Lemonfox.ai, follow a pretty standard workflow. While the little details might change from one provider to the next, the core steps are designed to get you from zero to a working voice feature in no time.
Here's what that process usually looks like:
With just a few lines of code, you can add powerful voice features and turn static text into a much more dynamic experience.
Just sending plain text to an API works perfectly for simple tasks. But what happens when you need more control? What if you want the voice to pause for dramatic effect, emphasize a certain word, or spell out an acronym?
That's exactly what Speech Synthesis Markup Language (SSML) is for.
SSML is an XML-based language that gives you incredibly fine-grained control over how the AI turns your text into speech. A good analogy is to think of it as HTML for voice. Just as HTML tags tell a browser how to display text (bold, italic, new paragraph), SSML tags tell a TTS engine how to say it.
With SSML, you stop being just a user of the AI voice and become its director. You can fine-tune the delivery, rhythm, and intonation to get a performance that perfectly matches the context of your application.
Learning just a handful of SSML tags can make a massive difference in the quality and naturalness of your audio output.
You embed these simple tags right inside the text you send to the API. This ability is a standard feature in most high-quality speech synthesis services, giving you the power to shape and direct the AI voice's performance.
Here are a few of the most useful SSML tags you'll encounter:
<speak>: This is the root tag that wraps all your SSML content. It's a signal to the TTS engine that the text inside should be processed as SSML, not plain text.<break>: Need a pause? This is your tag. You can specify its exact length in seconds or milliseconds (e.g., <break time="500ms"/>) for perfect comedic or dramatic timing.<say-as>: This tag gives the engine instructions on how to interpret what it's reading. It’s fantastic for clarifying dates, phone numbers, or acronyms. For example, <say-as interpret-as="characters">API</say-as> tells the voice to spell it out: "A-P-I."<prosody>: This is your go-to tag for controlling the pitch, speaking rate, and volume. You can make the voice speak faster, slower, louder, or in a higher tone for specific words or entire sentences.By mixing and matching these tags, you can transform a flat, robotic reading into a dynamic and engaging piece of audio. Imagine programmatically lowering the pitch and slowing the rate for a serious message, or speeding it up for an excited announcement. That level of control is what creates a truly polished user experience, whether you're building a chatbot, an e-learning course, or an interactive story.
So, you understand how speech synthesis works. The next big question is: which tool should you actually use? Picking the right Text-to-Speech (TTS) service isn't a one-size-fits-all decision. The provider you choose has a real, immediate impact on your app's performance, your budget, and how your users feel about it.
Think of it like choosing a microphone for a recording. You wouldn't use a cheap laptop mic for a professional podcast, and you wouldn't need a high-end studio setup for a quick voice memo. The right TTS API depends entirely on what you're building, from the quality of the voice to the speed of the audio playback.
Let's start with the most obvious factor: how good does the voice actually sound? Does it come across as clear and human, or does it have that tell-tale robotic drone? A great-sounding voice builds trust and keeps people engaged. A bad one can make your whole application feel clunky and cheap.
When you're testing different services, pay close attention to the prosody—that’s the natural rhythm, stress, and intonation of speech. A good TTS system knows to raise its pitch at the end of a question and adds pauses where a human naturally would. It just feels right.
The real goal is for the voice to be so natural that your users don’t even think about it being an AI. It should blend in, not stand out.
This is exactly why at Lemonfox.ai, we've gone all-in on neural synthesis models. They're built from the ground up to produce expressive, clear voices that sound convincingly human.
Latency is just a technical term for the delay between sending your text to the API and getting the audio back. For some jobs, like converting an article to an MP3 for later listening, a few seconds of delay is no big deal.
But for anything happening in real-time? It's a deal-breaker. Think of interactive chatbots, automated call centers, or live feedback in an app. A long, awkward pause after a user speaks can kill the conversation and create a frustrating experience. Always check what a provider's average response times are.
If you're building for a global audience, this one is non-negotiable. Does the service offer the languages and regional accents you need? A localized experience feels more personal and professional, so you’ll want a partner with a deep voice library.
Don't forget to look at the variety of voices, too. Having different genders, ages, and styles lets you pick a voice that truly fits your brand's personality. At Lemonfox.ai, we support over 100 languages to cover these exact needs.
Of course, cost matters. Most TTS providers have a few common ways of charging, and the most popular is pay-as-you-go, where you're billed for the number of characters or seconds of audio you generate. For most people, this is the fairest and most flexible approach.
You'll generally run into these models:
Make sure the model you pick actually fits how much you plan to use the service. For developers and new projects, an affordable pay-as-you-go option like ours at Lemonfox.ai—priced at a fraction of what the big players charge—is a fantastic, low-risk way to get started. When evaluating different platforms and services, consider exploring companies such as LunaBloom AI's offerings for potential speech synthesis solutions.
A powerful API is useless if your developers can't figure out how to use it. Good documentation is everything. Look for clear instructions, code snippets for different programming languages, and a straightforward setup process.
This is where a free trial becomes incredibly valuable. Services like Lemonfox.ai offer one so you can kick the tires, build a quick prototype, and see how everything works in the real world before you ever pull out a credit card.
As you dig into the world of speech synthesis, a few questions always seem to pop up. Let's tackle some of the most common ones to clear up any confusion.
It's easy to mix these two up, but they serve different purposes.
Think of speech synthesis (TTS) like a professional voice actor. You hand them a script—any script—and they read it aloud in their polished, pre-trained voice. It’s a general-purpose tool designed to convert any text into high-quality audio using a set of existing voices.
Voice cloning, on the other hand, is more like creating a vocal "stunt double" for a specific person. It starts with a recording of someone's actual voice and uses that to build a custom model. The goal is to generate new speech that sounds exactly like that individual. So, while both technologies generate audio from text, standard TTS uses a stock voice, and cloning creates a personalized one.
So, what does this technology actually cost? Most APIs operate on a pay-as-you-go model, charging you for the number of characters you convert. This is great because it scales perfectly whether you're a small startup or a massive enterprise.
To give you a ballpark, major cloud providers often charge around $16 per million characters for their best neural voices. But the market is changing. At Lemonfox.ai, we've focused on making top-tier neural voices accessible to everyone, offering them at a much lower price point without sacrificing quality.
The key takeaway is that you don't need a massive budget to access premium voice technology. Modern APIs have made high-quality speech synthesis incredibly affordable.
Yes, absolutely. This is one of the main reasons the technology exists! The vast majority of providers, including Lemonfox.ai, license their voices specifically for commercial use.
This means you can confidently build AI voices into your business apps, marketing content, customer support bots, and any other commercial project. As always, it’s smart to give the provider’s terms of service a quick read, but you’ll find that commercial use is standard practice.
Ready to integrate a powerful, affordable, and natural-sounding voice into your next project? With support for over 100 languages and a simple API, Lemonfox.ai makes it easy. Start your free trial today and experience the quality for yourself.